Alibaba Tongyi Qianwen team released the Qwen2 series of open source models. This series includes 5 sizes of pre-training and instruction fine-tuning models. The number of parameters and performance have been significantly improved compared to the previous generation Qwen1.5. The Qwen2 series has also made a major breakthrough in multi-language capabilities, supporting 27 languages other than English and Chinese. In terms of natural language understanding, coding, mathematical capabilities, etc., the large model (70B+ parameters) performs well, especially the Qwen2-72B model, which surpasses the previous generation in performance and number of parameters. This release marks a new height in artificial intelligence technology, providing broader possibilities for global AI application and commercialization.
Early this morning, Alibaba Tongyi Qianwen team released the Qwen2 series of open source models. This series of models includes 5 sizes of pre-trained and instruction fine-tuned models: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B and Qwen2-72B. Key information shows that the number of parameters and performance of these models have been significantly improved compared to the previous generation Qwen1.5.
For the multi-lingual capabilities of the model, the Qwen2 series has invested a lot of effort in increasing the quantity and quality of the data set, covering 27 other languages except English and Chinese. After comparative testing, the large model (70B + parameters) performed well in natural language understanding, coding, mathematical capabilities, etc. The Qwen2-72B model surpassed the previous generation in terms of performance and number of parameters.
The Qwen2 model not only demonstrates strong capabilities in basic language model evaluation, but also achieves impressive results in instruction tuning model evaluation. Its multi-language capabilities perform well in benchmark tests such as M-MMLU and MGSM, demonstrating the powerful potential of the Qwen2 instruction tuning model.
