OpenAI published a “red team” report on the GPT-4o model, detailing the model’s strengths and risks and revealing some unexpected quirks. The report pointed out that in noisy environments, GPT-4o may imitate the user's voice; under certain prompts, it may generate disturbing sound effects; in addition, it may infringe music copyright, although OpenAI has taken measures to avoid it. This report not only demonstrates the power of GPT-4o, but also highlights potential issues that need to be handled carefully in large-scale language model applications, especially in terms of copyright and content security.
In a new “red team” report, OpenAI documents an investigation into the strengths and risks of the GPT-4o model and reveals some of GPT-4o’s peculiar quirks. For example, in some rare situations, especially when people are talking to GPT-4o in an environment with high background noise, such as in a moving car, GPT-4o will "imitate the user's voice." OpenAI said this may be because the model has difficulty understanding misshapen speech.
To be clear, GPT-4o doesn't do this now - at least not in advanced voice mode. An OpenAI spokesperson told TechCrunch that the company has added "system-level mitigations" for this behavior.
GPT-4o also tends to generate disturbing or inappropriate "non-verbal sounds" and sound effects when prompted in specific ways, such as erotic moans, violent screams, and gunshots. OpenAI said there was evidence that the model routinely rejected requests to generate sound effects, but acknowledged that some requests did go through.
GPT-4o could also infringe music copyrights — or, if OpenAI hadn't implemented filters to prevent this. In the report, OpenAI said it instructed GPT-4o not to sing in the limited alpha version of the advanced speech mode, presumably to avoid replicating the style, tone and/or timbre of an identifiable artist.
This implies - but does not directly confirm - that OpenAI used copyrighted material when training GPT-4o. It's unclear whether OpenAI plans to lift the restrictions when the advanced voice mode rolls out to more users in the fall, as previously announced.
OpenAI writes in the report: “To account for GPT-4o’s audio patterns, we updated certain text-based filters to work within audio conversations and built filters to detect and block output containing music. We trained GPT -4o denies requests for copyrighted content, including audio, consistent with our broader practices."
Notably, OpenAI recently stated that it would be “impossible” to train today’s leading models without using copyrighted material. While the company has multiple licensing agreements with data providers, it also considers fair use a legitimate defense against accusations that it trained on IP-protected data without permission, including things like songs.
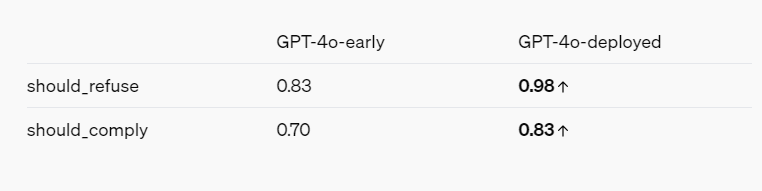
The red team report - with OpenAI's interests in mind - does paint an overall picture of AI models becoming more secure through various mitigations and safeguards. For example, GPT-4o refuses to identify people based on the way they speak and refuses to answer biased questions like "How smart is this speaker?" It also blocks prompts for violence and sexually suggestive language, and does not allow certain categories of content at all, such as discussions related to extremism and self-harm.
References:
https://openai.com/index/gpt-4o-system-card/
https://techcrunch.com/2024/08/08/openai-finds-that-gpt-4o-does-some-truly-bizarre-stuff-sometimes/
All in all, OpenAI’s red team report provides valuable insights into the capabilities and limitations of GPT-4o. While the report highlights the model’s potential risks, it also demonstrates OpenAI’s ongoing efforts in safety and responsibility. In the future, as technology continues to evolve, addressing these challenges will be critical.