In an era where mobile devices and smart homes are increasingly popular, running large language models (LLM) efficiently has become an urgent need. However, the limited computing resources and memory of edge devices become bottlenecks. This article introduces T-MAC technology, a method based on lookup tables, which can significantly improve the operating efficiency of low-bit LLM on edge devices, bringing more powerful intelligent processing capabilities to smart devices, thereby achieving more convenient and more efficient Smart user experience.
In this era where smart devices are everywhere, we are eager to make mobile phones, tablets, and even smart home devices have more powerful intelligent processing capabilities. However, these edge devices have limited hardware resources, especially memory and computing power, which limits the deployment and running of large language models (LLMs) on them. Imagine how it would change our world if we could equip these devices with powerful models that could understand natural language, answer questions, and even create?
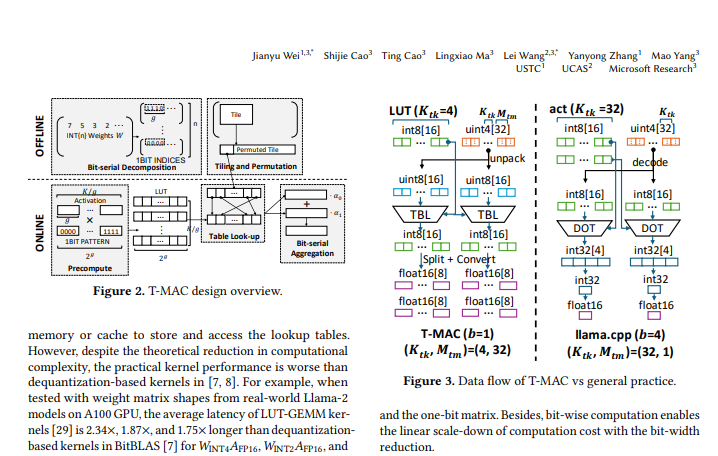
This is the background for the birth of T-MAC technology. T-MAC, the full name of Table-Lookup-based MAC, is a method based on lookup tables, which allows large, low-bit language models to run efficiently on the CPU, thereby achieving intelligent upgrades on edge devices.
Large language models often contain billions or even tens of billions of parameters, which require large amounts of memory to store. In order to deploy these models on edge devices, we need to quantize the weights of the model, that is, use fewer bits to represent the weights, thereby reducing the memory footprint of the model. However, the quantized model requires mixed-precision matrix multiplication (mpGEMM) during operation, which is not common in existing hardware and software systems and lacks efficient support.
The core idea of T-MAC is to transform traditional data type-based multiplication operations into bit-based lookup table (LUT) lookups. This method not only eliminates multiplication operations, but also reduces addition operations, thereby greatly improving operational efficiency.
Specifically, T-MAC is implemented through the following steps:
Decompose the weight matrix into multiple one-bit matrices.
Precompute the product of the activation vector with all possible one-bit patterns and store the results in a lookup table.
During inference, the final matrix multiplication result is quickly obtained through lookup table index and accumulation operations.
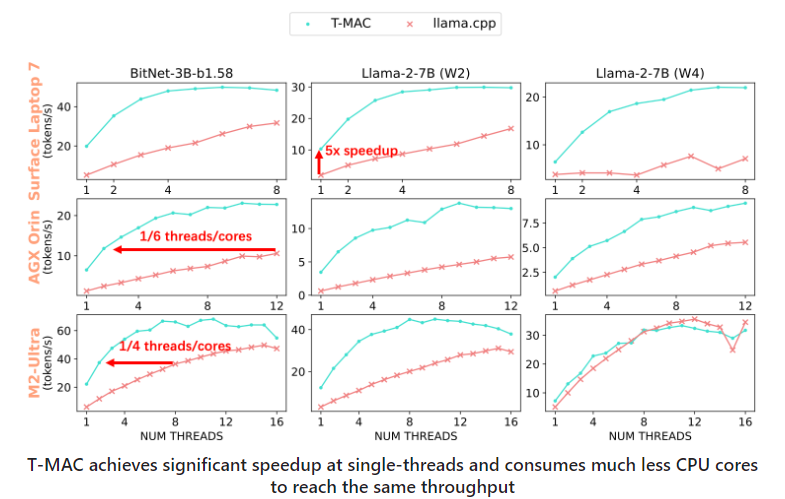
Through testing on a variety of edge devices, T-MAC has shown significant performance advantages. Compared with the existing llama.cpp implementation, T-MAC improves throughput by 4 times and reduces energy consumption by 70%. This allows even low-end devices, such as the Raspberry Pi5, to generate tokens faster than the average adult reading speed.
T-MAC not only has theoretical advantages, it also has the potential for practical applications. Whether it is performing real-time speech recognition and natural language processing on smartphones, or providing a more intelligent interactive experience on smart home devices, T-MAC can play an important role.
T-MAC technology provides an efficient and energy-saving solution for the deployment of low-bit large language models on edge devices. It can not only improve the intelligence level of the device, but also bring users a richer and more convenient intelligent experience. With the continuous development and optimization of technology, we have reason to believe that T-MAC will play an increasingly important role in the field of edge intelligence.
Open source address: https://github.com/microsoft/T-MAC
Paper address: https://www.arxiv.org/pdf/2407.00088
The emergence of T-MAC technology has brought new breakthroughs in the field of edge computing. Its high efficiency and energy saving make it have broad application prospects on various smart devices. I believe that in the future, T-MAC will be further improved and contribute to building a smarter and more convenient world.