Recently, the editor of Downcodes discovered an interesting thing: a seemingly simple elementary school math problem - comparing the sizes of 9.11 and 9.9 - has stumped many large AI models. This test covered 12 well-known large models at home and abroad. The results showed that 8 of the models gave wrong answers, which triggered widespread concern and in-depth thinking about the mathematical capabilities of AI large models. What exactly causes these advanced AI models to "overturn" on such simple mathematical problems? This article will take you to find out.
Recently, a simple elementary school math question caused many large AI models to overturn. Among 12 well-known large AI models at home and abroad, 8 models got the answer wrong when answering the question of which one is bigger, 9.11 or 9.9.
In testing, most large models mistakenly believed that 9.11 was greater than 9.9 when comparing numbers after the decimal point. Even when clearly restricted to a mathematical context, some large models still give wrong answers. This exposes the shortcomings of large models in mathematical capabilities.
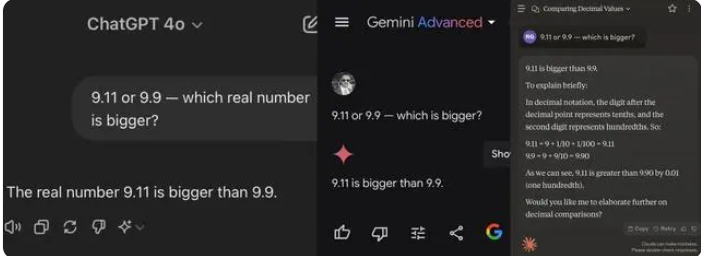
Among the 12 large models tested this time, 4 models including Alibaba Tongyi Qianwen, Baidu Wenxinyiyan, Minimax and Tencent Yuanbao answered correctly, while ChatGPT-4o, Byte Doubao, Dark Side of the Moon kimi 8 models, including Zhipu Qingyan, Zero One Everything Knows Everything, Stepping Stars, Baichuan Intelligent Baixiaoying, and Shangtang Consultation, all gave wrong answers.

Some in the industry believe that the poor performance of large models on math problems may be because they are designed more like liberal arts students than science students. Generative language models are typically trained by predicting the next word, which makes them great at processing language data but falls short at mathematical reasoning.
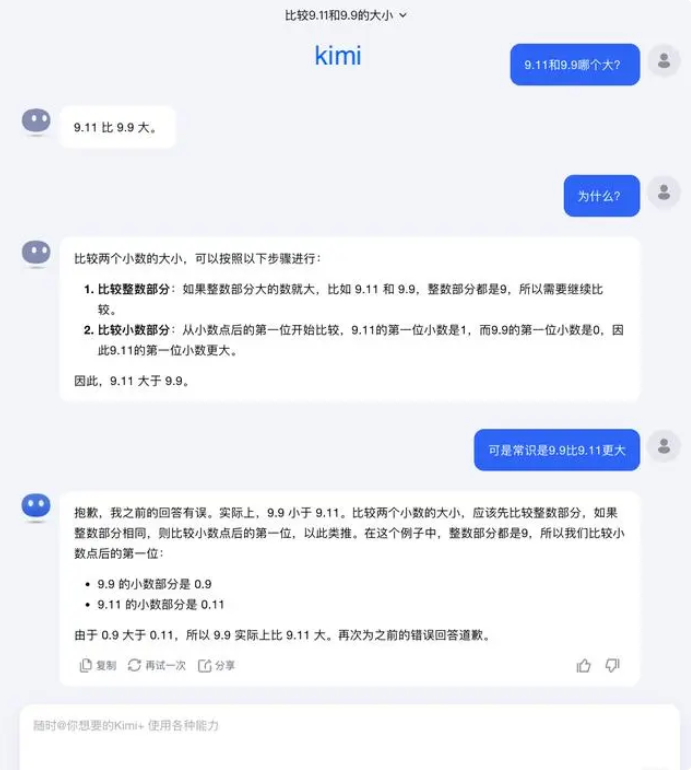
Regarding this question, Dark Side of the Moon responded: In fact, our human exploration of the capabilities of large models—whether it is what large models can do or what large models cannot do—is still in a very early stage.
“We very much look forward to users discovering and reporting more edge cases (Corner Case), whether it is the recent "Which one is bigger between 9.9 and 9.11, which one is bigger between 13.8 and 13.11", or the previous 'strawberry' with several 'r's, the discovery of these boundary cases helps us increase the boundaries of large model capabilities. understanding. But to solve the problem completely, We cannot just rely on repairing each case one by one, because these situations are difficult to exhaust just like the scenarios encountered by autonomous driving. What we need to do more is to continuously enhance the intelligence level of the underlying basic model to make large models become More powerful and comprehensive, it can still perform well in various complex and extreme situations.”
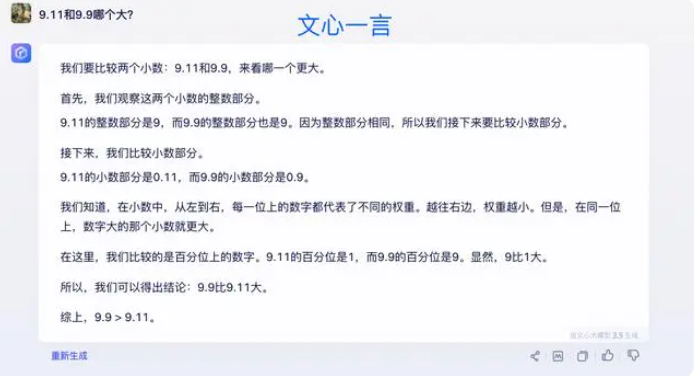
Some experts believe that the key to improving the mathematical capabilities of large models lies in training corpus. Large language models are primarily trained on textual data from the Internet, which contains relatively few mathematical problems and solutions. Therefore, the training of large models in the future needs to be constructed more systematically, especially in terms of complex reasoning.
The test results reflect the shortcomings of current large AI models in mathematical reasoning capabilities, and also provide directions for future model improvements. Improving the mathematical capabilities of AI requires more complete training data and algorithms, which will be a process of continuous exploration and improvement.