The editor of Downcodes learned that a breakthrough study at Yale University revealed the secret of AI model training: data complexity is not higher, the better, but there is an optimal "edge of chaos" state. The research team cleverly used the cellular automaton model to conduct experiments, explored the impact of data of different complexity on the learning effect of the AI model, and came to eye-catching conclusions.
A Yale University research team recently released a groundbreaking research result, revealing a key finding in AI model training: the data with the best AI learning effect is not simpler or more complex, but there is an optimal complexity level - —a state known as the edge of chaos.
The research team conducted experiments by using elementary cellular automata (ECAs), which are simple systems in which the future state of each unit depends only on itself and the states of two adjacent units. Despite the simplicity of the rules, such systems can produce diverse patterns ranging from simple to highly complex. The researchers then evaluated the performance of these language models on reasoning tasks and chess move prediction.
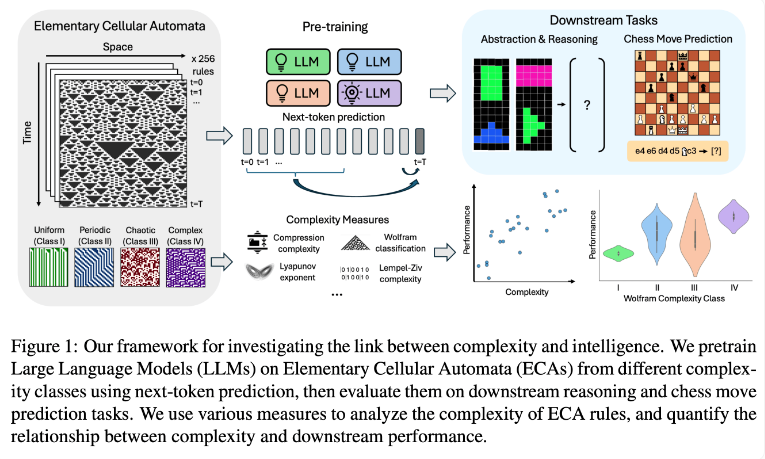
Research results show that AI models trained on more complex ECA rules perform better in subsequent tasks. In particular, models trained on Class IV ECAs in the Wolfram Classification showed the best performance. The patterns generated by such rules are neither completely ordered nor completely chaotic, but rather exhibit a structured complexity.
The researchers found that when models were exposed to patterns that were too simple, they often learned only simple solutions. In contrast, models trained on more complex patterns develop more sophisticated processing capabilities even when simple solutions are available. The research team speculates that the complexity of this learned representation is a key factor in the model's ability to transfer knowledge to other tasks.
This finding may explain why large language models such as GPT-3 and GPT-4 are so efficient. The researchers believe that the massive and diverse data used in training these models may have created effects similar to the complex ECA patterns in their study.
This research provides new ideas for the training of AI models and a new perspective for understanding the powerful capabilities of large language models. In the future, perhaps we can further improve the performance and generalization capabilities of AI models by more precisely controlling the complexity of training data. The editor of Downcodes believes that this research result will have a profound impact on the field of artificial intelligence.