The editor of Downcodes will take you to learn about a major breakthrough in the field of OCR technology! Researchers have recently developed an OCR model called GOT (General OCR Theory), which is known as "OCR2.0". It cleverly combines the advantages of traditional OCR systems and large language models, and has achieved significant results in text recognition capabilities. progress. The GOT model has a sophisticated architecture, powerful image encoder and decoder, and can process multiple types of visual information. Its application prospects are extremely broad.
Recently, researchers have developed a new universal optical character recognition (OCR) model called GOT (General OCR Theory). In their paper, the concept of "OCR2.0" was first proposed. This new model aims to combine the advantages of traditional OCR systems with the power of large language models.
The architecture of GOT is quite advanced, including an image encoder with approximately 80 million parameters and a decoder with 5 million parameters. The image encoder compresses 1024x1024 pixel images into tokens, and the decoder is responsible for converting these tokens into text of up to 8000 characters. In this way, the OCR2.0 model is able to handle more than simple text.
The beauty of this new technology lies in its ability to recognize and convert many types of visual information , including scene text and document text in English and Chinese, mathematical and chemical formulas, musical symbols, simple geometric figures, and diagrams containing components . Such functionality undoubtedly brings new possibilities for automated processing in fields such as science, music, and data analysis.
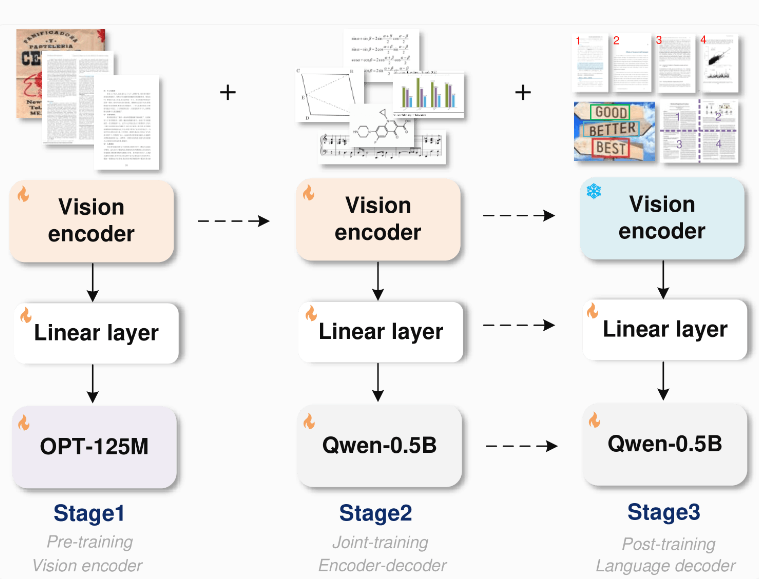
In order to optimize the training process, the research team first trained the encoder only for the text recognition task, then introduced Alibaba's Qwen-0.5B as the decoder, and fine-tuned the model using diverse synthetic data. They generated training data of millions of image and text pairs using rendering tools such as LaTeX, Mathpix-markdown-it, TikZ, Verovio, Matplotlib, and Pyecharts.

The modular design of GOT allows new functions to be flexibly expanded in the future without retraining the entire model. This design greatly improves the update efficiency of the system. In addition, researchers said that GOT performs well in various OCR tasks, especially in document and scene text recognition, and even surpasses some special-purpose models and large language models in chart recognition.

It is worth mentioning that the research team has released the free demo and code of GOT on Hugging Face for others to use and further develop. This new model will undoubtedly promote the development of OCR technology and open up wider application prospects.
Demo entrance: https://huggingface.co/spaces/stepfun-ai/GOT_official_online_demo
Highlight:
? GOT (General OCR Theory) is a new OCR model that combines the traditional OCR system with a large language model, called OCR2.0.
? This model can recognize and convert a variety of visual information, including text, formulas, music symbols and charts, and is applicable to a wide range of fields.
? Modular design and synthetic data training give GOT flexible expansion capabilities and excellent performance in multiple OCR tasks.
The open source release of the GOT model will undoubtedly accelerate the innovation of OCR technology and bring smarter and more efficient text recognition solutions to all walks of life. We look forward to GOT showing greater potential in future applications!