幸泰卫门
v0.7.6
一个开源、干净且可定制的 RAG UI,用于与您的文档聊天。构建时考虑到了最终用户和开发人员。
现场演示 |在线安装 |用户指南 |开发者指南 |反馈 |接触
该项目充当功能性 RAG UI,适用于想要对其文档进行 QA 的最终用户和想要构建自己的 RAG 管道的开发人员。
+------------------------------------------------ ---------------------------+|最终用户:使用“kotaemon”构建的应用程序的用户。 || (您使用类似于上面演示中的应用程序)|| +------------------------------------------------ ---------------+ || |开发者:那些用“kotaemon”构建的人。 | || | (您的项目中某处有“import kotaemon”)| || | +------------------------------------------------ ---+ | || | |贡献者:那些让“kotaemon”变得更好的人。 | | || | | (您对此存储库进行 PR)| | || | +------------------------------------------------ ---+ | || +------------------------------------------------ ---------------+ |+-------------------------------- --------------------------------------------------------+
干净简约的 UI :基于 RAG 的 QA 的用户友好界面。
支持各种 LLM :与 LLM API 提供商(OpenAI、AzureOpenAI、Cohere 等)和本地 LLM(通过ollama和llama-cpp-python )兼容。
易于安装:简单的脚本可让您快速入门。
RAG 管道框架:用于构建您自己的基于 RAG 的文档 QA 管道的工具。
可定制的 UI :使用使用 Gradio 构建的提供的 UI 查看 RAG 管道的运行情况。
Gradio 主题:如果您使用 Gradio 进行开发,请在此处查看我们的主题:kotaemon-gradio-theme。
托管您自己的文档 QA (RAG) Web UI :支持多用户登录、在私人/公共收藏中组织您的文件、与他人协作并分享您最喜爱的聊天。
组织您的 LLM 和嵌入模型:支持本地 LLM 和流行的 API 提供商(OpenAI、Azure、Ollama、Groq)。
混合 RAG 管道:Sane 默认 RAG 管道具有混合(全文和矢量)检索器和重新排名,以确保最佳检索质量。
多模式 QA 支持:通过图形和表格支持对多个文档进行问答。支持多模式文档解析(UI 上的可选选项)。
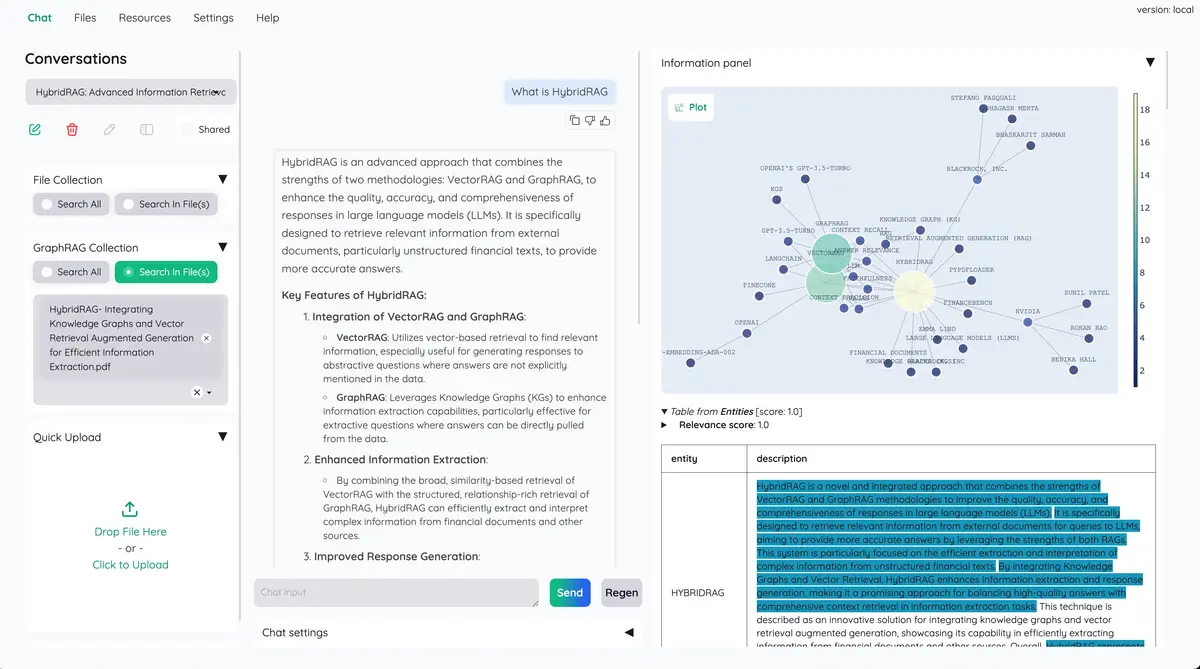
带文档预览的高级引文:默认情况下,系统将提供详细的引文,以确保LLM答案的正确性。直接在浏览器内的 PDF 查看器中查看您的引文(包括相关分数)并突出显示。当检索管道返回低相关文章时发出警告。
支持复杂的推理方法:使用问题分解来回答您的复杂/多跳问题。使用ReAct 、 ReWOO和其他代理支持基于代理的推理。
可配置的设置 UI :您可以在 UI 上调整检索和生成过程的最重要方面(包括提示)。
可扩展:基于 Gradio 构建,您可以根据需要自由定制或添加任何 UI 元素。此外,我们的目标是支持多种文档索引和检索策略。 GraphRAG索引管道作为示例提供。
如果您不是开发人员而只想使用该应用程序,请查看我们易于遵循的用户指南。下载最新版本的
.zip文件以获得所有最新功能和错误修复。
Python >= 3.10
Docker:可选,如果您使用 Docker 安装
如果您想要处理.pdf 、 .html 、 .mhtml和.xlsx文档以外的文件,则为非结构化。安装步骤因操作系统而异。请访问该链接并按照其中提供的具体说明进行操作。
