TrafficLLM的存储库是一个通用的 LLM 适应框架,用于学习现实场景中所有开源 LLM 的稳健流量表示,并增强跨不同流量分析任务的泛化能力。

注意:此代码基于 ChatGLM2 和 Llama2。非常感谢作者。
[2024.10.28]我们更新了使用GLM4构建TrafficLLM的适配代码,它比ChatGLM2具有更快的调优和推理速度。请访问 Adapt2GLM4 了解更多详细信息。
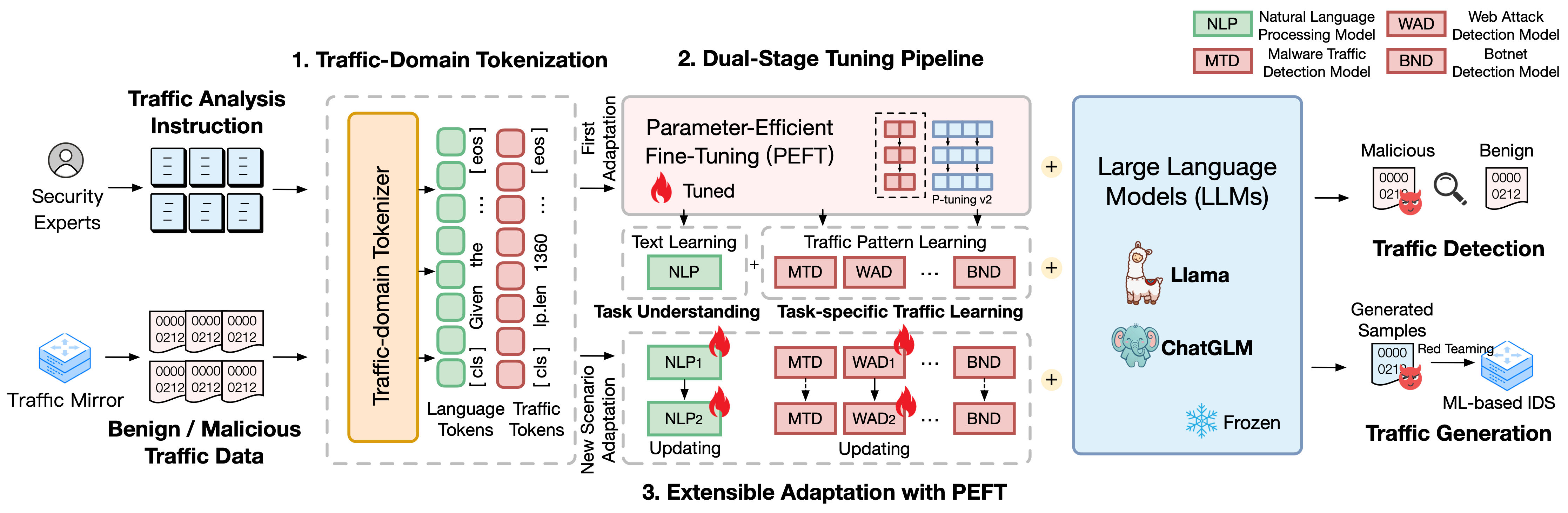
TrafficLLM建立在使用自然语言和流量数据的复杂微调框架之上,它提出了以下技术来增强大型语言模型在网络流量分析中的实用性。
流量域标记化。为了克服自然语言和异构流量数据之间的模态差距,TrafficLLM 引入了流量域标记化来处理流量检测和生成任务的不同输入,以实现 LLM 适应。该机制通过在大规模流量域语料库上训练专门的标记化模型,有效地扩展了 LLM 的原生标记器。
双级调整管道。 TrafficLLM 采用双阶段调整管道来实现 LLM 跨不同流量域任务的稳健表示学习。该管道训练 LLM 理解指令并学习不同阶段与任务相关的流量模式,这建立在 TrafficLLM 任务理解和流量推理能力的基础上,用于各种流量检测和生成任务。
具有参数有效微调的可扩展适应(EA-PEFT)。为了使 LLM 泛化到新的交通环境中,TrafficLLM 提出了一种可扩展的参数有效微调自适应方法 (EA-PEFT),以低开销更新模型参数。该技术将模型功能拆分为不同的 PEFT 模型,这有助于最大限度地降低因流量模式变化而产生的动态场景的成本。
我们发布了 TrafficLLM 的训练数据集,其中包含超过 0.4M 的流量数据和 9K 的人工指令,用于 LLM 适应不同的流量分析任务。
Instruction Datasets :指令数据集用于帮助LLM学习流量检测或生成任务的领域知识,并了解在不同场景下应该执行哪些任务。
Traffic Datasets :流量数据集包含我们从公共流量数据集中提取的流量调整数据,这有助于LLM了解不同下游任务中的流量模式。
为了构建自然语言语料库作为 TrafficLLM 中的人类指令,我们收集了由专家和人工智能助手监督的 9,209 条特定任务指令。统计结果如下:
| 主流任务 | 下游任务 | 简称。 | #样本 |
|---|---|---|---|
| 流量检测 | 恶意软件流量检测 | MTD | 1.0K |
| 僵尸网络检测 | 联邦国防军 | 1.1K | |
| 恶意 DoH 检测 | MDD | 0.6K | |
| 网络攻击检测 | 瓦德 | 0.6K | |
| APT攻击检测 | 亚德 | 0.6K | |
| 加密 VPN 检测 | 埃博拉病毒病 | 1.2K | |
| Tor 行为检测 | 待定 | 0.6K | |
| 加密应用分类 | 欧洲联盟 | 0.6K | |
| 网站指纹识别 | WF | 0.6K | |
| 概念漂移 | 光盘 | 0.6K | |
| 流量生成 | 恶意软件流量生成 | MTG | 0.6K |
| 僵尸网络流量生成 | BTG | 0.1K | |
| 加密 VPN 生成 | EVG | 0.4K | |
| 加密应用程序生成 | EAG | 0.6K |
为了评估 TrafficLLM 在各种网络场景下的性能,我们从公开的流量数据集中提取了超过 0.4M 的调优数据,以衡量 TrafficLLM 检测或生成恶意和良性流量的能力。统计结果如下:
| 数据集 | 任务 | 简称。 | #样本 |
|---|---|---|---|
| 中科大TFC 2016 | 恶意软件流量检测 | MTD | 50.7K |
| ISCX 僵尸网络 2014 | 僵尸网络检测 | 联邦国防军 | 25.0K |
| 2020 年 DHBrw | 恶意 DoH 检测 | MDD | 47.8K |
| 中船重工2010 | 网络攻击检测 | 瓦德 | 34.5K |
| 2020年DAPT | APT攻击检测 | 亚德 | 10.0K |