The Qwen2 series models released this time mark a new height of artificial intelligence technology, providing broader possibilities for global AI applications and commercialization. Looking forward to the future, Qwen2 will further expand model scale and multi-modal capabilities to accelerate the development of the open source AI field.
Model informationThe Qwen2 series includes 5 sizes of basic and command-tuned models, including Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, and Qwen2-72B. We explain the key information for each model in the table below:
Model Qwen2-0.5BQwen2-1.5BQwen2-7BQwen2-57B-A14BQwen2-72B# Parameter 049 million 154 million 707B57.41B72.71B# Non-Emb parameter 035 million 131B598 million 5632 million 7021B Quality assurance is really really really of true true tie embedded true true false false false false context length 32 thousand 32 thousand 128 thousand 64 thousand 128 thousandSpecifically, in Qwen1.5, only Qwen1.5-32B and Qwen1.5-110B used Group Query Attention (GQA). This time, we applied GQA for all model sizes so that they enjoy the benefits of faster speeds and smaller memory footprint in model inference. For small models, we prefer to apply tying embeddings because large sparse embeddings account for a large portion of the total parameters of the model.
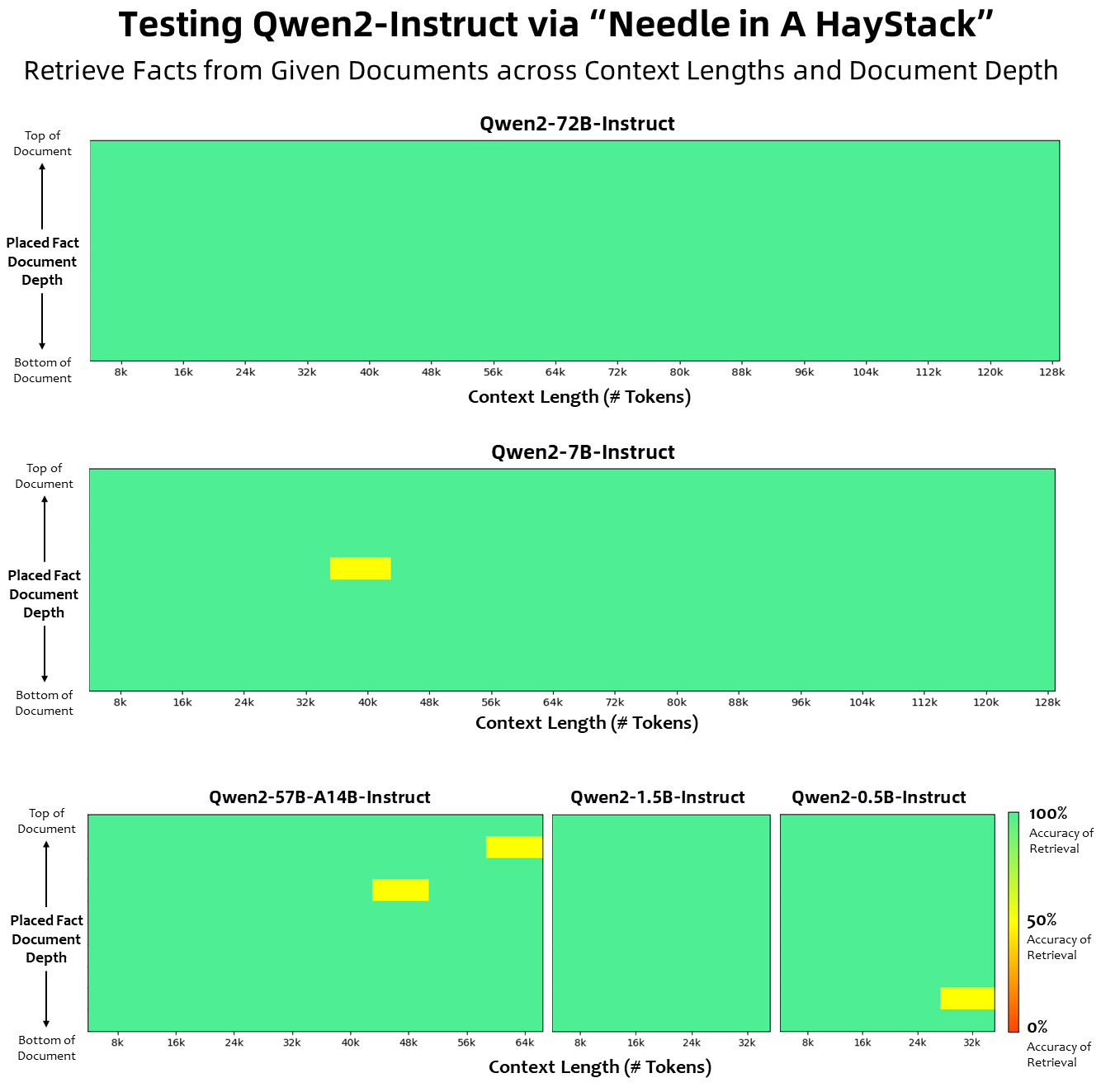
In terms of context length, all base language models have been pre-trained on context length data of 32K tokens, and we observed satisfactory extrapolation capabilities up to 128K in PPL evaluation. However, for instruction-tuned models, we are not satisfied with just PPL evaluation; we need the model to be able to correctly understand the long context and complete the task. In the table, we list the context length capabilities of the instruction tuning model, as assessed by evaluation on the Needlein a Haystack task. It is worth noting that when enhanced with YARN, both the Qwen2-7B-Instruct and Qwen2-72B-Instruct models show impressive capabilities and can handle context lengths up to 128K tokens.
