The Anthropic API introduces a long-awaited new feature - hint caching, which will significantly improve the efficiency and economy of Claude models. This feature allows developers to cache frequently used contextual information between API calls, thereby reducing redundant calculations and reducing cost and latency. For application scenarios that need to process large amounts of contextual information, such as conversational agents, coding assistants, and large document processing, hint caching will bring huge performance improvements. This update is currently live in public beta for Claude3.5 Sonnet and Claude3 Haiku, with plans to expand to Claude3 Opus.
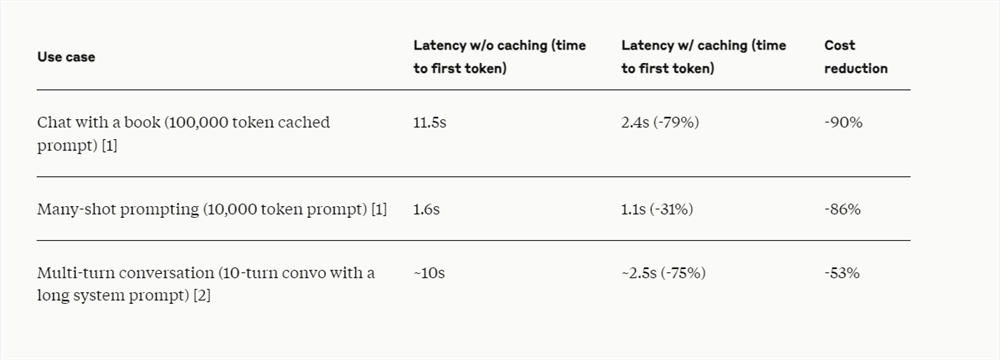
The Anthropic API recently launched prompt caching, so developers can now cache commonly used contextual information between API calls. With hint caching, customers are able to provide Claude models with more background knowledge and example output while significantly reducing the cost of long hints, reducing fees by up to 90% and reducing latency by up to 85%.
This feature is currently available in public beta versions of Claude3.5Sonnet and Claude3Haiku, and will also support Claude3Opus in the future.

The prompt caching feature is particularly useful in scenarios where a large number of prompt contexts need to be referenced repeatedly in multiple requests, such as in conversational proxies to reduce the cost and latency of long conversations, especially when containing complex instructions or document uploads; Coding Assistant Autocomplete and codebase Q&A can be improved by retaining a summarized version of the codebase in the prompt; when working with large documents, the prompt cache enables embedding complete long-form material without increasing response times; additionally, for systems that involve multiple rounds of tool calls and iterations Changed proxy search and tool usage scenarios, prompt caching can also significantly improve performance.
Tip cache pricing depends on the number of input tokens cached and the frequency of use. Writing to the cache costs 25% more than the base input token price, while using cached content costs significantly less, at only 10% of the base input token price.
It is reported that Notion, as a customer of Anthropic API, has integrated the prompt caching function into its artificial intelligence assistant Notion AI. By reducing costs and increasing speed, Notion optimizes internal operations and brings a more advanced, faster experience to users.
The launch of the prompt caching function reflects Anthropic's efforts to optimize the performance of the Claude model and reduce user costs, providing developers with more cost-effective AI solutions and further improving the practicality of the Claude model in various application scenarios. Notion’s success stories also prove the practical value of this feature.