Tencent Youtu Lab and other institutions have open sourced the first multi-modal large language model VITA, which can process videos, images, text and audio at the same time and provide a smooth interactive experience. The emergence of VITA aims to make up for the shortcomings of existing large-scale language models in Chinese dialect processing. Based on the Mixtral8×7B model, the Chinese vocabulary is expanded and bilingual instructions are fine-tuned, making it both proficient in English and fluent in Chinese. This marks significant progress for the open source community in multimodal understanding and interaction.
Recently, researchers from Tencent Youtu Lab and other institutions launched the first open source multi-modal large language model VITA, which can process videos, images, text and audio at the same time, and its interactive experience is also first-class.
The VITA model was born to fill the shortcomings of large language models in processing Chinese dialects. It is based on the powerful Mixtral8×7B model, expanded Chinese vocabulary, and fine-tuned bilingual instructions, making VITA not only proficient in English, but also fluent in Chinese.
Main features:
Multimodal understanding: VITA’s ability to process video, images, text, and audio is unprecedented among open source models.
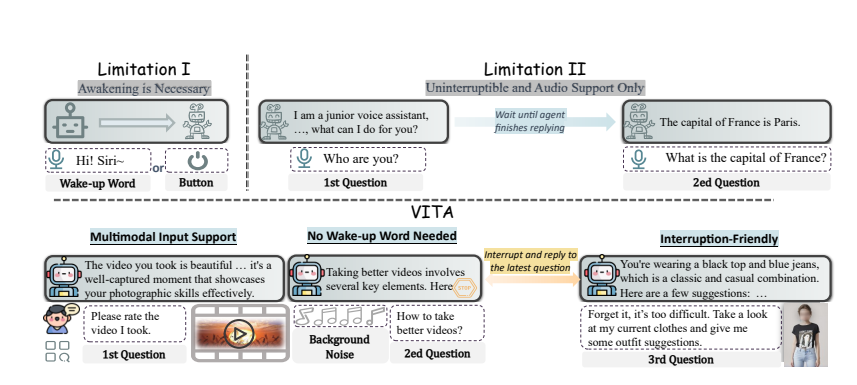
Natural interaction: No need to say "Hey, VITA" every time, it can respond at any time when you speak, and even when you are talking to others, it can remain polite and not interrupt at will.
Open Source Pioneer: VITA is an important step for the open source community in multi-modal understanding and interaction, laying the foundation for subsequent research.
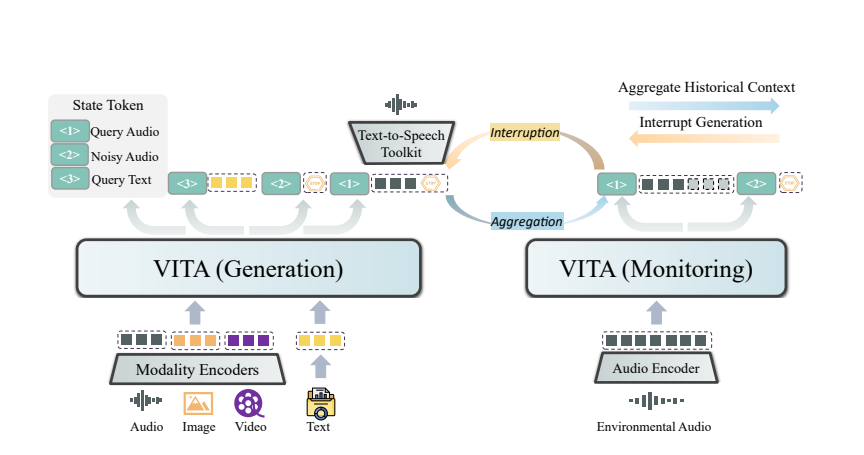
VITA's magic comes from its dual model deployment. One model is responsible for generating responses to user queries, and the other model continuously tracks environmental input to ensure that every interaction is accurate and timely.
VITA can not only chat, but also act as a chat partner when you exercise, and even provide advice when you travel. It can also answer questions based on the pictures or video content you provide, showing its powerful practicality.
Although VITA has shown great potential, it is still evolving in terms of emotional speech synthesis and multi-modal support. The researchers plan to enable the next generation of VITA to generate high-quality audio from video and text input, and even explore the possibility of generating high-quality audio and video simultaneously.
The open source of the VITA model is not only a technical victory, but also a profound innovation in the way of intelligent interaction. With the deepening of research, we have reason to believe that VITA will bring us a smarter and more humane interactive experience.
Paper address: https://arxiv.org/pdf/2408.05211
The open source of VITA provides a new direction for the development of multi-modal large language models. Its powerful functions and convenient interactive experience indicate that human-computer interaction will be more intelligent and humane in the future. We look forward to VITA making greater breakthroughs in the future and bringing more convenience to people’s lives.