We have made significant efforts to increase the quantity and quality of pre-training and instruction-tuned datasets covering multiple languages beyond English and Chinese to enhance its multilingual capabilities. Although large language models have the inherent ability to generalize to other languages, we explicitly emphasize the inclusion of 27 other languages in our training:
Regional Languages West European German, French, Spanish, Portuguese, Italian, Dutch Eastern and Central European Russian, Czech, Polish Middle Eastern Arabic, Persian, Hebrew, Turkish East Asian Japanese, Korean Southeast Asian Vietnamese, Thai, Indonesian, Malay, Lao, Burmese, Cebuano, Khmer, Tagalog South Asian Hindi, Bengali, UrduAdditionally, we put significant effort into solving the transcoding issues that often arise in multilingual assessments. Therefore, our model's ability to handle this phenomenon is significantly improved. Evaluations using cues that typically elicit cross-language code-switching confirmed a significant reduction in related problems.
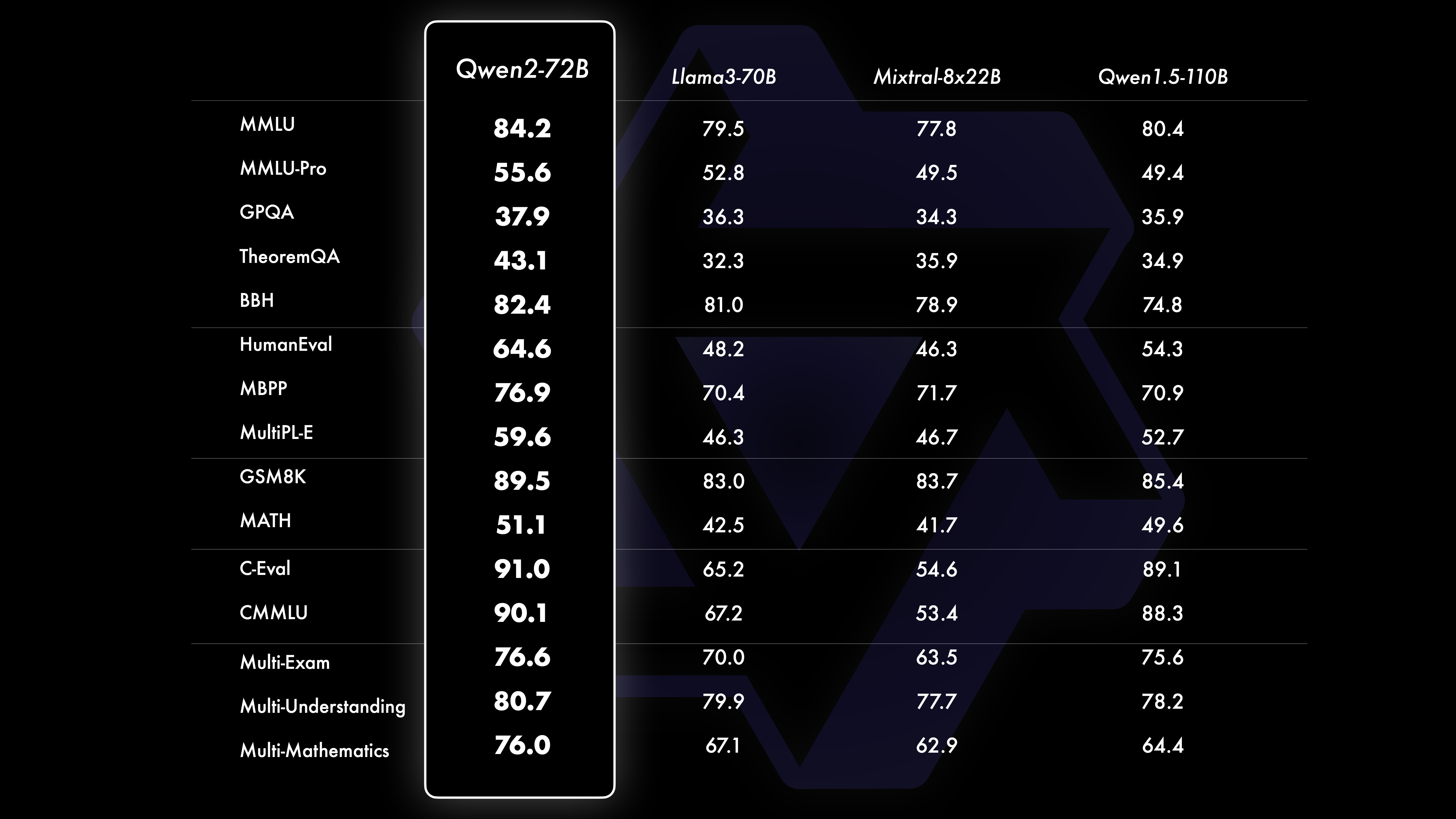
PerformanceComparative test results show that the performance of the large-scale model (70B+ parameters) has been significantly improved compared to Qwen1.5. This test centered on the large-scale model Qwen2-72B. In terms of basic language models, we compared the performance of Qwen2-72B and the current best open models in terms of natural language understanding, knowledge acquisition, programming capabilities, mathematical capabilities, multi-language capabilities and other capabilities. Thanks to carefully selected data sets and optimized training methods, Qwen2-72B outperforms leading models such as Llama-3-70B, and even outperforms the previous generation Qwen1.5- with a smaller number of parameters. 110B.
