The Emu3 team of Zhiyuan Research Institute has released the revolutionary multi-modal model Emu3, which subverts the traditional multi-modal model architecture, trains based only on the next token prediction, and achieves SOTA performance in generation and perception tasks. The Emu3 team cleverly tokenizes images, text, and videos into discrete spaces and trains a single Transformer model on mixed multi-modal sequences, achieving the unification of multi-modal tasks without relying on diffusion or combination architectures, which provides multiple The modal field brings new breakthroughs.
The Emu3 team from Zhiyuan Research Institute has released a new multi-modal model Emu3. This model is trained only based on the next token prediction, subverting the traditional diffusion model and combination model architecture, and achieving results in both generation and perception tasks. state-of-the-art performance.
Next token prediction has long been considered a promising path toward artificial general intelligence (AGI), but it has performed poorly on multi-modal tasks. Currently, the multimodal field is still dominated by diffusion models (such as Stable Diffusion) and combination models (such as the combination of CLIP and LLM). The Emu3 team tokenizes images, text, and videos into discrete spaces and trains a single Transformer model from scratch on mixed multi-modal sequences, thereby unifying multi-modal tasks without relying on diffusion or combinational architectures.
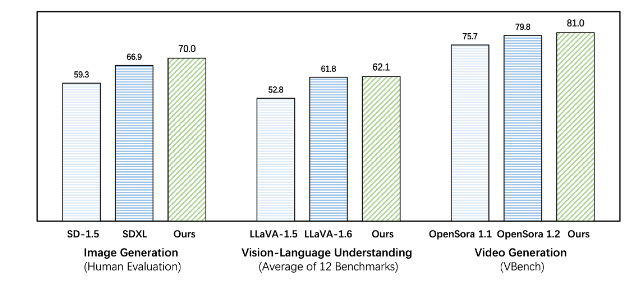
Emu3 outperforms existing task-specific models on both generation and perception tasks, even surpassing flagship models such as SDXL and LLaVA-1.6. Emu3 is also able to generate high-fidelity videos by predicting the next token in a video sequence. Unlike Sora, which uses a video diffusion model to generate videos from noise, Emu3 generates videos in a causal manner by predicting the next token in the video sequence. The model can simulate certain aspects of real-world environments, people, and animals and predict what will happen next given the context of the video.
Emu3 simplifies complex multi-modal model design and focuses the focus on tokens, unlocking huge scaling potential during training and inference. The research results show that next token prediction is an effective way to build general multi-modal intelligence beyond language. To support further research in this area, the Emu3 team has open sourced key technologies and models, including a powerful visual tokenizer that can convert videos and images into discrete tokens, which has not been publicly available before.
The success of Emu3 points out the direction for the future development of multi-modal models and brings new hope for the realization of AGI.
Project address: https://github.com/baaivision/Emu3
Downcodes editor summarizes: The emergence of the Emu3 model marks a new milestone in the multi-modal field. Its simple architecture and powerful performance provide new ideas and directions for future AGI research. The open source strategy also promotes the joint development of academia and industry. It is worth looking forward to more breakthroughs in the future!