A research team at Carnegie Mellon University recently released a breakthrough technology - DressRecon, which can reconstruct a time-consistent and detailed 3D model of the human body from monocular video. Different from previous human body reconstruction methods that require tight clothing or multi-view data, DressRecon can handle scenes wearing loose clothing or even holding objects, greatly expanding the scope of applications and bringing innovation to fields such as virtual image creation and animation production. The editor of Downcodes will give you an in-depth understanding of this impressive technology.
Recently, a research team at Carnegie Mellon University released a new technology called "DressRecon" that aims to reconstruct a time-consistent human model from monocular video. The great thing about DressRecon is that not only can you input a video to build a 3D model, but it can also restore fine details such as complex clothing and hand-held items.
This technology is particularly suitable for scenarios where you are wearing loose clothing or interacting with hand-held objects, breaking through the limitations of previous technologies. In the past, human body reconstruction usually required wearing tight-fitting clothing, or required multi-view calibration to capture data, or even personalized scanning, which was difficult to collect on a large scale.
The innovation of "DressRecon" is that it combines general prior knowledge of human body shape and video-specific body deformation, and can be optimized within a video.
The core of this technology is to learn a neural implicit model that can handle the deformation of the body and clothing separately and establish motion model layers separately.
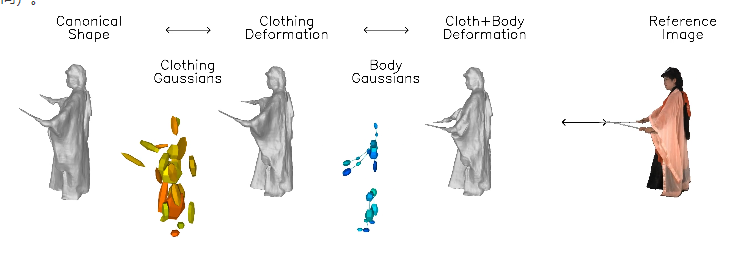
In order to capture the subtle geometric features of clothing, the research team made use of prior knowledge based on images, including human posture, surface normals, and optical flow. This information provides additional support during the optimization process, making the reconstruction effect more realistic.

DressRecon is able to extract high-fidelity 3D models from a single video input, and can even be further optimized into explicit 3D Gaussians to improve rendering quality and support interactive visualization.
The researchers demonstrated the high-fidelity 3D reconstruction effects that DressRecon can achieve on some challenging clothing deformation and object interaction data sets.
In addition, the reconstructed virtual human image can be rendered from any angle, showing a highly visually impactful effect. The team also compared the performance of DressRecon with multiple baseline technologies in shape reconstruction. The results showed that DressRecon showed higher fidelity when processing complex deformed structures.
Project entrance: https://jefftan969.github.io/dressrecon/
Highlight:
? The research team launched DressRecon technology to achieve high-quality human body reconstruction through monocular video, especially suitable for scenes with loose clothing and hand-held objects.
? Utilizing neural implicit models, this technology handles body and clothing deformations separately, and captures subtle geometric features with the help of prior knowledge of image base.
? The reconstruction results can not only generate high-fidelity three-dimensional models, but also support rendering from any angle, improving the visualization experience.
The emergence of DressRecon technology will undoubtedly promote the development of 3D human body modeling technology a big step forward. Its efficient and convenient features, as well as its excellent processing capabilities for complex scenes, bring unlimited possibilities to the fields of virtual reality, animation production, game development and other fields in the future. We look forward to this technology realizing its great potential in more application scenarios!