After extensive large-scale pre-training, we perform post-training to further enhance Qwen's intelligence and make it closer to humans. This process further improves the model's capabilities in areas such as coding, mathematics, reasoning, instruction following, and multi-language understanding. Furthermore, it aligns the model’s output with human values, ensuring that it is useful, honest, and harmless. Our post-training phase is designed with the principles of scalable training and minimal human annotation. Specifically, we study how to obtain high-quality, reliable, diverse, and creative presentation data and preference data through various automatic alignment strategies, such as rejection sampling for mathematics, execution feedback for coding and instruction following, and back-translation for creative writing. , scalable supervision of role-playing, and more. As for training, we use a combination of supervised fine-tuning, reward model training, and online DPO training. We also employ a novel online merge optimizer to minimize alignment taxes. These combined efforts greatly improve the capabilities and intelligence of our models, as shown in the table below.
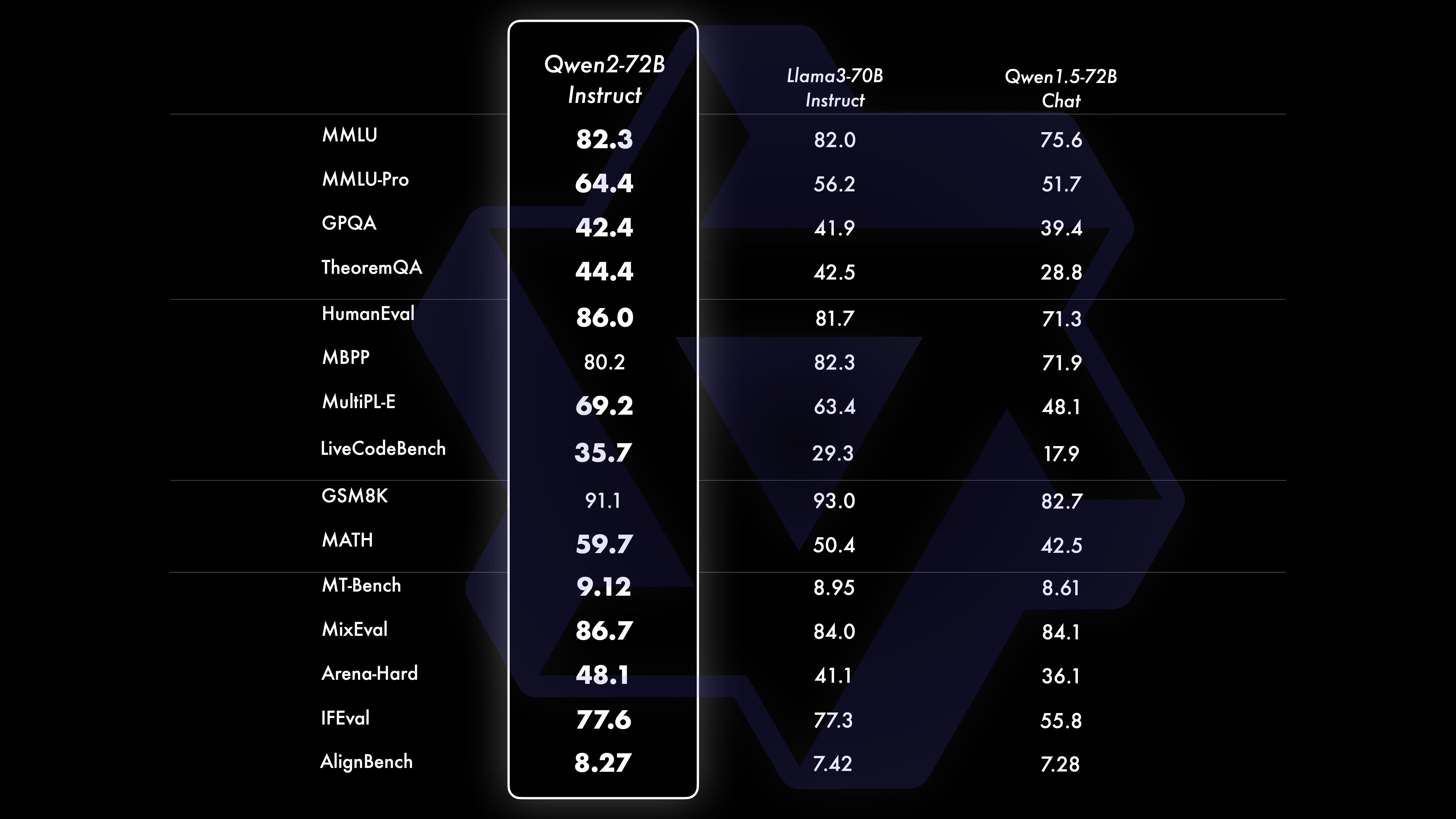
We conducted a comprehensive evaluation of Qwen2-72B-Instruct, covering 16 benchmarks in various fields. Qwen2-72B-Instruct strikes a balance between gaining better abilities and being consistent with human values. Specifically, Qwen2-72B-Instruct significantly outperforms Qwen1.5-72B-Chat in all benchmarks and also achieves competitive performance compared to Llama-3-70B-Instruct.
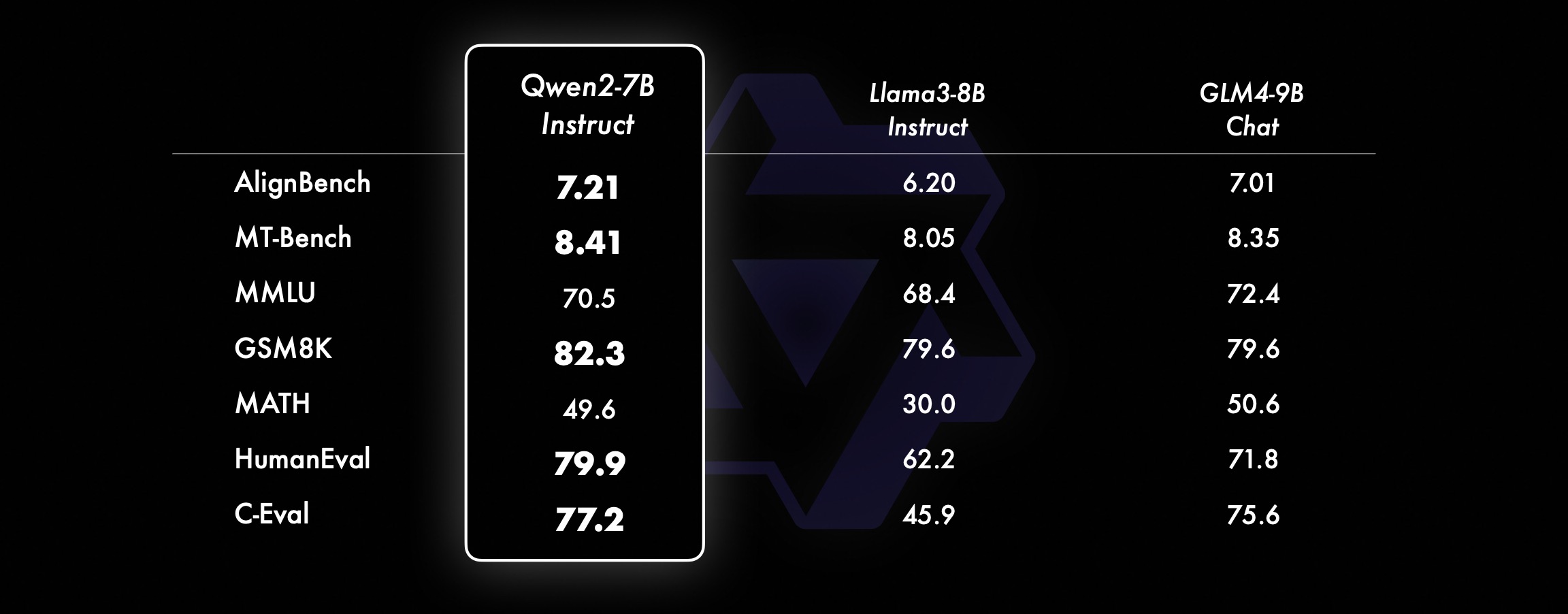
On smaller models, our Qwen2 models also outperform similar and even larger sized SOTA models. Compared with the just-released SOTA model, Qwen2-7B-Instruct still shows advantages in various benchmark tests, especially in encoding and Chinese-related indicators.
