Shanghai Artificial Intelligence Laboratory (Shanghai AI Lab) large model data base OpenDatalab team released the new intelligent data extraction tool Mineru at the 2024 WAIC Science Frontier Main Forum. This open source tool aims to simplify the AI data processing process and help researchers to extract high -quality data from massive documents more efficiently. Mineru supports a variety of document formats, including PDF, web pages, EPUB, MOBI, and DOCX, etc., and converts them into Markdown formats that are easy to analyze. Its core functional module Magic-PDF and Magic-Doc focuses on the extraction of PDF documents and webpages/e-books, respectively, and use models such as LayoutlMv3, YOLOV8, Unimern, and PadDleocr to achieve high-quality data extraction, which greatly improves data processing efficiency.
At the Main Forum of WAIC Science in 2024, the OpenDatalab team of Shanghai Artificial Intelligence Laboratory (Shanghai AI Lab) released a new intelligent data extraction tool called MINERU. This tool aims to simplify the AI data processing process and help AI researchers extract high -quality data from massive documents.
Mineru is a omnidirectional, open source document and web data extraction tool that can convert a multi -mode PDF document containing pictures, tables, formulas, etc. into a clear and easy -to -analyze Markdown format. It can also quickly analyze, draw formal content in web pages containing interference information such as advertising, and support batch transformation into Markdown in batches such as EPUB, MOBI, DOCX and other formats.
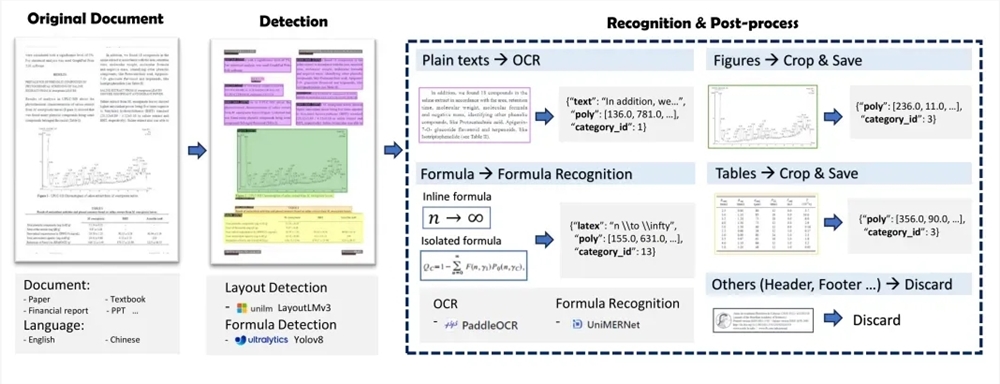
Mineru consists of two main parts: Magic-PDF and Magic-Doc. Magic-PDF focuses on PDF document extraction, converts PDF into a Markdown format, can quickly identify PDF layout elements, and automatically delete the content and format of the original document. Magic-Doc is responsible for webpage and e-book extraction, supporting common articles, forums, music, video and other types of web information extraction, as well as the conversion of e-book format.
At the technical level, Mineru's PDF document extraction process includes PDF document classification preprocessing, model analysis, pipeline processing, and PDF extraction results. It uses a series of models, such as Layoutlmv3, Yolov8, Unimernet, and Paddleocr to achieve high -quality document data extraction.
The release of Mineru not only provides a strong data processing tool for AI researchers, but also further promotes the upgrade of the full -chain tool system for large models of research and development and application.
Demon Mags Community Experience Link:
https://modelscope.cn/studios/opendatalab/mineru
Code open source link:
https://github.com/opendatalab/minereu/
Mineru open source model (PDF-Extract-Kit):
https://modelscope.cn/models/opendatalab/pdf-extract-dit
The open source and ease of use of Mineru will greatly facilitate AI researchers and developers to accelerate the efficiency of data processing in the AI field and provide strong support for the development of large models. Welcome to the link experience and use Minereu.