In the era of information explosion, it is crucial to efficiently process text information in images. The editor of Downcodes will introduce a revolutionary OCR model today - GOT (General Optical Character Recognition Theory), which marks the entry of OCR technology into the 2.0 era. The GOT model combines the advantages of traditional OCR and large language models, and brings new breakthroughs to the field of text recognition with its powerful performance and versatility. It can not only recognize English and Chinese documents and scene texts, but also handle complex information such as mathematical and chemical formulas, music symbols, charts, etc. It can be called an "all-round player" in the field of OCR.
In the digital age, quickly converting text content in images into editable text is a common and important requirement. Now, the advent of a new optical character recognition (OCR) model called GOT (General Optical Character Recognition Theory) marks the entry of OCR technology into the 2.0 era. This innovative model combines the advantages of traditional OCR systems and large-scale language models to create a more efficient and intelligent text recognition tool.
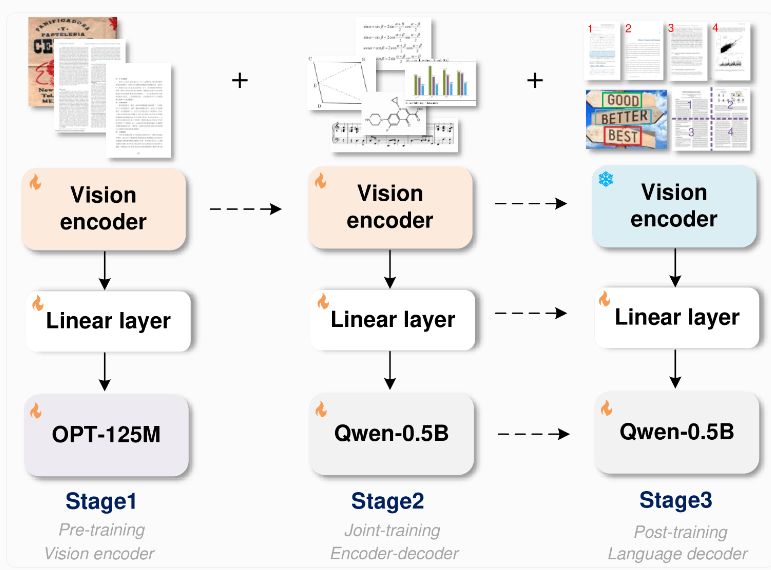
The GOT model adopts an innovative end-to-end architecture. This design not only saves resources, but also greatly expands recognition capabilities beyond text recognition. The model consists of an image encoder with approximately 80 million parameters and a decoder with approximately 5 million parameters. The image encoder is capable of compressing images up to 1024x1024 pixels into data units, while the decoder converts this data into text up to 8000 characters long.
The power of GOT lies in its versatility. It can not only recognize and convert English and Chinese documents and scene texts, but also process mathematical and chemical formulas, music symbols, simple geometric figures and various charts. This makes GOT a true all-rounder.
To train this model, the research team first focused on text recognition tasks, then used Alibaba's Qwen-0.5B as the decoder and fine-tuned it with a variety of synthetic data. They used professional rendering tools such as LaTeX, Mathpix-markdown-it, and Matplotlib to generate millions of image-text pairs for model training.

Another highlight of OCR2.0 technology is its ability to extract formatted text, titles, and even multi-page images and convert them into a structured digital format. This opens up new possibilities for automated processing and analysis in fields such as science, music and data analysis.
In tests of various OCR tasks, GOT has demonstrated excellent performance, achieving industry-leading results in document and scene text recognition, and even surpassing many professional models and large language models in chart recognition. Whether it's complex chemical structure formulas, or musical notation and data visualization, OCR2.0 can accurately capture and convert them into machine-readable formats.
In order to allow more users to experience and utilize this technology, the research team released free demos and code on the Hugging Face platform. The arrival of OCR2.0 has undoubtedly brought a revolution to the field of information processing. It not only improves efficiency, but also increases flexibility, allowing us to process text information in images more easily.
The emergence of the GOT model has undoubtedly injected new vitality into OCR technology. Its efficient, accurate and versatile features will be widely used in all walks of life, bringing more convenience to people's work and life. We look forward to further improving the GOT model in the future and bringing us more surprises!