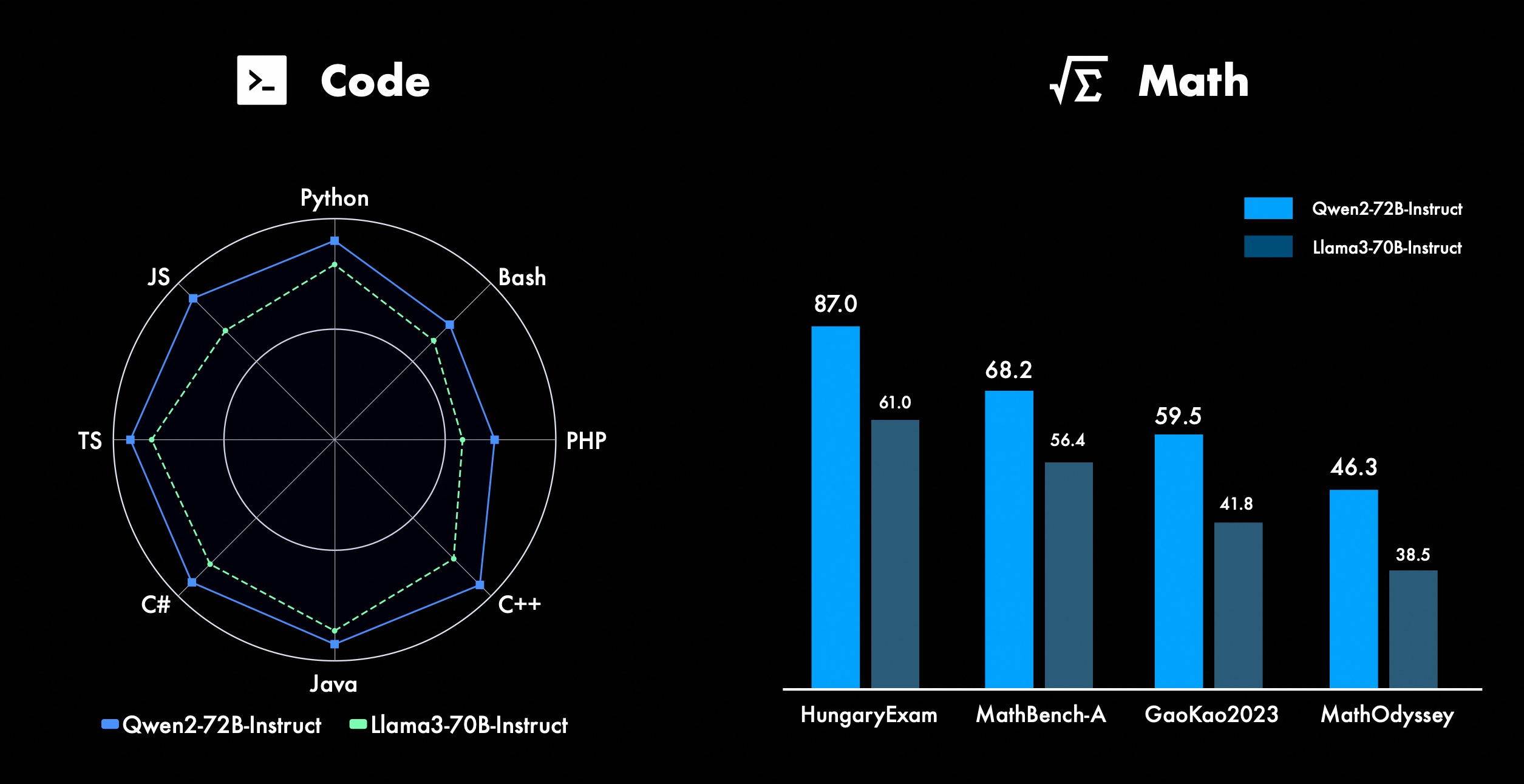
We're constantly working on improving Qwen's advanced features, especially in coding and math. In terms of coding, we successfully integrated the code training experience and data of CodeQwen1.5, resulting in Qwen2-72B-Instruct achieving significant improvements in various programming languages. In mathematics, Qwen2-72B-Instruct demonstrates enhanced capabilities in solving mathematical problems by leveraging an extensive and high-quality data set.
In Qwen2, all instruction tuning models are trained on 32k length contexts and extrapolated to longer context lengths using techniques such as YARN or Dual Chunk Attention.
The picture below shows our test results on Needle in a Haystack. It is worth noting that Qwen2-72B-Instruct can perfectly handle the information extraction task in the 128k context. Coupled with its inherent powerful performance, it can be used when resources are sufficient. case, it becomes the first choice for processing long text tasks.
Furthermore, it is worth noting the impressive capabilities of the other models in the series: the Qwen2-7B-Instruct handles contexts up to 128k almost perfectly, the Qwen2-57B-A14B-Instruct manages contexts up to 64k, and the series The two smaller models support 32k contexts.
