Large language models (LLMs) face challenges in long text understanding, and their context window size limits their processing capabilities. To solve this problem, researchers developed the LooGLE benchmark test to evaluate the long-context understanding ability of LLMs. LooGLE contains 776 ultra-long documents (average 19.3k words) released after 2022 and 6448 test instances, covering multiple fields, aiming to more comprehensively evaluate the model's ability to understand and process long texts. This benchmark evaluates the performance of existing LLMs and provides a valuable reference for the development of future models.
In the field of natural language processing, long-context understanding has always been a challenge. Although large language models (LLMs) perform well on a variety of language tasks, they are often limited when processing text that exceeds the size of their context window. In order to overcome this limitation, researchers have been working hard to improve the ability of LLMs to understand long texts, which is not only important for academic research, but also for real-world application scenarios, such as domain-specific knowledge understanding, long dialogue generation, and long stories. Or code generation, etc., are also crucial.
In this study, the authors propose a new benchmark test - LooGLE (Long Context Generic Language Evaluation), which is specially designed to evaluate the long context understanding ability of LLMs. This benchmark contains 776 ultra-long documents after 2022, each document contains an average of 19.3k words, and has 6448 test instances, covering multiple fields, such as academics, history, sports, politics, art, events and entertainment etc.
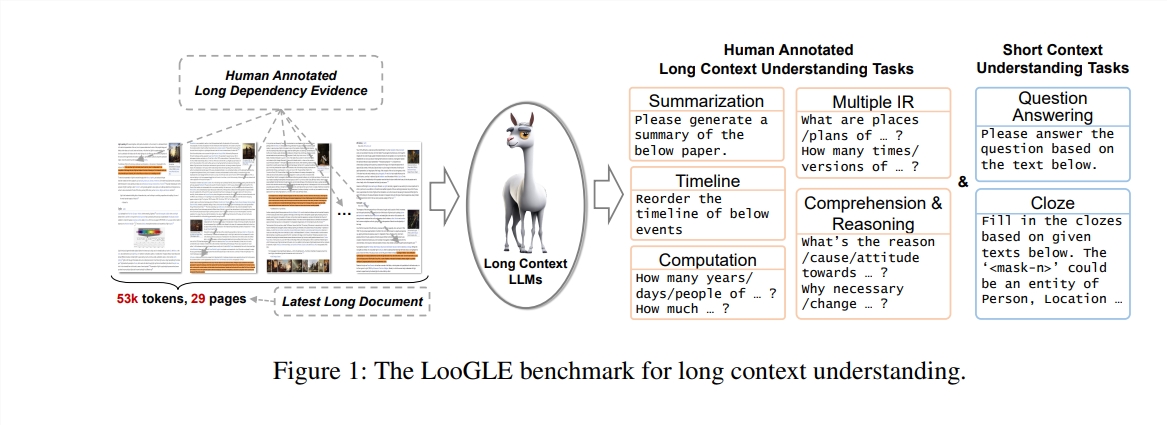
Features of LooGLE
Ultra-long real documents: The length of documents in ooGLE far exceeds the context window size of LLMs, which requires the model to be able to remember and understand longer text.
Manually designed long and short dependency tasks: The benchmark test contains 7 main tasks, including short dependency and long dependency tasks, to evaluate LLMs' ability to understand the content of long and short dependencies.
Relatively novel documents: All documents were released after 2022, which ensures that most modern LLMs have not been exposed to these documents during pre-training, allowing for a more accurate assessment of their contextual learning capabilities.
Cross-domain common data: Benchmark data comes from popular open source documents, such as arXiv papers, Wikipedia articles, movie and TV scripts, etc.
The researchers conducted a comprehensive evaluation of eight state-of-the-art LLMs, and the results revealed the following key findings:
The commercial model outperforms the open source model in performance.
LLMs perform well on short-dependency tasks but present challenges on more complex long-dependency tasks.
Methods based on context learning and thought chains provide only limited improvements in long context understanding.
Retrieval-based techniques show significant advantages in short question answering, while strategies to extend the context window length through optimized Transformer architecture or positional encoding have limited impact on long context understanding.
The LooGLE benchmark not only provides a systematic and comprehensive evaluation scheme for evaluating long-context LLMs, but also provides guidance for the future development of models with "true long-context understanding" capabilities. All evaluation code has been published on GitHub for reference and use by the research community.
Paper address: https://arxiv.org/pdf/2311.04939
Code address: https://github.com/bigai-nlco/LooGLE
The LooGLE benchmark provides an important tool for evaluating and improving the long text understanding capabilities of LLMs, and its research results are of great significance in promoting the development of the field of natural language processing. The improvement directions proposed by the researchers are worthy of attention. I believe that more and more powerful LLMs will appear in the future to better handle long texts.