Artificial intelligence has made significant progress in image recognition in recent years, but video understanding remains a huge challenge. The dynamics and complexity of video data bring unprecedented difficulty to AI. However, the VideoPrism video encoder developed by the Google research team is expected to change this situation. The editor of Downcodes will give you an in-depth understanding of VideoPrism’s powerful functions, training methods, and its profound impact on the future field of AI video understanding.
In the world of AI, it is much more difficult for machines to understand videos than to understand pictures. The video is dynamic, with sound, movement, and a bunch of complex scenes. In the past, with AI, watching videos was like reading a book from heaven, and you were often confused.
But the emergence of VideoPrism may change everything. This is a video encoder developed by the Google research team. It can reach the state-of-the-art level with a single model on a variety of video understanding tasks. Whether it's classifying videos, positioning them, generating subtitles, or even answering questions about videos, VideoPrism can handle it easily.

How to train VideoPrism?
The process of training VideoPrism is like teaching a child how to observe the world. First, you have to show it a variety of videos, ranging from everyday life to scientific observations. Then, you also train it with some "high-quality" video-subtitle pairs, and some noisy parallel text (such as automatic speech recognition text).
Pre-training method
Data: VideoPrism uses 36 million high-quality video-subtitle pairs and 58.2 million video clips with noisy parallel text.
Model architecture: Based on the standard visual transformer (ViT), using factorized design in space and time.
Training algorithm: includes two stages: video-text comparison training and masked video modeling.
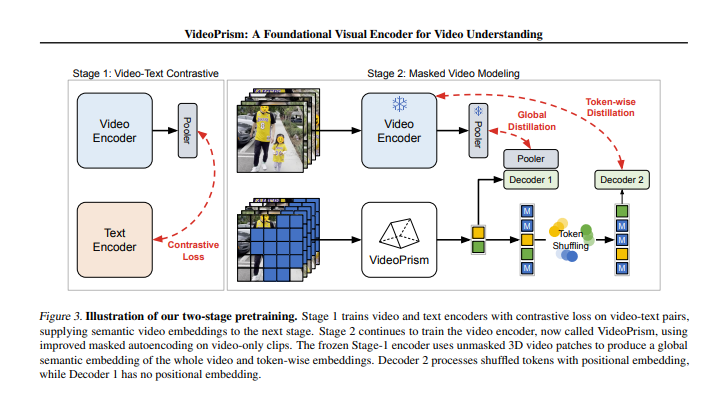
During the training process, VideoPrism will go through two stages. In the first stage, it learns the connection between video and text through contrastive learning and global-local distillation. In the second stage, it further improves the understanding of video content through masked video modeling.
The researchers tested VideoPrism on multiple video understanding tasks, and the results were impressive. VideoPrism achieves state-of-the-art performance on 30 out of 33 benchmarks. Whether it is answering online video questions or computer vision tasks in the scientific field, VideoPrism has demonstrated strong capabilities.
The birth of VideoPrism has brought new possibilities to the field of AI video understanding. Not only can it help AI better understand video content, it may also play an important role in education, entertainment, security and other fields.
But VideoPrism also faces some challenges, such as how to handle long videos and how to avoid introducing bias during the training process. These are issues that need to be addressed in future research.
Paper address: https://arxiv.org/pdf/2402.13217
All in all, the emergence of VideoPrism marks a major progress in the field of AI video understanding. Its powerful performance and wide application prospects are exciting. In the future, with the continuous development of technology, I believe that VideoPrism will show its value in more fields and bring more convenience to people's lives.