In addition to the long context model, we open sourced a proxy solution for efficient processing of documents containing up to 1 million tags. For more details, see our dedicated blog post on this topic.
The table below shows the proportion of harmful responses generated by a large model for four categories of multilingual unsafe queries (illegal activity, fraud, pornography, private violence). Test data comes from Jailbreak and is translated into multiple languages for evaluation. We found that Llama-3 does not handle multilingual cues efficiently and therefore did not include it in the comparison. Through the significance test (P_value), we found that the Qwen2-72B-Instruct model's security performance is equivalent to that of GPT-4, and significantly better than the Mistral-8x22B model.
Language Illegal Activity Fraud Pornography Privacy Violence GPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-GuidanceGPT-4 Mistral-8x22BQwen2-72B-Guidance GPT-4 Mistral-8x22BQwen2-72B-Guide Chinese0%13%0%0%17%0%43%47%53%0%10%0%English0%7%0%0%23% 0%37%67%63%0%27%3%Accounts receivable0%13%0%0%7%0%15%26%15%3%13%0%西文0%7%0%3 %0%0%48%64%50%3%7%3%France0%3%0%3%3%7%3%19%7%0%27%0%Ke0%4%0%3 %8%4%17%29%10%0%26%4%point0%7%0%3%7%3%47%57%47%4%26%4%日0%10%0%7 %23%3%13%17%10%13%7%7%六0%4%0%4%11%0%22%26%22%0%0%0%average0%8%0% 3%11%2%27%39%31%3%16%2% use Qwen2 for developmentCurrently, all models have been released in Hugging Face and ModelScope. You are welcome to visit the model card to view detailed usage methods and learn more about the characteristics, performance and other information of each model.
For a long time, many friends have supported the development of Qwen, including fine-tuning (Axolotl, Llama-Factory, Firefly, Swift, XTuner), quantification (AutoGPTQ, AutoAWQ, Neural Compressor), deployment (vLLM, SGL, SkyPilot, TensorRT-LLM, OpenVino, TGI), API Platform (Together, Fireworks, OpenRouter), Local Run (MLX, Llama.cpp, Ollama, LM Studio), Agent and RAG Framework (LlamaIndex, CrewAI, OpenDevin), Evaluation (LMSys, OpenCompass, Open LLM Leaderboard), model training (Dolphin, Openbuddy), etc. On how to use Qwen2 with third-party frameworks, please refer to their respective documentation as well as our official documentation.

There are many teams and individuals who have contributed to Qwen that we have not mentioned. We sincerely appreciate their support and hope that our collaboration will promote research and development in the open source AI community.
licenseThis time, we change the model's permission to a different one. Qwen2-72B and its instruction tuning model still use the original Qianwen License, while all other models, including Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B and Qwen2-57B-A14B, have switched to Apache2.0 !We believe that the further opening of our model to the community can accelerate the application and commercialization of Qwen2 around the world.
What’s next for Qwen2?We are training a larger Qwen2 model to further explore model extensions as well as our recent data extensions. Furthermore, we extend the Qwen2 language model to be multi-modal, capable of understanding visual and audio information. In the near future, we will continue to open source new models to accelerate open source AI. Stay tuned!
QuoteWe will release a technical report on Qwen2 soon. Quotes welcome!
@article{qwen2, Appendix Basic Language Model EvaluationThe evaluation of basic models mainly focuses on model performance such as natural language understanding, general question answering, coding, mathematics, scientific knowledge, reasoning, and multi-language capabilities.
The datasets evaluated include:
English tasks: MMLU (5 times), MMLU-Pro (5 times), GPQA (5 times), Theorem QA (5 times), BBH (3 times), HellaSwag (10 times), Winogrande (5 times), TruthfulQA ( 0 times), ARC-C (25 times)
Coding tasks: EvalPlus (0-shot) (HumanEval, MBPP, HumanEval+, MBPP+), MultiPL-E (0-shot) (Python, C++, JAVA, PHP, TypeScript, C#, Bash, JavaScript)
Mathematics tasks: GSM8K (4 times), MATH (4 times)
Chinese tasks: C-Eval (5-shot), CMMLU (5-shot)
