维基聊天室
v2.0!
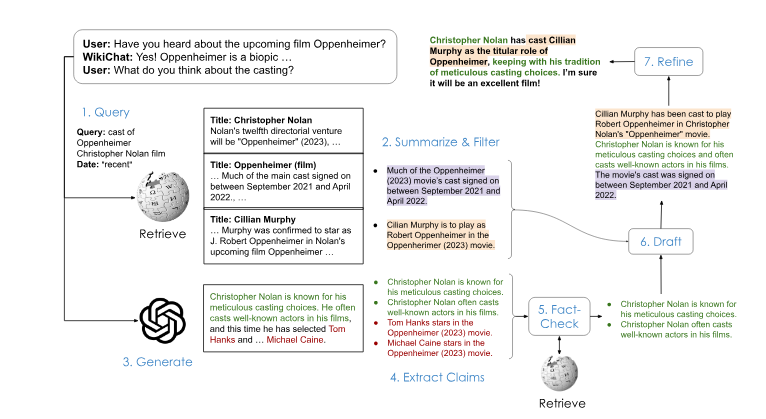
像 ChatGPT 和 GPT-4 这样的大型语言模型 (LLM) 聊天机器人经常会出错,特别是如果您正在查找的信息是最新的(“告诉我关于 2024 年超级碗”)或不太受欢迎的主题(“什么是 2024 年超级碗”)。 [插入您最喜欢的外国导演]有哪些值得观看的好电影?”)。 WikiChat 使用维基百科和以下 7 阶段管道来确保其响应是真实的。每个编号的阶段都涉及一个或多个 LLM 调用。

请查看我们的论文了解更多详细信息:Sina J. Semnani、Violet Z. Yao*、Heidi C. Zhu* 和 Monica S. Lam。 2023. WikiChat:通过维基百科上的少镜头基础来停止大型语言模型聊天机器人的幻觉。计算语言学协会的调查结果:EMNLP 2023,新加坡。计算语言学协会。
(2024 年 8 月 22 日)WikiChat 2.0 现已推出!主要更新包括:
除了文本之外,现在还支持从结构化数据(例如表格、信息框和列表)中进行检索。
拥有最高质量的公共维基百科预处理脚本
使用最先进的多语言检索模型 BGE-M3。
使用 Qdrant 进行可扩展矢量搜索。
使用 RankGPT 对搜索结果重新排名。
多语言支持:默认情况下,从 10 个不同的维基百科检索信息:??英语, ??中国人, ??西班牙语, ??葡萄牙语,??俄语,??德国人,??波斯语,??日本人, ??法语,还有??意大利语。
改进的信息检索
免费多语言维基百科搜索 API:我们提供高质量、免费(但有速率限制)的搜索 API,用于访问 10 个维基百科,包含超过 1.8 亿个向量嵌入。
扩展的 LLM 兼容性:借助 LiteLLM,通过统一界面支持 100 多个 LLM。
优化的管道:通过合并 WikiChat 的“生成”和“提取声明”阶段,可以选择更快、更具成本效益的管道。
LangChain兼容性:与LangChain完全兼容??️?。
还有更多!
(2024年6月20日)WikiChat荣获2024年维基媒体研究奖!
