Apple's AI research team released a new generation of multi-modal large language model family MM1.5, which can integrate multiple data types such as text and images, and has demonstrated powerful performance in tasks such as visual question answering, image generation and multi-modal data interpretation. ability. MM1.5 overcomes the difficulties of previous multi-modal models in processing text-rich images and fine-grained visual tasks. Through an innovative data-centered approach, it uses high-resolution OCR data and synthetic image descriptions to significantly improve the model's performance. Comprehension. The editor of Downcodes will give you an in-depth understanding of the innovations of MM1.5 and its excellent performance in multiple benchmark tests.
Recently, Apple's AI research team launched their new generation of multi-modal large language models (MLLMs) family - MM1.5. This series of models can combine multiple data types such as text and images, showing us AI's new ability to understand complex tasks. Tasks like visual question answering, image generation, and multimodal data interpretation can all be better solved with the help of these models.
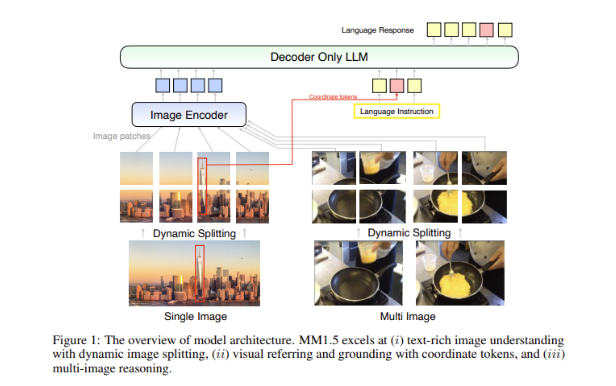
A big challenge in multimodal models is how to achieve effective interaction between different data types. Past models have often struggled with text-rich images or fine-grained vision tasks. Therefore, Apple’s research team introduced an innovative data-centered method into the MM1.5 model, using high-resolution OCR data and synthetic image descriptions to strengthen the model’s understanding capabilities.
This method not only enables MM1.5 to surpass previous models in visual understanding and positioning tasks, but also launches two specialized versions of the model: MM1.5-Video and MM1.5-UI, which are used for video understanding and positioning respectively. Mobile interface analysis.
The training of the MM1.5 model is divided into three main stages.
The first stage is large-scale pre-training, using 2 billion pairs of image and text data, 600 million interleaved image-text documents, and 2 trillion text-only tokens.
The second stage is to further improve the performance of text-enriched image tasks through continuous pre-training of 45 million high-quality OCR data and 7 million synthetic descriptions.
Finally, in the supervised fine-tuning stage, the model is optimized using carefully selected single-image, multi-image, and text-only data to make it better at detailed visual reference and multi-image reasoning.
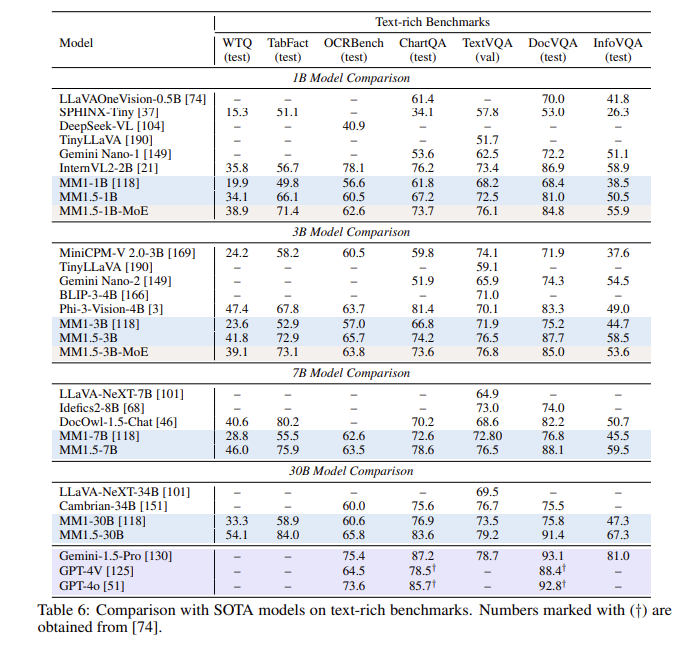
After a series of evaluations, the MM1.5 model performed well in multiple benchmark tests, especially when dealing with text-rich image understanding, with a 1.4-point improvement over the previous model. In addition, even MM1.5-Video, which is specifically designed for video understanding, has reached the leading level in related tasks with its powerful multi-modal capabilities.
The MM1.5 model family not only sets a new benchmark for multi-modal large language models, but also demonstrates its potential in a variety of applications, from general image text understanding to video and user interface analysis, all with outstanding performance .
Highlight:
**Model variants**: Includes dense models and MoE models with parameters from 1 billion to 30 billion, ensuring scalability and flexible deployment.
? **Training Data**: Utilizing 2 billion image-text pairs, 600 million interleaved image-text documents, and 2 trillion text-only tokens.
**Performance improvement**: In a benchmark test focusing on text-rich image understanding, a 1.4-point improvement was achieved compared to the previous model.
All in all, Apple’s MM1.5 model family has made significant progress in the field of multi-modal large language models, and its innovative methods and excellent performance provide a new direction for future AI development. We look forward to MM1.5 showing its potential in more application scenarios.