我们支持lite和full版的 Docker 镜像。使用full ,还将安装额外的unstructured软件包,它可以支持其他文件类型( .doc , .docx ,...),但代价是更大的 docker 镜像大小。对于大多数用户来说, lite映像在大多数情况下都应该运行良好。
使用lite版。
码头运行 -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-lite
要使用full版。
码头运行 -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm ghcr.io/cinnamon/kotaemon:main-full
我们目前支持和测试两个平台: linux/amd64和linux/arm64 (适用于较新的 Mac)。您可以通过在docker run命令中传递--platform来指定平台。例如:
# 使用 linux/arm64docker run 平台运行 docker -e GRADIO_SERVER_NAME=0.0.0.0 -e GRADIO_SERVER_PORT=7860 -p 7860:7860 -it --rm --平台linux/arm64 ghcr.io/cinnamon/kotaemon:main-lite
一切设置正确后,您可以访问http://localhost:7860/访问 WebUI。
我们使用GHCR来存储docker镜像,所有镜像都可以在这里找到。
在新的 python 环境中克隆并安装所需的包。
# 可选(设置环境)conda create -n kotaemon python=3.10 conda 激活 kotaemon# 克隆此 repogit 克隆 https://github.com/Cinnamon/kotaemoncd kotaemon pip install -e "libs/kotaemon[all]"pip install -e "libs/ktem"
在此项目的根目录中创建一个.env文件。使用.env.example作为模板
.env文件用于服务用户希望在启动应用程序之前预先配置模型的用例(例如,在 HF 集线器上部署应用程序)。该文件仅用于在第一次运行时填充数据库一次,在后续运行中将不再使用。
(可选)要启用浏览器内的PDF_JS查看器,请下载 PDF_JS_DIST,然后将其解压到libs/ktem/ktem/assets/prebuilt
启动网络服务器:
蟒蛇应用程序.py
该应用程序将自动在您的浏览器中启动。
默认用户名和密码都是admin 。您可以直接通过 UI 设置其他用户。
检查Resources选项卡以及LLMs and Embeddings ,并确保.env文件中的api_key值设置正确。如果没有设置,可以在那里设置。
笔记
官方 MS GraphRAG 索引仅适用于 OpenAI 或 Ollama API。我们建议大多数用户使用 NanoGraphRAG 实现来与 Kotaemon 直接集成。
安装 nano-GraphRAG: pip install nano-graphrag
nano-graphrag安装可能会引入版本冲突,请参阅此问题
快速修复: pip uninstall hnswlib chroma-hnswlib && pip install chroma-hnswlib
使用USE_NANO_GRAPHRAG=true环境变量启动 Kotaemon。
在资源设置中设置默认的 LLM 和嵌入模型,NanoGraphRAG 会自动识别它。
非 Docker 安装:如果您不使用 Docker,请使用以下命令安装 GraphRAG:
pip 安装 graphrag 未来
设置 API KEY :要使用 GraphRAG 检索器功能,请确保设置GRAPHRAG_API_KEY环境变量。您可以直接在您的环境中执行此操作,也可以将其添加到.env文件中。
使用本地模型和自定义设置:如果您想将 GraphRAG 与本地模型(如Ollama )一起使用或自定义默认的 LLM 和其他配置,请将USE_CUSTOMIZED_GRAPHRAG_SETTING环境变量设置为 true。然后,调整settings.yaml.example文件中的设置。
请参阅本地模型设置。