Multi-language tasks: multiple exams (M3Exam 5 times, IndoMMLU 3 times, ruMMLU 5 times, mmMLU 5 times), multiple understandings (BELEBELE 5 times, XCOPA 5 times, XWinograd 5 times, XStoryCloze 0 times, PAWS-X 5 times), multiple mathematics (MGSM 8 times), multiple translations (Flores-1015 times)
Qwen2-72B Performance Dataset DeepSeek-V2Mixtral-8x22BCamel-3-70BQwen1.5-72BQwen1.5-110BQwen2-72BArchitectureMinistry of EducationDenseDenseDenseDenseDense#Activated Parameters 21B39B70B72B110B72B#Parameters 236B140B70B72B110B72B English Mohrman ·Lu 78.577.879.577.580.484.2MMLU-Professional Edition-49.552.845.849.455.6Quality Assurance-34.336.336.335.937.9Theorem Q&A-35.932.329.334.943.1Baibihei 78.978.981.065.574.88 2.4 Shiraswag 87.888.788.086. 087.587.6 Large Windows 84.885.085.383.083.585.1ARC-C70.070.768.865.969.668.9 Honest Q&A 42.251.045.659.649.654.8 Coding Manpower Assessment 45.746.348.246.354.364.6 Malaysian Public Service Department 73 .971.770.466.970.976.9 Assessment 55.054.154.852.957.765.4 Various 44.446.746.341.852.759.6 Math GSM8K79.283.783.079.585.489.5 Math 43.641.742.534.149.651.1 Chinese C-Assessment 81.754.665. 284.189.191.0 University of Montreal, Canada 84.053 .467.283.588.390.1Multiple languages and multiple exams 67.563.570.066.475.676.6Multiple understandings 77.077.779.978.278.280.7Multiple mathematics 58.862.967.161.764.476.0Multiple translations 36.023.338.035.636.2 37.8Qwen2-57B-A14B Dataset Jabba Mixtral-8x7B Instrument-1.5-34BQwen1.5-32BQwen2-57B-A14B Architecture MoE MoE Dense Dense MoE #Activated Parameters 12B12B34B32B14B #Parameters 52B47B34B32B57B English Moleman Lu 67.471.877.174.376.5MMLU - Professional Edition - 41.048.344.043.0 Quality Assurance - 29.2 - 30.834.3 Theorem Q&A - 23.2 - 28.833.5 Baibei Black 45.450.376.466.867.0 Shiela Swag 87.186.585.985.085.2 Winogrand 82.581.984.981 .579.5ARC-C64.466.065.663.664.1 Honest Questions and Answers 46.451.153.957.457.7 Coding Manpower Assessment 29.337.246.343.353.0 Public Service Malaysia - 63.965.564.271.9 Assessment - 46.451.950.457.2 Various - 39.03 9.538.549 .8 Mathematics GSM8K59.962.582.776.880.7 Mathematics-30.841.736.143.0 Chinese C-Assessment---83.587.7 University of Montreal, Canada--84.882.388.5 Multiple languages and multiple examinations-56.158.361.665.5 Multi-party understanding -70.773.976.577.0Multiple Mathematics -45.049.356.162.3Multiple Translation -29.830.033.534.5Qwen2-7B Dataset Mistral -7B Jemma -7B Camel -3-8BQwen1.5-7BQwen2-7B# Parameters 7.2B850 million 8.0B7.7B7.6B# Non-emb parameters 7.0B780 million 7.0B650 million 650 million English Mohrman Lu 64.264.666.661.070.3MMLU-Pro 30.933.735.429.940.0 Quality assurance 24.725 .725.826.731.8 Theorem Q&A 19.221.522.114.231.1 Baibei Black 56.155.157.740.262.6 Shiraswager 83.282.282.178.580.7 Winogrand 78.479.077.471.377.0ARC-C60.061.159 .354.260.6Honest Questions and Answers 42.244 .844.051.154.2 Coding Manpower Assessment 29.337.233.536.051.2 Public Service Malaysia 51.150.653.951.665.9 Assessment 36.439.640.340.054.2 Multiple 29.429.722.628.146.3 Mathematics GSM8K52.246.456.0 62.579.9 Mathematics 13.124.320.520.344.2 China Human C-Assessment 47.443.649.574.183.2 Université de Montréal, Canada -- 50.873.183.9 Multilingual Multiple Examination 47.142.752.347.759.2 Multiple Understanding 63.358.368.667.672.0 Multivariate Mathematics 26.339.136.337.357.5 Multiple Translation 23.331.231 .928.431.5Qwen2 -0.5B and Qwen2-1.5B dataset Phi-2Gemma-2B Minimum CPM Qwen1.5-1.8BQwen2-0.5BQwen2-1.5B# Non-Emb parameters 250 million 2.0B2.4B1.3B035 million 1.3 B Mohrman Lu 52.742.353.546.845.456.5MMLU-Professional-15.9--14.721.8 Theorem Q&A----8.915.0 Manpower Assessment 47.622.050.020.122.031.1 Malaysian Public Service Department 55.029.247.318.022.037 .4GSM8K57.217.753.838.436.558.5 Math 3.511.810.210.110.721.7 Baibi Black 43.435.236.924.228.437.2 Shiela Swag 73.171.468.361.449.366.6 Winogrand 74.466.8 -60.356.866.2ARC -C61.148.5-37.931.543.9 Honest Q&A 44.533.1-39.439.745.9C - Evaluation 23.428.051.159.758.270.6 University of Montreal, Canada 24.2 - 51.157.855.170.3 Instruction Tuning Model Evaluation Qwen2-72B - Guided Dataset Camel - 3-70B - Guidance Qwen1.5-72B - Chat Qwen2-72B - Guidance English Mohr Man Lu 82.075.682.3MMLU - Professional Edition 56.251.764.4 Quality Assurance 41.939.442.4 Theorem Q&A 42.528.844.4MT - Bench8.958.619.12 Arena - Hard 41.136.148.1 IFEval (Prompt Strict Access) 77.355.877.6 Coding Manpower Assessment 81.771.386.0 Public Service Malaysia 82.371.980.2 Multiple 63.448.169.2 Assessment 75.266.979.0 Live Code Test 29.317.935.7 Mathematics GSM 8K93.082.7 91. 