The field of natural language processing (NLP) is changing with each passing day, and the rapid development of large language models (LLMs) has brought us unprecedented opportunities and challenges. Among them, the dependence of model evaluation on human annotated data is a bottleneck. The high cost and time-consuming data collection work limits the effective evaluation and continuous improvement of the model. The editor of Downcodes will introduce to you a new solution proposed by Meta FAIR researchers - "Self-learning Evaluator", which provides a new idea for solving this problem.
In today's era, the field of natural language processing (NLP) is developing rapidly, and large language models (LLMs) can perform complex language-related tasks with high accuracy, bringing more possibilities to human-computer interaction. However, a significant problem in NLP is the reliance on human annotations for model evaluation.
Human-generated data is critical for model training and validation, but collecting this data is expensive and time-consuming. Moreover, as models continue to improve, previously collected annotations may need to be updated, making them less useful in evaluating new models. This results in the need to continuously acquire new data, posing challenges to the scale and sustainability of effective model evaluation. .
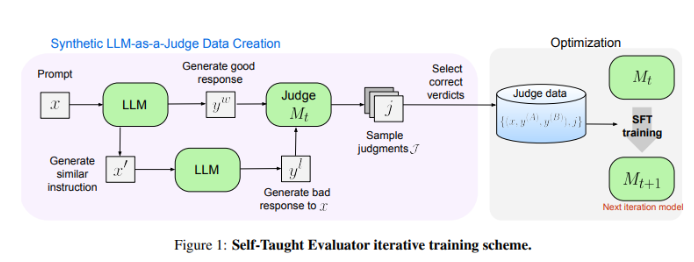
Researchers at Meta FAIR have come up with a new solution - the "Self-Taught Evaluator". This approach does not require human annotations and is trained on synthetically generated data. First, a seed model generates contrasting synthetic preference pairs, and then the model evaluates these pairs and iteratively improves them, using its own judgment to improve performance in subsequent iterations, greatly reducing the reliance on human-generated annotations.
The researchers tested the performance of the "self-learning evaluator" using the Llama-3-70B-Instruct model. This method improves the model's accuracy on the RewardBench benchmark from 75.4 to 88.7, matching or even exceeding the performance of models trained with human annotations. After multiple iterations, the final model achieved an accuracy of 88.3 in a single inference and 88.7 in a majority vote, demonstrating its strong stability and reliability.
The "Self-Learning Evaluator" provides a scalable and efficient solution for NLP model evaluation, leveraging synthetic data and iterative self-improvement, addressing the challenges of relying on human annotations and advancing the development of language models.
Paper address: https://arxiv.org/abs/2408.02666
Meta FAIR's "self-learning evaluator" has brought revolutionary changes to NLP model evaluation, and its efficient and scalable features will effectively promote the continued progress of future language models. This research result not only reduces the dependence on human annotated data, but more importantly paves the way for building more powerful and reliable NLP models. We look forward to more similar innovations in the future!