Apple, together with the University of Washington and other institutions, released a powerful language model called DCLM as an open source, with a parameter size of 700 million and an astonishing amount of training data reaching 2.5 trillion data tokens. DCLM is not only an efficient language model, but more importantly, it provides a tool called "Dataset Competition" (DataComp) for optimizing the data set of the language model. This innovation not only improves model performance, but also provides new methods and standards for language model research, which deserves attention.
Recently, Apple's artificial intelligence team cooperated with many institutions such as the University of Washington to launch an open source language model called DCLM. This model has 700 million parameters and uses up to 2.5 trillion data tokens during training to help us better understand and generate language.
So, what is a language model? Simply put, it is a program that can analyze and generate language, helping us complete various tasks such as translation, text generation, and sentiment analysis. In order for these models to perform better, we need quality data sets. However, obtaining and organizing this data is not an easy task as we need to filter out irrelevant or harmful content and remove duplicate information.
To address this challenge, Apple’s research team launched DataComp for Language Models (DCLM), a data set optimization tool for language models. They recently open sourced the DCIM model and data set on the Hugging Face platform. The open source versions include DCLM-7B, DCLM-1B, dclm-7b-it, DCLM-7B-8k, dclm-baseline-1.0 and dclm-baseline-1.0-parquet. Researchers can conduct a large number of experiments through this platform and find the best solution. Effective data wrangling strategies.
https://huggingface.co/collections/mlfoundations/dclm-669938432ef5162d0d0bc14b
The core strength of DCLM is its structured workflow. Researchers can choose models of different sizes depending on their needs, ranging from 412 million to 700 million parameters, and can also experiment with different data curation methods, such as deduplication and filtering. Through these systematic experiments, researchers can clearly assess the quality of different data sets. This not only lays the foundation for future research, but also helps us understand how to improve model performance by improving the data set.
For example, using the benchmark data set established by DCLM, the research team trained a language model with 700 million parameters, and achieved a 5-shot accuracy of 64% in the MMLU benchmark test! This is an improvement of 6.6 compared to the previous highest level. percentage points and uses 40% less computing resources. The performance of the DCLM baseline model is also comparable to Mistral-7B-v0.3 and Llama38B, which require much more computing resources.
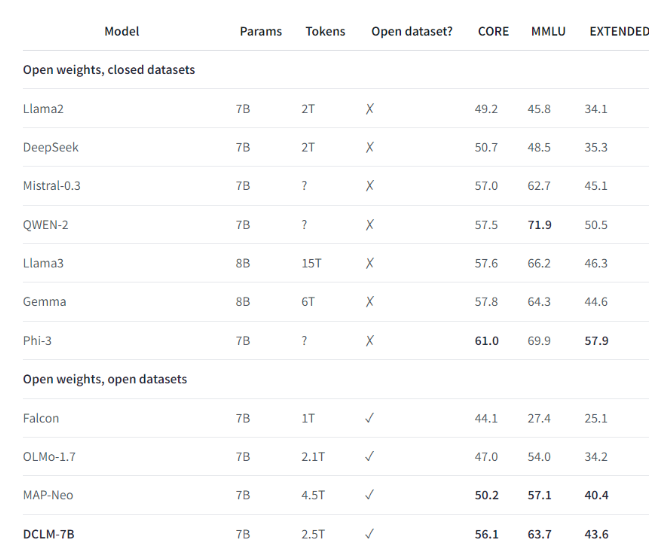
The launch of DCLM provides a new benchmark for language model research, helping scientists to systematically improve the performance of the model while reducing the required computing resources.
Highlights:
1️⃣ Apple AI cooperated with multiple institutions to launch DCLM, creating a powerful open source language model.
2️⃣ DCLM provides standardized data set optimization tools to help researchers conduct effective experiments.
3️⃣ The new model makes significant progress in important tests while reducing computational resource requirements.
All in all, DCLM's open source has injected new vitality into the field of language model research, and its efficient model and data set optimization tools are expected to promote faster development in the field and promote the birth of more powerful and efficient language models. In the future, we expect DCLM to bring more surprising research results.