1 Mathematics 50.442.559.7 Chinese C-Evaluation 61.676.183.8AlignBench7.427.288.27Qwen2-57B-A14B-Instruction DatasetMixtral-8x7B-Instruct-v0.1Yi-1.5-34B-ChatQwen1.5-32B-ChatQwen2- 57B-A14B - Guidance Architecture Ministry of Education Dense Dense Ministry of Education #Activated parameter 12B34B32B14B #Parameter 47B34B32B57B English Mohr Man Lu 71.476.874.875.4MMLU - Professional Edition 43.352.346.452.8 Quality Assurance -- 30.834.3 Theorem Questions and Answers - -30.933.1MT-Bench8.308.508.308.55 Coding Manpower Assessment 45.175.268.379.9 Public Service Malaysia 59.574.667.970.9 Various --50.766.4 Assessment 48.5-63.671.6 Live Code Test 12.3-15.225.5 Mathematics GSM8K65.790.283.679.6 Mathematics 30.750.142.449.1 Chinese C-Evaluation--76.780.5AlignBench5.707.207.197.36Qwen2-7B-Guide Dataset Camel-3-8B-Guide Yi-1.5-9B-Chat GLM-4- 9B-Chat Qwen1.5-7B-Chat Qwen2-7B-Guide English Mohrman Lu 68.469.572.459.570.5MMLU-Pro 41.0--29.144.1 Quality Assurance 34.2--27.825.3 Theorem Q&A 23.0--14.125 .3MT-Bench8.058.208.357.608.41 Coding Humanitarian 62.266.571.846.379.9 Public Service Malaysia 67.9--48.967.2 Multiple 48.5--27.259.1 Assessment 60.9--44.870.3 Live Code Test 17.3-- 6.026.6 Math GSM8K79.684.879.660.382.3 Math 30.047.750.623.249.6 Chinese C-Assessment 45.9-75.667.377.2 AlignBench6.206.907.016.207.21 Qwen2-0.5B-Instruct and Qwen2-1.5B-Instruct Data set Qwen1. 5-0.5B-Chat Qwen2-0.5B-Guide Qwen1.5-1.8B-Chat Qwen2-1.5B-Guide Morman Lu35.037.943.752.4 Manpower Assessment 9.117.125.037.8GSM8K11.340.135.361.6C-Assessment 37.245.255.363.8IFEval (prompt for strict access) 14.620.016.829.0 command adjusts the multi-language capabilities of the modelWe compare the Qwen2 instruction tuning model with other recent LLMs on several cross-language open benchmarks as well as human evaluation. For the baseline, we present results on 2 evaluation datasets:
Okapi's M-MMLU: Multilingual general knowledge assessment (we use subsets of ar, de, es, fr, it, nl, ru, uk, vi, zh for assessment) MGSM: for German, English, Spanish, French, Mathematics assessments in Japanese, Russian, Thai, Chinese and Brazilian languagesThe results are averaged across languages for each benchmark and are as follows:
Exemplary M-MMLU (5 shots) MGSM (0 shots, CoT) Proprietary LLM GPT-4-061378.087.0GPT-4-Turbo-040979.390.5GPT-4o-051383.289.6 Claude-3-works- 2024022980.191.0 claude-3-sonnet-2024022971.085.6 open source LL.M command-r-plus-110b65.563.5Qwen1.5-7B-chat 50.037.0Qwen1.5-32B-chat 65.065.0Qwen1.5 -72B-Chat 68.471.7Qwen2-7B-Guide 60.057.0Qwen2-57B-A14B-Guide 68.074.0Qwen2-72B-Guide 78.086.6For manual evaluation, we compare Qwen2-72B-Instruct with GPT3.5, GPT4, and Claude-3-Opus using an in-house evaluation set, which includes 10 languages ar, es, fr, ko, th, vi, pt, id , ja and ru (score range from 1 to 5):
Model Accounts Receivable Spanish French Corri Six Points ID Jiaru Average Claude-3-Works-202402294.154.314.234.234.013.984.094.403.854.254.15GPT-4o-05133.554.264.164.404.094.143.894.3 93.724.324.09 GPT-4-Turbo-04093.444.084.194.244.113.843.864.093.684.273.98Qwen2-72B-Guide 3.864.104.014.143.753.913.973.833.634.153.93GPT-4-06133.5 53.923.943.873.833.953.553.773.063.633.71GPT- 3.5-Turbo-11062.524.073.472.373.382.903.373.562.753.243.16Grouped by task type, the results are as follows:
Model Knowledge Understanding Creating Mathematics Claude-3-Works-202402293.644.454.423.81GPT-4o-05133.764.354.453.53GPT-4-Turbo-04093.424.294.353.58Qwen2-72B-Guide3.414.074.363.61GPT- 4-06133.424. 094.103.32GPT-3.5-Turbo-11063.373.673.892.97These results demonstrate the powerful multilingual capabilities of the Qwen2 instruction tuning model.
Alibaba's open source Qwen2 series models have significantly improved performance and multi-language capabilities, making an important contribution to the open source AI community. In the future, Qwen2 will continue to develop and further expand model scale and multi-modal capabilities, which is worth looking forward to.