In recent years, the rapid development of artificial intelligence technology relies heavily on the training of massive data. However, the editor of Downcodes found that the latest research from MIT and other institutions pointed out that the difficulty of obtaining data is increasing dramatically. Network data that was once easily available is now subject to increasingly stringent restrictions, which poses huge challenges to the training and development of AI. The study, which analyzed multiple open source datasets, reveals this stark reality.
Behind the rapid development of artificial intelligence, a serious problem is surfacing—the difficulty of data acquisition is increasing. The latest research from MIT and other institutions has found that web data that was once easily accessible is now becoming increasingly difficult to access, which poses a major challenge to AI training and research.
Researchers found that the websites crawled by multiple open source datasets such as C4, RefineWeb, Dolma, etc. are rapidly tightening their license agreements. This not only affects the training of commercial AI models, but also hinders research by academic and non-profit organizations.

This research was conducted by four team leaders from MIT Media Lab, Wellesley College, AI startup Raive and other institutions. They note that data restrictions are proliferating and licensing asymmetries and inconsistencies are becoming increasingly apparent.
The research team used the Robots Exclusion Protocol (REP) and the website’s Terms of Service (ToS) as research methods. They found that even crawlers from large AI companies like OpenAI faced increasingly tight restrictions.
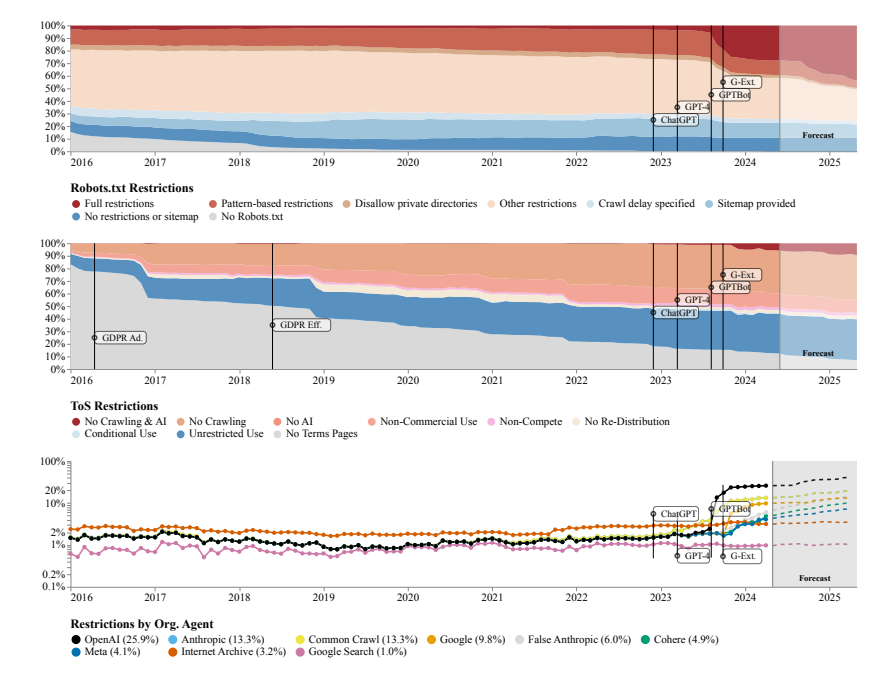
The SARIMA model predicts that in the future, whether through robots.txt or ToS, website data restrictions will continue to increase. This suggests that access to open network data will become more difficult.
The study also found that the data crawled from the Internet is not consistent with the training purpose of the AI model, which may have an impact on model alignment, data collection practices, and copyright.
The research team calls for the need for more flexible agreements that reflect the wishes of website owners, separate permitted and impermissible use cases, and synchronize with terms of service. At the same time, they want AI developers to be able to use data on the open web for training, and hope that future laws will support this.
Paper address: https://www.dataprovenance.org/Consent_in_Crisis.pdf
This research has sounded the alarm on the problem of data acquisition in the field of artificial intelligence, and also raised new challenges for the training and development of future AI models. How to balance data acquisition and the rights and interests of website owners will become a key issue that needs to be seriously considered and solved in the field of artificial intelligence. The editor of Downcodes recommends paying attention to the paper to learn more details.