| ISCX VPN 2016 | 加密 VPN 检测 | 埃博拉病毒病 | 64.8K |
| ISCX 托尔 2016 | Tor 行为检测 | 待定 | 40.0K |
| 科技网2023 | 加密应用分类 | 欧洲联盟 | 97.6K |
| CW-100 2018 | 网站指纹识别 | WF | 7.4K |
| APP-53 2023 | 概念漂移 | 光盘 | 109.8K |
1. 环境准备 2. 培训 TrafficLLM 2.1.准备预训练检查点 2.2。 2.3. 预处理数据集 训练流量域标记器(可选) 2.4。神经语言指令调整 2.5。特定于任务的流量调整 2.6。 PEFT 的可扩展适应 (EA-PEFT) 3. 评估 TrafficLLM 3.1。 3.2. 准备检查点和数据 运行评估目录:
一、环境准备【返回顶部】
请通过运行以下命令克隆存储库并安装所需的环境。
conda 创建-n Trafficllm python=3.9 conda activate Trafficllm# 克隆我们的 TrafficLLMgit 克隆 https://github.com/ZGC-LLM-Safety/TrafficLLM.gitcd TrafficLLM# 安装所需的库pip install -r requests.txt# 如果训练pip 安装 rouge_chinese nltk jieba 数据集
TrafficLLM 采用三种核心技术:处理指令和流量数据的流量域标记化、用于理解文本语义和学习跨不同任务的流量模式的双阶段调整管道以及用于更新的EA-PEFT新场景适应的模型参数。
TrafficLLM 是基于现有开源 LLM 进行训练的。请按照说明准备检查点。
ChatGLM2 :准备基本模型ChatGLM,这是一个具有轻型部署要求的开源LLM。请在此处下载其权重。我们通常使用具有 6B 参数的 v2 模型。
Other LLMs :要使其他LLM适应流量分析任务,您可以重用存储库中的训练数据并根据官方说明修改其训练脚本。例如,Llama2 需要在配置中注册新数据集。
为了从原始流量数据集中提取适合 LLM 学习的训练数据,我们设计了专门的提取器来预处理不同任务的流量数据集。预处理代码包含以下参数进行配置。
input :原始流量数据集路径(包含标记子目录的主目录路径。每个标记子目录包含要预处理的原始 .pcap 文件)。
dataset_name :原始流量数据集名称(有助于判断该名称是否已在 TrafficLLM 的代码中注册)。
traffic_task :检测任务或生成任务。
granularity :数据包级或流级粒度。
output_path :输出训练数据集路径。
output_name :输出训练数据集名称。
这是一个为数据包级流量检测任务预处理原始流量数据集的实例。
光盘预处理 python preprocess_dataset.py --输入/您的/原始/数据集/路径 --dataset_name /您的/原始/数据集/名称 --traffic_task 检测 --粒度包 --output_path /您的/输出/数据集/路径 --output_name /您的/Output/Dataset/Name
TrafficLLM 引入了流量域分词器来处理神经语言和流量数据。如果您想使用自己的数据集训练自定义分词器,请修改代码中的model_name和data_path 。
model_name :包含本机分词器的基本模型路径。
data_path :从预处理过程中提取的训练数据集。
请按照命令使用代码。
CD标记化 python Traffic_tokenizer.py
准备数据:神经语言指令调优数据是我们收集的用于流量分析任务理解的指令数据集。
开始调优:完成上述步骤后,就可以使用trafficllm_stage1.sh开始第一阶段调优了。有一个例子如下:
