视觉字幕
v1.0
Visual Captions字幕工具,VisualCaptions是新推出的一款强大的字幕工具,可以为用户的工作会议改进更多字幕的显示,更方便地实现办公交流。有需要的用户快来加入其中吧。
谷歌在人机交互顶级会议 ACM CHI(Conference on Human Factors in Computing Systems)上展示了一个系统 Visual Captions,介绍了远程会议中的一个全新视觉解决方案,可以在对话背景中生成或检索图片以提高对方对复杂或陌生概念的了解。
Visual Captions 系统基于一个微调后的大型语言模型,可以在开放词汇的对话中主动推荐相关的视觉元素,并已融入开源项目 ARChat 中。
在用户调研中,研究人员邀请了实验室内的 26 位参与者,与实验室外的 10 位参与者对系统进行评估,超过 80% 的用户基本都认同 Video Captions 可以在各种场景下能提供有用、有意义的视觉推荐,并可以提升交流体验。
在开发之前,研究人员首先邀请了 10 位内部参与者,包括软件工程师、研究人员、UX 设计师、视觉艺术家、学生等技术与非技术背景的从业者,讨论对实时视觉增强服务的特定需求和期望。
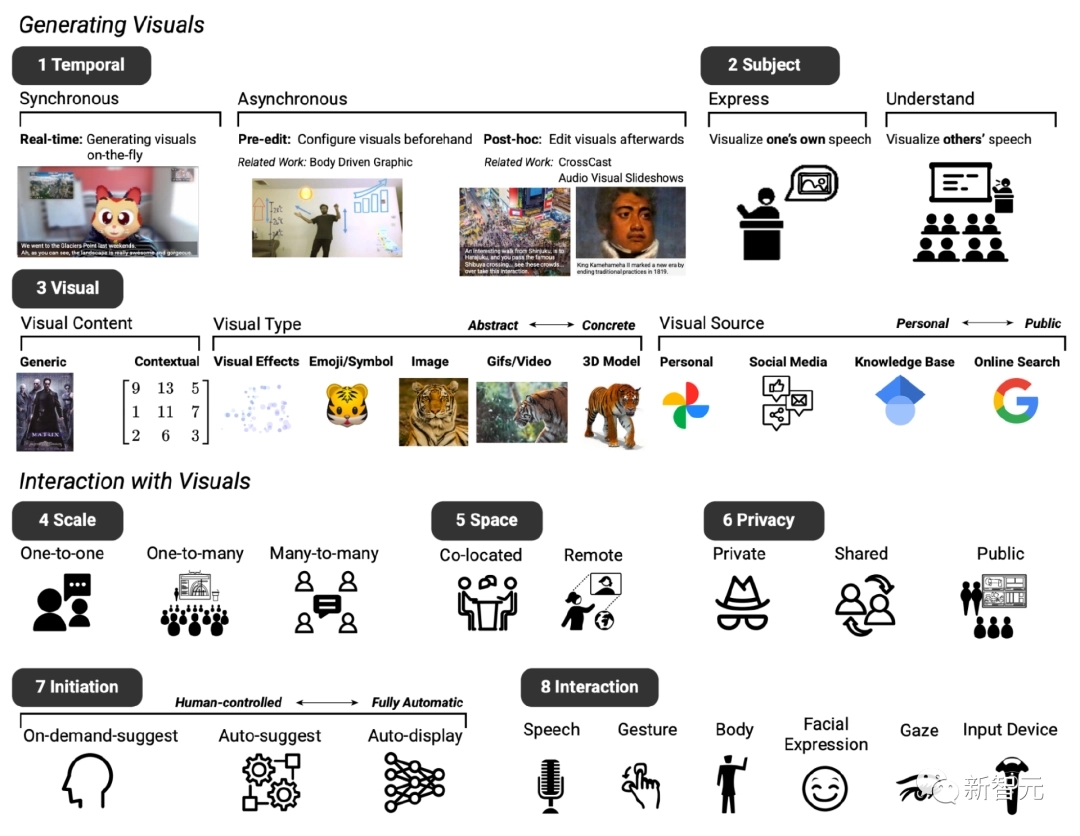
两次会议后,根据现有的文本转图像系统,确立了预期原型系统的基本设计,主要包括八个维度(记为 D1 至 D8)。
D1:时序,视觉增强系统可与对话同步或异步展现
D2:主题,可用于表达和理解语音内容
D3:视觉,可使用广泛的视觉内容、视觉类型和视觉源
D4:规模,根据会议规模的不同,视觉增强效果可能有所不同
D5:空间,视频会议是在同一地点还是在远程设置中
D6:隐私,这些因素还影响视觉效果是否应该私下显示、在参与者之间共享或向所有人公开
D7:初始状态,参与者还确定了他们希望在进行对话时与系统交互的不同方式,例如,不同级别的「主动性」,即用户可以自主确定系统何时介入聊天 D8:交互,参与者设想了不同的交互方法,例如,使用语音或手势进行输入