Downcodes editor reports: In recent years, audio-driven image animation technology has developed rapidly, but existing models still have bottlenecks in terms of efficiency and duration. To solve this problem, researchers have developed a new technology called JoyVASA, which significantly improves the quality and efficiency of audio-driven image animation through an ingenious two-stage design. JoyVASA is not only able to generate longer animated videos, but also supports animal facial animation and shows good multi-language compatibility, bringing new possibilities to the field of animation production.
Recently, researchers have proposed a new technology called JoyVASA, which aims to improve audio-driven image animation effects. With the continuous development of deep learning and diffusion models, audio-driven portrait animation has made significant progress in video quality and lip synchronization accuracy. However, the complexity of existing models increases the efficiency of training and inference, while also limiting the duration and inter-frame continuity of videos.
JoyVASA adopts a two-stage design. The first stage introduces a decoupled facial representation framework to separate dynamic facial expressions from static three-dimensional facial representations.
This separation enables the system to combine any static 3D facial model with dynamic action sequences to generate longer animated videos. In the second phase, the research team trained a diffusion transformer that can generate action sequences directly from audio cues, a process that is independent of character identity. Finally, the generator based on the first-stage training takes the 3D facial representation and the generated action sequence as input to render high-quality animation effects.
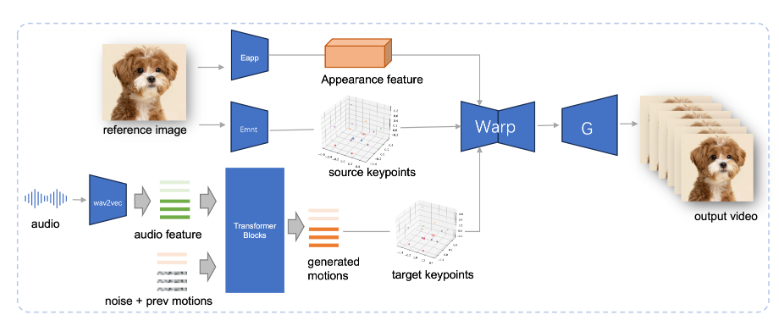
Notably, JoyVASA is not limited to human portrait animation, but can also seamlessly animate animal faces. This model is trained on a mixed data set, combining private Chinese data and public English data, showing good multi-language support capabilities. The experimental results prove the effectiveness of this method. Future research will focus on improving real-time performance and refining expression control to further expand the application of this framework in image animation.
The emergence of JoyVASA marks an important breakthrough in audio-driven animation technology, promoting new possibilities in the field of animation.
Project entrance: https://jdh-algo.github.io/JoyVASA/
The innovation of JoyVASA technology lies in its efficient two-stage design and powerful multi-language support capabilities, which provides a more convenient and efficient solution for animation production. In the future, with the further improvement of technology, JoyVASA is expected to be widely used in more fields, bringing us more realistic and exciting animation works. Looking forward to more technological breakthroughs and leading a new chapter in the development of the animation industry!