Apple and Meta AI jointly launched a new technology called LazyLLM, which is designed to significantly improve the efficiency of large language models (LLM) in processing long text reasoning. When the current LLM processes long prompts, the computational complexity of the attention mechanism increases with the square of the number of tokens, resulting in slow speed, especially in the pre-charging stage. LazyLLM dynamically selects important tokens for calculation, effectively reducing the amount of calculations, and introduces the Aux Cache mechanism to efficiently restore pruned tokens, thus greatly increasing the speed while ensuring accuracy.
Recently, Apple's research team and Meta AI researchers jointly launched a new technology called LazyLLM, which improves the efficiency of large language models (LLM) in long text reasoning.
As we all know, the current LLM often faces slow speed problems when processing long prompts, especially during the pre-charge stage. This is mainly because the computational complexity of modern transformer architectures when calculating attention grows quadratically with the number of tokens in the hint. Therefore, when using the Llama2 model, the calculation time of the first token is often 21 times that of subsequent decoding steps, accounting for 23% of the generation time.
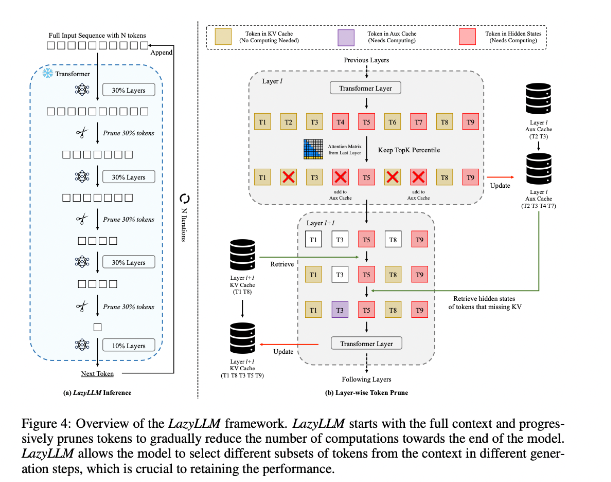
In order to improve this situation, researchers proposed LazyLLM, which is a new method to accelerate LLM inference by dynamically selecting the calculation method of important tokens. The core of LazyLLM is that it evaluates the importance of each token based on the attention score of the previous layer, thereby gradually reducing the amount of calculation. Unlike permanent compression, LazyLLM can restore pruned tokens when necessary to ensure model accuracy. In addition, LazyLLM introduces a mechanism called Aux Cache, which can store the implicit state of pruned tokens to efficiently restore these tokens and prevent performance degradation.
LazyLLM excels in inference speed, especially in the pre-filling and decoding stages. The three main advantages of this technique are that it is compatible with any transformer-based LLM, does not require model retraining during implementation, and performs very effectively on a variety of language tasks. LazyLLM's dynamic pruning strategy allows it to significantly reduce the amount of calculation while retaining most important tokens, thereby increasing the generation speed.
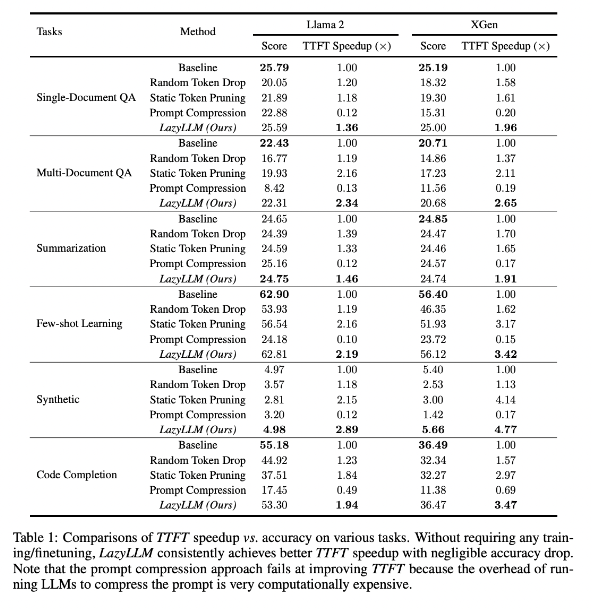
Research results show that LazyLLM performs well on multiple language tasks, with TTFT speed increased by 2.89 times (for Llama2) and 4.77 times (for XGen), while the accuracy is almost the same as the baseline. Whether it is question answering, summary generation or code completion tasks, LazyLLM can achieve faster generation speed and achieve a good balance between performance and speed. Its progressive pruning strategy coupled with layer-by-layer analysis lays the foundation for LazyLLM's success.
Paper address: https://arxiv.org/abs/2407.14057
Highlights:
LazyLLM accelerates the LLM reasoning process by dynamically selecting important tokens, especially in long text scenarios.
This technology can significantly improve the inference speed, and the TTFT speed can be increased by up to 4.77 times, while maintaining high accuracy.
LazyLLM does not require modifications to existing models, is compatible with any converter-based LLM, and is easy to implement.
All in all, the emergence of LazyLLM provides new ideas and effective solutions to solve the problem of LLM long text reasoning efficiency. Its excellent performance in speed and accuracy indicates that it will play an important role in future large model applications. This technology has broad application prospects and is worth looking forward to its further development and application.