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1导出 CUDA_VISIBLE_DEVICES=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py
--do_train
--train_file ../datasets/instructions/instructions.json
--validation_file ../datasets/instructions/instructions.json
--preprocessing_num_workers 10
--prompt_column 指令
--response_column 输出
--overwrite_cache
--cache_dir ../缓存
--模型名称或路径../models/chatglm2/chatglm2-6b
--output_dir ../models/chatglm2/peft/指令
--overwrite_output_dir
--最大源长度 1024
--最大目标长度 32
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--predict_with_generate
--max_steps 20000
--logging_steps 10
--save_steps 4000
--学习率 $LR
--pre_seq_len $PRE_SEQ_LEN 准备数据:特定于任务的流量调整数据集是从不同下游任务的预处理步骤中提取的训练数据集。
开始调优:完成上述步骤后,就可以使用trafficllm_stage2.sh开始第二阶段调优了。有一个例子如下:
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1导出 CUDA_VISIBLE_DEVICES=1
torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py
--do_train
--train_file ../datasets/ustc-tfc-2016/ustc-tfc-2016_detection_packet_train.json
--validation_file ../datasets/ustc-tfc-2016/ustc-tfc-2016_detection_packet_train.json
--preprocessing_num_workers 10
--prompt_column 指令
--response_column 输出
--overwrite_cache
--cache_dir ../缓存
--模型名称或路径../models/chatglm2/chatglm2-6b
--output_dir ../models/chatglm2/peft/ustc-tfc-2016-检测数据包
--overwrite_output_dir
--最大源长度 1024
--最大目标长度 32
--per_device_train_batch_size 1
--per_device_eval_batch_size 1
--gradient_accumulation_steps 16
--predict_with_generate
--max_steps 20000
--logging_steps 10
--save_steps 4000
--学习率 $LR
--pre_seq_len $PRE_SEQ_LEN TrafficLLM 采用 EA-PEFT 来组织具有可扩展适配的参数有效微调 (PEFT) 模型,这可以帮助 TrafficLLM 轻松适应新环境。 TrafficLLM适配器允许灵活的操作来更新旧模型或注册新任务。
model_name :基础模型的路径。
tuning_data :新的环境数据集。
adaptation_task :更新或注册(更新旧模型或注册新任务)。
task_name :要更新或插入的下游任务名称。
有一个使用恶意软件流量检测 (MTD) 任务更新 TrafficLLM 的示例。
