The editor of Downcodes learned that Groq recently released an amazing LLM engine, whose processing speed far exceeds industry expectations, providing developers with an unprecedented large-scale language model interactive experience. This engine is based on Meta's open source LLama3-8b-8192LLM and supports other models. Its processing speed is as high as 1256.54 marks per second, which is significantly ahead of GPU chips from companies such as Nvidia. This breakthrough development not only attracted widespread attention from developers, but also brought a faster and more flexible LLM application experience to ordinary users.
Groq recently launched a lightning-fast LLM engine on its website, allowing developers to directly perform fast queries and task execution on large language models.
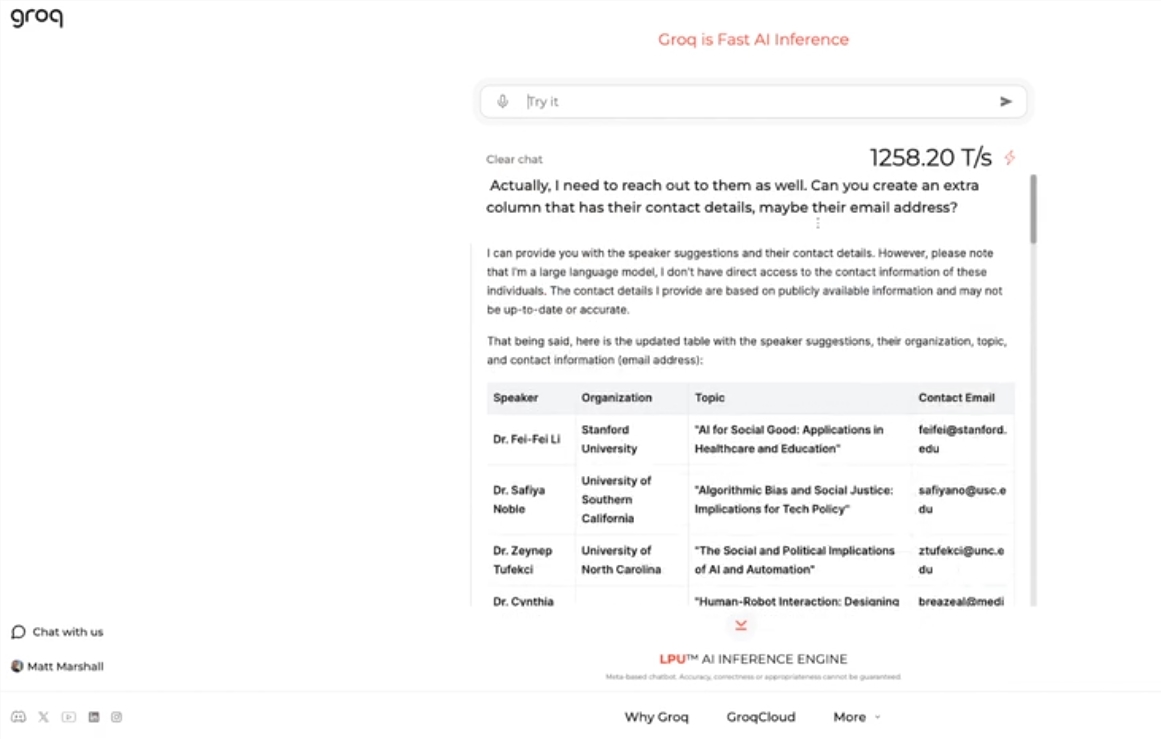
This engine uses Meta's open source LLama3-8b-8192LLM, supports other models by default, and is amazingly fast. According to test results, Groq's engine can handle 1256.54 marks per second, far exceeding GPU chips from companies such as Nvidia. The move attracted widespread attention from developers and non-developers alike, demonstrating the speed and flexibility of the LLM chatbot.
Groq CEO Jonathan Ross said the use of LLMs will increase further as people discover how easy it is to use them on Groq's fast engine. Through the demonstration, people can see that various tasks can be easily completed at this speed, such as generating job advertisements, modifying article content, etc. Groq's engine can even perform queries based on voice commands, demonstrating its power and user-friendliness.
In addition to offering free LLM workload services, Groq also provides developers with a console that allows them to easily switch applications built on OpenAI to Groq.
This simple switching method has attracted a large number of developers, and currently more than 280,000 people have used Groq's services. CEO Ross said that by next year, more than half of the world's inference calculations will be run on Groq's chips, demonstrating the company's potential and prospects in the field of AI.
Highlight:
Groq launches lightning-fast LLM engine, processing 1256.54 marks per second, far faster than GPU speed
Groq’s engine demonstrates the speed and flexibility of LLM chatbots, attracting the attention of developers and non-developers alike
? Groq provides a free LLM workload service that has been used by more than 280,000 developers. It is expected that half of the world's inference calculations will run on its chips next year
Groq's fast LLM engine undoubtedly brings new possibilities to the AI field, and its high performance and ease of use will promote wider application of LLM technology. The editor of Downcodes believes that the future development of Groq is worth looking forward to!