Instruction tuning of large models is the key to improving their performance. Tencent Youtu Labs, in collaboration with Shanghai Jiao Tong University, published a detailed review that provides an in-depth look at the evaluation and selection of instruction tuning datasets. This 10,000-word long article, based on more than 400 related documents, provides comprehensive guidance for instruction tuning of large models from the three dimensions of data quality, diversity, and importance, and points out the challenges of existing research and future prospects. development direction. The article covers a variety of evaluation methods, including hand-designed indicators, model-based indicators, GPT automatic scoring, and manual evaluation, aiming to help researchers select the optimal data set and improve the performance and stability of large models.
With continuous iterative upgrades, large models are becoming smarter, but for them to truly understand our needs, instruction tuning is the key. Experts from Tencent Youtu Lab and Shanghai Jiao Tong University have jointly published a 10,000-word review that deeply discusses the evaluation and selection of instruction tuning data sets, unveiling the mystery of how to improve the performance of large models.
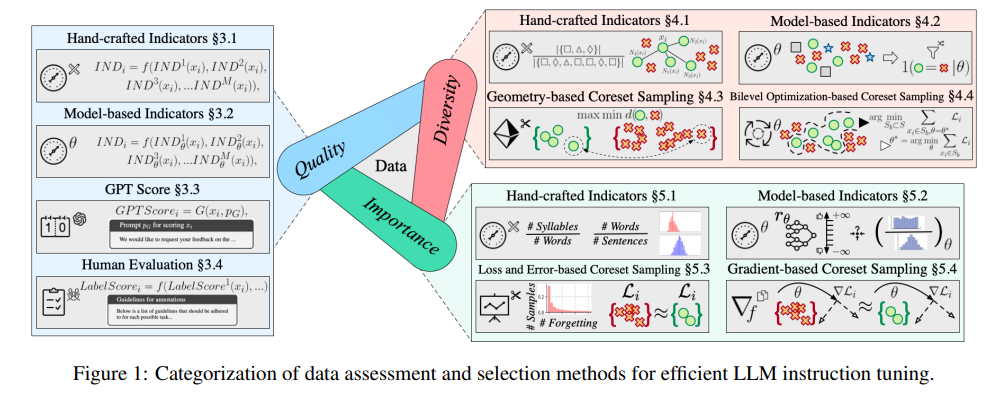
The goal of large models is to master the essence of natural language processing, and instruction tuning is an important step in their learning process. Experts provide an in-depth analysis of how to evaluate and select datasets to ensure that large models perform well across a variety of tasks.
This review is not only astonishing in length, but also covers more than 400 relevant documents, providing us with a detailed guide from the three dimensions of data quality, diversity and importance.
Data quality directly affects the effectiveness of instruction tuning. Experts have proposed a variety of evaluation methods, including hand-designed indicators, model-based indicators, GPT automatic scoring, and indispensable manual evaluation.
Diversity assessment focuses on the richness of the data set, including the diversity of vocabulary, semantics, and overall data distribution. With diverse data sets, models can better generalize to various scenarios.
Importance evaluation is to select the samples that are most critical to model training. This not only improves training efficiency, but also ensures the stability and accuracy of the model when facing complex tasks.
Although current research has achieved certain results, experts also pointed out existing challenges, such as the weak correlation between data selection and model performance, and the lack of unified standards to evaluate the quality of instructions.
Going forward, experts call for the establishment of specialized benchmarks to evaluate instruction tuning models while improving the interpretability of selection pipelines to adapt to different downstream tasks.
This research by Tencent Youtu Lab and Shanghai Jiao Tong University not only provides us with a valuable resource, but also points the direction for the development of large models. As technology continues to advance, we have reason to believe that large models will become more intelligent and better serve humans.
Paper address: https://arxiv.org/pdf/2408.02085
This research provides valuable guidance for large model instruction tuning and lays a solid foundation for future large model development. We look forward to more similar research results in the future, which will promote the continuous progress of large model technology and better serve mankind.