电弧光等离子体增强傅里叶变换 python ea-peft.py --model_name /Your/Base/Model/Path --tuning_data /Your/New/Dataset/Path --adaptation_task update --task_name MTD
检查点:您可以尝试使用您自己的模型或我们发布的检查点来评估 TrafficLLM。
数据:在预处理步骤中,我们分割测试数据集并为不同数据集构建标签文件以进行评估。请参考预处理代码。
要测量 TrafficLLM 对不同下游任务的有效性,请运行评估代码。
model_name :基础模型的路径。
traffic_task :检测任务或生成任务。
test_file :在预处理步骤中提取的测试数据集。
label_file :在预处理步骤中提取的标签文件。
ptuning_path :用于特定任务评估的 PEFT 模型路径。
有一个对 MTD 任务进行评估的示例。
python评价.py --model_name /您的/基础/模型/路径 --traffic_task检测 --test_file数据集/ustc-tfc-2016/ustc-tfc-2016_detection_packet_test.json --label_file数据集/ustc-tfc-2016/ustc- tfc-2016_label.json --ptuning_path models/chatglm2/peft/ustc-tfc-2016-detection-packet/checkpoints-20000/
您可以在本地设备上部署 TrafficLLM。首先,在 config.json 中配置模型路径以注册从训练步骤收集的 PEFT 模型。有一个在 TrafficLLM 中注册 6 个任务的示例:
{ "model_path": "models/chatglm2/chatglm2-6b/", "peft_path": "models/chatglm2/peft/", "peft_set": { "NLP": "指令/checkpoint-8000/”,“MTD”:“ustc-tfc-2016-检测包/checkpoint-10000/”,“BND”:“iscx-botnet-2014-检测包/checkpoint-5000/”, “WAD”:“csic-2010-检测-数据包/checkpoint-6000/”,“AAD”:“dapt-2020-检测-数据包/checkpoint-20000/”,“EVD”:“iscx-vpn-2016-检测-packet/checkpoint-4000/”,“TBD”:“iscx-tor-2016-检测-packet/checkpoint-10000/”
}, "tasks": { "恶意软件流量检测": "MTD", "僵尸网络检测": "BND", "Web 攻击检测": "WAD", "APT 攻击检测": "AAD", "加密 VPN 检测”:“EVD”、“Tor 行为检测”:“TBD”
}
然后你应该在inference.py和trafficllm_server.py的prepromt函数中添加preprompt。前置提示是在特定于任务的流量调整期间训练数据中使用的前缀文本。
要在终端模式下与 TrafficLLM 聊天,您可以运行以下命令:
python inference.py --config=config.json --prompt="Your instructions Text +: + Traffic Data"
您可以使用以下命令启动 TrafficLLM 的网站演示:
streamlit run Trafficllm_server.py
该演示运行 TrafficLLM 的 Web 服务器。访问http://Your-Server-IP:Port在聊天框中聊天。
非常感谢 ChatGLM2 和 Llama2 的相关工作,它们为我们的框架和代码奠定了基础。 TrafficLLM的构建设计受到ET-BERT和GraphGPT的启发。感谢他们的精彩作品。