Recently, the open source AI model Reflection70B has attracted widespread attention in the industry due to its performance controversy. The model was released by HyperWrite, which originally claimed it to be the world's most powerful open source model and attracted a lot of attention due to its excellent performance in third-party tests. However, some independent institutions and users subsequently questioned its performance, and test results differed significantly from HyperWrite's initial claims.
The open source AI model Reflection70B, which has just debuted, has recently been widely questioned by the industry.
This model released by New York startup HyperWrite, which claims to be Meta's Llama3.1 variant, has attracted attention due to its excellent performance in third-party tests. However, as some test results were released, Reflection70B's reputation began to be challenged.
The cause of the matter was that HyperWrite co-founder and CEO Matt Shumer announced Reflection70B on social media X on September 6, and confidently called it "the world's strongest open source model."
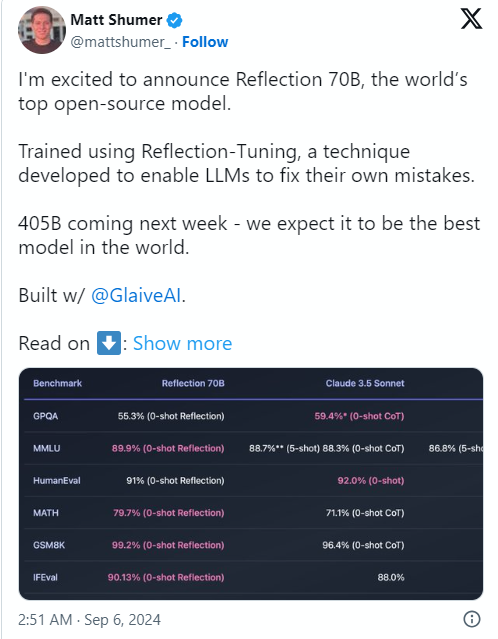
Shumer also shared about the model’s “reflective tuning” technology, claiming that this method allows the model to review itself before generating content, thus improving accuracy.
However, the day after HyperWrite's announcement, Artificial Analysis, a group that specializes in "independent analysis of AI models and hosting providers," published its own analysis on X, noting that they evaluated Reflection Llama3.170B's MMLU (Massive Multitask Language Understanding) score is the same as Llama370B, but significantly lower than Meta's Llama3.170B, which is a significant difference from the results originally published by HyperWrite/Shumer.
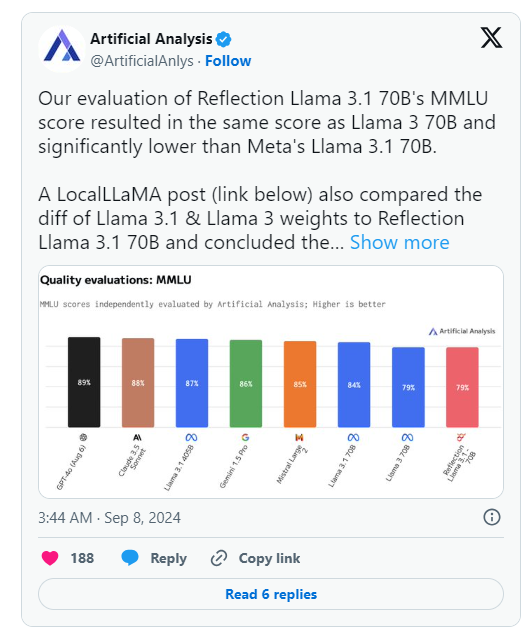
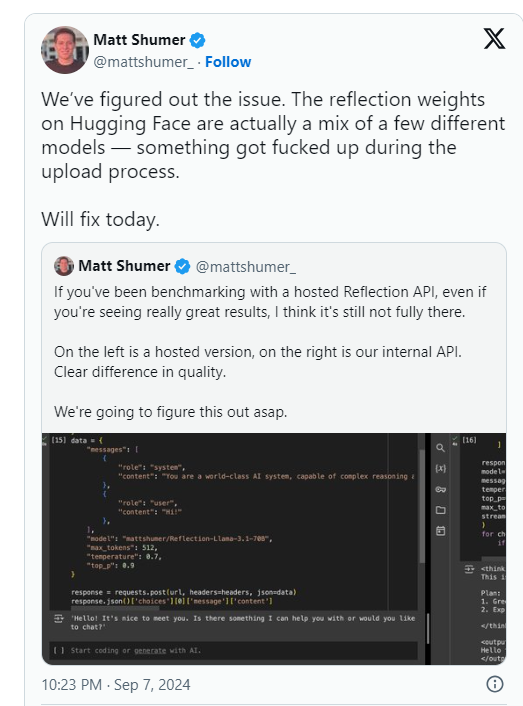
Shumer later stated that there was an issue with Reflection70B's weights (or settings for the open source model) during upload to Hugging Face (a third-party AI code hosting repository and company), which may have resulted in worse performance than HyperWrite's "internal API" version. .
Artificial Analysis said in a subsequent statement that they gained access to the private API and saw impressive performance, but not to the level originally stated. Since this test was conducted on a private API, they were unable to independently verify what they were testing.
The group raised two key issues that seriously question HyperWrite and Shumer's original performance claims:
Meanwhile, users in multiple machine learning and AI communities on Reddit have also questioned Reflection70B’s claimed performance and origins. Some have pointed out that Reflection70B appears to be a variant of Llama3 rather than Llama-3.1 , based on a model comparison posted by a third party on Github, casting further doubt on Shumer and HyperWrite's original claims.
This resulted in at least one X user, Shin Megami Boson, posting on September 8th ET
At 8:07 p.m. EDT, Shumer publicly accused Shumer of “fraudulent conduct” in the AI research community and released a long list of screenshots and other evidence.
Others have alleged that the model is actually a "wrapper" or application built on top of proprietary/closed-source competitor Anthropic's Claude3.
However, other X users have come to the defense of Shumer and the Reflection70B, with some also posting impressive performance on their end of the model.
Currently, the AI research community is awaiting Shumer’s response to these fraud accusations and updated model weights on Hugging Face.
After the release of the Reflection70B model, performance was questioned, with test results failing to replicate initial claims.
⚙️ The founder of HyperWrite explained that model upload problems caused performance degradation and called for attention to the updated version.
The model has been hotly debated on social media, with accusations and defenses mixed in.
At present, the Reflection70B incident is still continuing to ferment, and the final result still needs to await further investigation and response. This incident also reminds us that we should be cautious about the performance promotion of any AI model and rely on independent verification results to make judgments.