Alibaba has launched a new open source speech model Qwen2-Audio, which has significantly improved speech recognition, translation and audio analysis. Its functions and performance surpass the previous generation product Qwen-Audio, and even surpassed it in multiple benchmark tests. OpenAI's Whisper-large-v3. Qwen2-Audio supports multiple languages and provides a basic version and a fine-tuned version with instructions. Users can ask questions through voice and perform audio content recognition and analysis, such as determining the age and emotion of the speaker or analyzing various sound components in the audio. The model uses more natural language prompts for pre-training, significantly improving understanding and response capabilities, and introduces two modes of voice chat and audio analysis to enhance the naturalness of user interaction.
Recently, Alibaba launched a new open source speech model Qwen2-Audio based on its Qwen-Audio. This model not only performs well in speech recognition, translation and audio analysis, but also achieves significant improvements in functionality and performance. Qwen2-Audio provides a basic version and a fine-tuned version of instructions. Users can ask questions to the audio model through voice, and recognize and analyze the content.
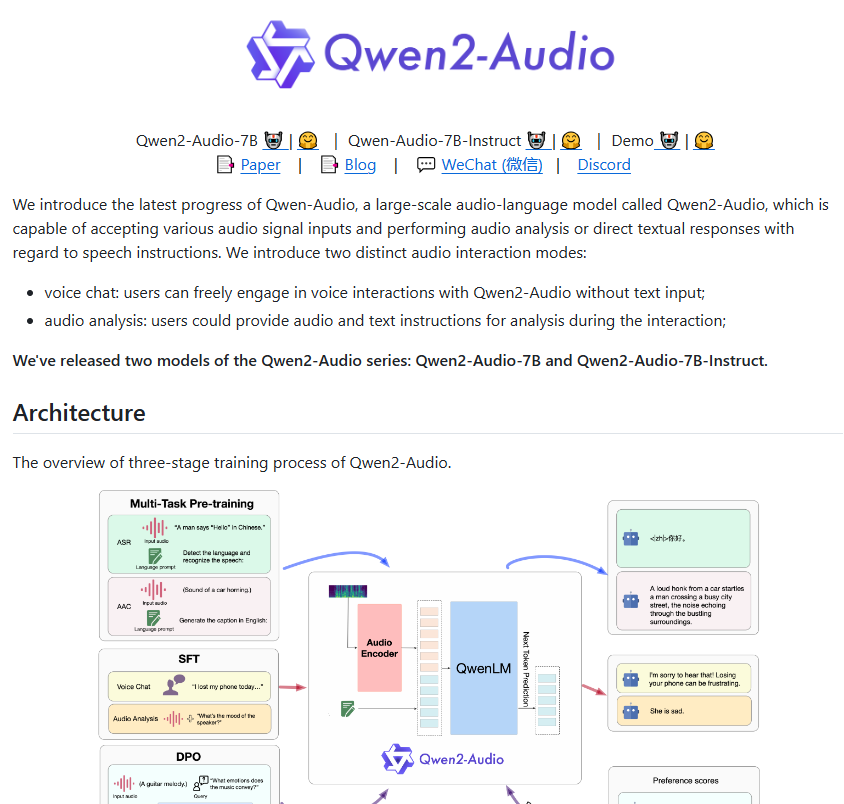
For example, the user can ask a woman to speak, and Qwen2-Audio can determine her age or analyze her emotions; if a noisy sound is input, the model can analyze the various sound components. Qwen2-Audio supports multiple languages including Chinese, Cantonese, French, English and Japanese, which provides great convenience for the development of sentiment analysis and translation applications.
Product entrance: https://top.aibase.com/tool/qwen2-audio
Compared with the first generation Qwen-Audio, Qwen2-Audio has been fully optimized in architecture and performance. In the pre-training stage, this new model uses more natural language cues to replace the previous complex hierarchical labels. This improvement makes the model easier to understand and respond to various tasks, and its generalization ability has also been significantly improved.
Qwen2-Audio's command following ability has also been greatly improved, and it can understand user commands more accurately. For example, when the user issues the command "analyze the emotional tendency in this audio", Qwen2-Audio can accurately determine the emotion contained in the audio. In addition, the model introduces two modes: voice chat and audio analysis, making users' voice interaction more natural. In audio analysis mode, Qwen2-Audio can deeply analyze various types of audio and provide detailed and accurate analysis results.
To ensure that the model's output meets human expectations, Qwen2-Audio also introduces advanced technologies such as supervised fine-tuning and direct preference optimization. Models appear more natural and accurate when interacting with humans.
In terms of performance testing, Qwen2-Audio performed well in multiple mainstream benchmark tests, especially in the accuracy of speech recognition and translation, surpassing OpenAI's Whisper-large-v3. The performance of this new model not only attracted widespread attention in the industry, but also heralded a new future for voice technology.
Highlight:
Qwen2-Audio is Alibaba's latest open source speech model, which supports multiple languages and has powerful recognition and analysis capabilities.
Compared with the previous generation, Qwen2-Audio has been greatly optimized in performance and architecture, improving its ability to understand and respond.
? In multiple performance tests, Qwen2-Audio outperformed OpenAI's Whisper, showing strong competitiveness.
The open source of Qwen2-Audio will promote the development of the voice technology field, provide developers with powerful tools, and promote the birth of more innovative applications. Its advantages in multi-language support and performance make it an important direction for future voice technology development. Looking forward to the application of Qwen2-Audio in more scenarios.