默认情况下,所有应用程序数据都存储在./ktem_app_data文件夹中。您可以备份或复制此文件夹以将安装转移到新计算机。
对于高级用户或特定用例,您可以自定义这些文件:
flowsettings.py
.env
flowsettings.py该文件包含您的应用程序的配置。您可以使用此处的示例作为起点。
# 设置您的首选文档存储(具有全文搜索功能)KH_DOCSTORE=(Elasticsearch | LanceDB | SimpleFileDocumentStore)# 设置您的首选矢量存储(用于基于矢量的搜索)KH_VECTORSTORE=(ChromaDB | LanceDB | InMemory | Qdrant)# 启用/禁用多模式 QAKH_REASONINGS_USE_MULTIMODAL=True# 设置新的推理管道或修改现有的推理管道。KH_REASONINGS = ["ktem.reasoning.simple.FullQAPipeline","ktem.reasoning.simple.FullDecomposeQAPipeline","ktem.reasoning.react.ReactAgentPipeline","ktem .reasoning.rewoo.RewooAgentPipeline", ]
.env此文件提供了另一种配置模型和凭据的方法。
或者,您可以通过.env文件使用连接到 LLM 所需的信息来配置模型。该文件位于应用程序的文件夹中。如果您没有看到它,您可以创建一个。
目前,支持以下提供商:
使用ollama OpenAI兼容服务器:
将GGUF与llama-cpp-python一起使用
您可以从 Hugging Face Hub 搜索并下载要在本地运行的法学硕士。目前支持以下模型格式:
安装 ollama 并启动应用程序。
拉取您的模型,例如:
llama 拉 llama3.1:8b ollama 拉 nomic-embed-text
在 Web UI 上设置模型名称并将其设为默认值:
GGUF
您应该选择大小小于设备内存的型号,并应保留 2 GB 左右的空间。例如,如果您总共有 16 GB RAM,其中 12 GB 可用,那么您应该选择最多占用 10 GB RAM 的型号。较大的模型往往会产生更好的生成效果,但也会花费更多的处理时间。
以下是一些建议及其在内存中的大小:
Qwen1.5-1.8B-Chat-GGUF:约2 GB
使用 Web UI 上提供的模型名称添加新的 LlamaCpp 模型。
开放人工智能
在.env文件中,使用 OpenAI API 密钥设置OPENAI_API_KEY变量,以便能够访问 OpenAI 的模型。还有其他可以修改的变量,请随意编辑它们以适合您的情况。否则,默认参数应该适用于大多数人。
OPENAI_API_BASE=https://api.openai.com/v1 OPENAI_API_KEY=<此处为您的 OpenAI API 密钥>OPENAI_CHAT_MODEL=gpt-3.5-turbo OPENAI_EMBEDDINGS_MODEL=文本嵌入-ada-002
Azure 开放人工智能
对于通过 Azure 平台的 OpenAI 模型,您需要提供 Azure 端点和 API 密钥。您可能还需要提供聊天模型和嵌入模型的开发名称,具体取决于您设置 Azure 开发的方式。
AZURE_OPENAI_ENDPOINT= AZURE_OPENAI_API_KEY= OPENAI_API_VERSION=2024-02-15-预览 AZURE_OPENAI_CHAT_DEPLOYMENT=gpt-35-turbo AZURE_OPENAI_EMBEDDINGS_DEPLOYMENT=文本嵌入-ada-002
本地型号
在此处检查默认管道实现。您可以快速调整默认 QA 管道的工作方式。
在libs/ktem/ktem/reasoning/中添加新的.py实现,然后将其包含在flowssettings中以在 UI 上启用它。
检查libs/ktem/ktem/index/file/graph中的示例实现
(更多说明 WIP)。
由于我们的项目正在积极开发中,我们非常重视您的反馈和贡献。请参阅我们的贡献指南来开始。感谢我们所有的贡献者!