The editor of Downcodes learned that Stability AI has released its latest and most powerful image generation model, Stable Diffusion 3.5. This model is not a single version, but contains three versions to meet the needs of different users, from scientific researchers to enterprise users. can benefit from it. These three versions have different emphasis on parameter quantity, running speed and applicable hardware, providing users with a wider range of choices.
Yesterday evening, Stability AI released its most powerful model - Stable Diffusion 3.5. This is not only a single model, but a family bucket containing three versions, designed to satisfy everyone from scientific researchers to business enthusiasts. Diverse needs of startups and enterprises.
The three versions are Stable Diffusion3.5Large, Stable Diffusion3.5Large Turbo and Stable Diffusion3.5Medium, which will be released on October 29.
Stable Diffusion3.5Large is an 8-billion-parameter base model known for its excellent image quality and cue word accuracy, making it ideal for professional use and capable of producing images with up to 1 megapixel resolution.
Stable Diffusion3.5Large Turbo is a distilled version of the former, which is able to generate high-quality images in only 4 steps, much faster than Stable Diffusion3.5Large.
Stable Diffusion3.5Medium has 2.5 billion parameters, uses an improved MMDiT-X architecture and training method, is designed to be plug-and-play, can run directly on consumer-grade hardware, balances image quality and customizability, and can generate resolution Images with rates between 0.25 and 2 megapixels.
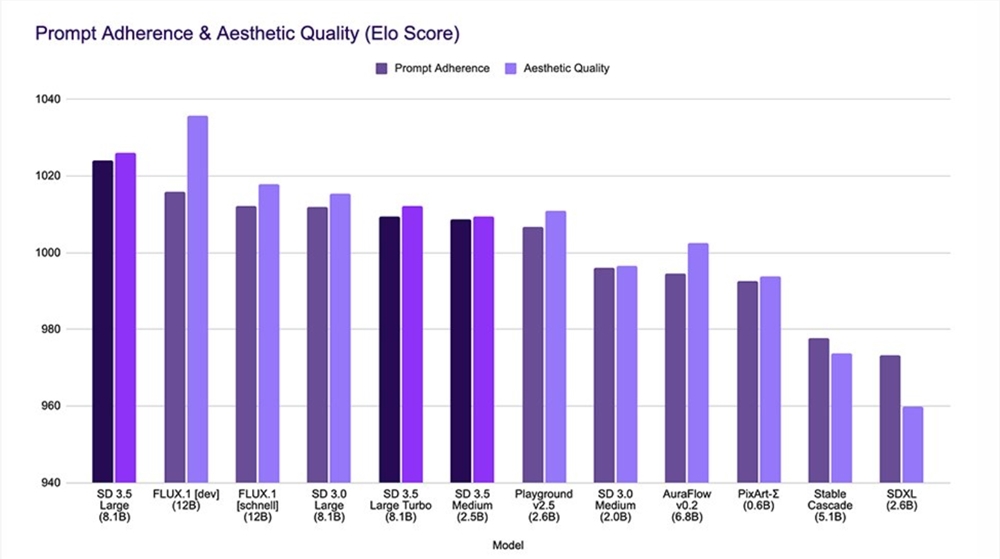
These models were developed with customizability as a priority, by integrating Query-Key Normalization into the transformer block, stabilizing the model training process and simplifying further fine-tuning and development. To support flexibility in downstream tasks, Stability AI retains a broader knowledge base and diverse styles in the model, although this may lead to increased uncertainty in the output results.
The Stable Diffusion3.5 model excels in multiple aspects, including customizability, efficient performance, and diverse output. These models can be easily fine-tuned to meet specific authoring needs or build applications based on customized workflows. They are also optimized to run on standard consumer-grade hardware without excessive hardware requirements. Additionally, these models are capable of creating images that represent the entire world without the need for extensive prompt words, while being able to generate images in a variety of styles and aesthetics such as 3D, photography, painting, line art, and virtually any visual style imaginable.


Stability AI also emphasized its commitment to security, taking reasonable steps to prevent the misuse of Stable Diffusion 3.5 and focusing on integrity from the early stages of development. Additionally, the Stability AI community license is very permissive, allowing individuals and organizations to use the model for free for non-commercial use, including scientific research. The model is also free for commercial use by startups, SMEs and creators with annual revenue of up to $1 million. Ownership of the resulting media remains unaffected by restrictive licenses.
The Stable Diffusion3.5 model is already available for self-hosting on Hugging Face, and the inference code has also been open sourced. In addition, the model can be accessed through platforms such as Stability AI API, Replicate, ComfyUI and DeepInfra.
Experience address: https://huggingface.co/spaces/stabilityai/stable-diffusion-3.5-large
All in all, the Stable Diffusion 3.5 series models have made significant progress in image quality, generation speed and ease of use, providing users with powerful image generation capabilities and flexible application scenarios. The editor of Downcodes recommends all readers to experience it and feel its powerful performance.