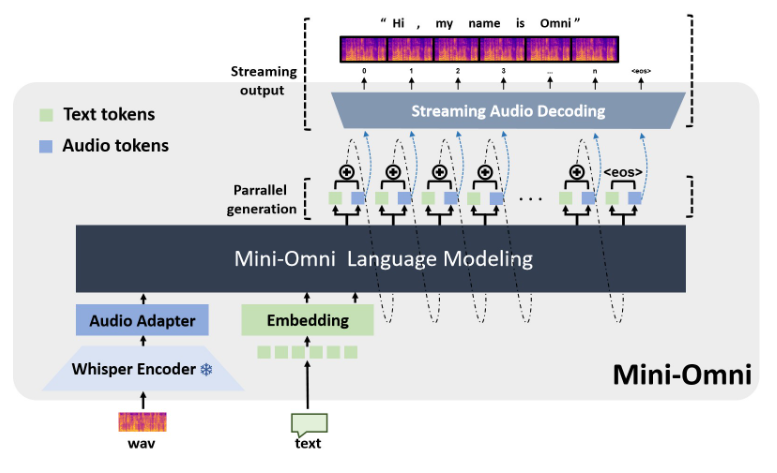
Mini-Omni, an open source multimodal large-scale language model, is revolutionizing voice interaction technology. It integrates advanced technology to realize real-time voice input and output, and has the ability to think and speak at the same time, bringing a more natural and smooth human-computer interaction experience. Mini-Omni's core advantage lies in its end-to-end real-time speech processing capabilities. No additional configuration of ASR or TTS models is required to enjoy smooth conversations. It supports multiple modal inputs and flexibly converts them to adapt to various complex scenarios and meet diverse needs.
Today, with the rapid development of artificial intelligence, an open source multi-modal large-scale language model called Mini-Omni is leading the innovation of voice interaction technology. This AI system integrated with multiple advanced technologies not only enables real-time voice input and output, but also has the unique ability to think and speak at the same time, bringing users an unprecedented natural interaction experience.
Mini-Omni's core advantage lies in its end-to-end real-time voice processing capabilities. Users can enjoy smooth voice conversations without additional configuration of automatic speech recognition (ASR) or text-to-speech (TTS) models. This seamless design greatly improves the user experience and makes human-computer interaction more natural and intuitive.
In addition to the voice function, Mini-Omni also supports input in multiple modes such as text, and can flexibly switch between different modes. This multi-modal processing capability allows the model to adapt to various complex interaction scenarios and meet the diverse needs of users.
Particularly worth mentioning is Mini-Omni’s Any Model Can Talk function. This innovation enables other AI models to easily integrate Mini-Omni’s real-time voice capabilities, greatly expanding the possibilities for AI applications. This not only provides developers with more choices, but also paves the way for the cross-field application of AI technology.
In terms of performance, Mini-Omni shows its comprehensive strength. It not only performs well in traditional speech tasks such as speech recognition (ASR) and speech generation (TTS), but also shows strong potential in multi-modal tasks that require complex reasoning capabilities such as TextQA and SpeechQA. This comprehensive capability enables Mini-Omni to handle a variety of complex interaction scenarios, from simple voice commands to question and answer tasks that require in-depth thinking.
Mini-Omni's technical implementation incorporates multiple advanced AI models and technologies. It uses Qwen2 as the basis of a large language model, uses litGPT for training and inference, uses whisper for audio encoding, and snac is responsible for audio decoding. This multi-technology fusion method not only improves the overall performance of the model, but also enhances its adaptability in different scenarios.
For developers and researchers, Mini-Omni provides convenient use. With simple installation steps, users can launch Mini-Omni in their local environment and conduct interactive demonstrations through tools such as Streamlit and Gradio. This open and easy-to-use feature provides strong support for the popularization and innovative application of AI technology.
Project address: https://github.com/gpt-omni/mini-omni
With its powerful functions, convenient use, and open source features, Mini-Omni brings new possibilities to the field of AI voice interaction and deserves the attention and exploration of developers and researchers. Its future development is also worth looking forward to.