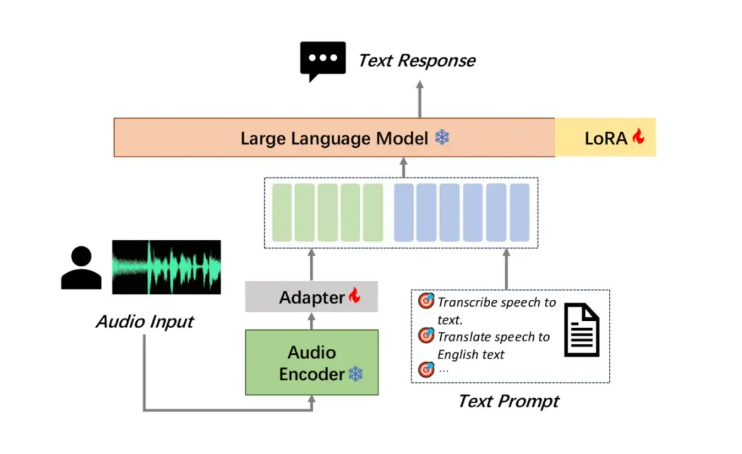
Moore Thread has open sourced its large audio understanding model MooER, which is the industry's first large open source speech model based on domestic full-featured GPU training and inference, which is a milestone. MooER supports Chinese and English speech recognition and Chinese-English phonetic translation, demonstrating powerful multi-language processing capabilities. Its innovative three-part model structure (Encoder, Adapter and Decoder) enables the model to efficiently process audio and perform downstream tasks. At present, the inference code and the model trained based on 5,000 hours of data have been open sourced. In the future, the training code and the enhanced model trained based on 80,000 hours of data will be open sourced, which will greatly promote the development of audio AI technology at home and abroad.
MooER performed well in comparative tests of multiple well-known open source audio understanding large models, with a Chinese word error rate (CER) as low as 4.21% and an English word error rate (WER) of 17.98%, especially BLEU on the Chinese-English translation test set. The score is as high as 25.2, leading other open source models. The MooER-80k model trained based on 80,000 hours of data has stronger performance, with CER and WER reduced to 3.50% and 12.66% respectively, showing great potential. This move by Moore Thread not only demonstrates the strong strength of domestic GPUs in the AI field, but also injects new vitality into the development of global audio AI technology. It is expected that MooER will bring more breakthroughs in the future.
In comparative tests with multiple well-known open source audio understanding large models, MooER-5K performed excellently. In the Chinese test, its word error rate (CER) reached 4.21%; in the English test, its word error rate (WER) was 17.98%, which is better or equivalent to other top models. It is particularly worth mentioning that on the Covost2zh2en Chinese-English translation test set, MooER's BLEU score is as high as 25.2, significantly ahead of other open source models and reaching a level comparable to industrial-level applications.
What is even more exciting is that the MooER-80k model trained based on 80,000 hours of data shows more powerful performance. The CER on the Chinese test set further dropped to 3.50%, and the WER on the English test set was also optimized to 12.66%. Shows huge development potential.
Moore Thread's open source MooER not only demonstrates the application strength of domestic GPUs in the AI field, but also injects new vitality into the development of global audio AI technology. As more training data and codes become open source, the industry expects MooER to bring more breakthroughs in speech recognition, translation and other fields, and promote the popularization and innovative application of audio AI technology.
Address: https://arxiv.org/pdf/2408.05101
The open source of MooER marks that domestic GPUs have made significant progress in the field of AI large models, providing valuable resources and platforms for domestic and foreign developers. It is expected that MooER can play a role in more application scenarios in the future and promote the continuous innovation and development of audio AI technology.