2024 年 @Wikimedia 年度研究奖颁给了“WikiChat:通过维基百科的几次尝试来阻止大型语言模型聊天机器人的幻觉”⚡
— 2024 年维基研讨会 (@wikiworkshop) 2024 年 6 月 20 日
? https://t.co/d2M8Qrarkw pic.twitter.com/P2Sh47vkyi
(2024 年 5 月 16 日)我们的后续论文“? SPAGHETTI: Open-Domain Question Answering from Heterogeneous Data Sources with Retrieval and Semantic Parsing”被 ACL 2024 的结果接受。这篇论文增加了对表格、信息框等结构化数据的支持和列表。
(2024 年 1 月 8 日)蒸馏 LLaMA-2 模型发布。您可以在本地运行这些模型,以更便宜、更快速的方式替代付费 API。
(2023 年 12 月 8 日)我们在 EMNLP 2023 上展示我们的工作。
(2023 年 10 月 27 日)我们论文的相机版本现已在 arXiv 上提供。
(2023年10月6日)我们的论文被EMNLP 2023的结果接受。
安装 WikiChat 涉及以下步骤:
安装依赖项
配置您选择的法学硕士。 WikiChat 支持 100 多个 LLM,包括来自 OpenAI、Azure、Anthropic、Mistral、HuggingFace、Together.ai 和 Groq 的模型。
选择信息检索源。这可以是符合retrieve/retriever_server.py 中定义的接口的任何HTTP 端点。我们提供以下选项的说明和脚本:
使用我们免费、限速的 10 种语言维基百科 API。
自行下载并托管我们提供的维基百科索引。
从您自己的文档创建并运行新的自定义索引。
使用您所需的配置运行 WikiChat。
[可选] 部署 WikiChat 以进行多用户访问。我们提供用于部署简单前端和后端的代码,以及连接到 Azure Cosmos DB 数据库以存储对话的说明。
该项目已在 Ubuntu 20.04 LTS (Focal Fossa) 上使用 Python 3.10 进行了测试,但它应该与许多其他 Linux 发行版兼容。如果您计划在 Windows WSL 或 macOS 上使用它,或者使用不同的 Python 版本,请准备好在安装过程中进行潜在的故障排除。
硬件要求根据您的预期用途而有所不同:
基本用法:使用 LLM API 和我们的维基百科搜索 API 运行 WikiChat 的硬件要求最低,并且应该适用于大多数系统。
本地搜索索引:如果您打算在本地托管搜索索引,请确保有足够的磁盘空间用于索引。对于大型索引,检索延迟在很大程度上取决于磁盘速度,因此我们建议使用 SSD,最好使用 NVMe 驱动器。例如,Azure 上的 Standard_L8s_v3 等存储优化型 VM 就适合于此。
本地 LLM:如果您计划将 WikiChat 与本地 LLM 一起使用,则需要 GPU 来托管模型。
创建新的检索索引:如果要对集合建立索引,则需要 GPU 将文档嵌入到向量中。默认嵌入模型 (BAAI/BGE-M3) 需要至少 13GB GPU 内存才能运行。
首先,克隆存储库:
git 克隆 https://github.com/stanford-oval/WikiChat.git cd 维基聊天
我们建议使用 conda_env.yaml 中指定的 conda 环境。此环境包括 Python 3.10、pip、gcc、g++、make、Redis 以及所有必需的 Python 包。
确保安装了 Conda、Anaconda 或 Miniconda。然后创建并激活conda环境:
conda env 创建 --文件 conda_env.yaml conda 激活维基聊天 python -m spacy download en_core_web_sm # 仅某些 WikiChat 配置需要 Spacy
如果运行聊天机器人后看到错误:Redis 查找失败,则可能意味着 Redis 未正确安装。您可以按照官方文档尝试重新安装。
对于所有后续命令,请保持此环境处于激活状态。
按照 https://docs.docker.com/engine/install/ 中的说明为您的操作系统安装 Docker。 WikiChat 主要使用 Docker 创建和提供用于检索的矢量数据库,具体来说?文本嵌入推理和 Qdrant。在最新的 Ubuntu 版本上,您可以尝试运行 inv install-docker。对于其他操作系统,请按照 docker 网站上的说明进行操作。
WikiChat 使用调用来添加用于各种目的的自定义命令。要查看所有可用命令及其描述,请运行:
调用--列表
或简写:
反相-l
有关特定命令的更多详细信息,请使用:
inv [命令名称] --help
这些命令在tasks/文件夹中实现。
WikiChat 与各种 LLM 兼容,包括 OpenAI、Azure、Anthropic、Mistral、Together.ai 和 Groq 的模型。您还可以通过 HuggingFace 将 WikiChat 与许多本地托管模型一起使用。
配置您的 LLM:
填写 llm_config.yaml 中的相应字段。
创建一个名为 API_KEYS 的文件(包含在 .gitignore 中)。
在 API_KEYS 文件中,设置要使用的 LLM 端点的 API 密钥。 API 密钥的名称应与您在 llm_config.yaml 中 api_key 下提供的名称匹配。例如,如果您通过 openai.com 和 Mistral 端点使用 OpenAI 模型,您的 API_KEYS 文件可能如下所示:
# 使用您的 API 密钥填写以下值。确保密钥后没有多余的空格。# git 会忽略对此文件的更改,因此您可以在开发过程中安全地将密钥存储在此处。OPENAI_API_KEY=[来自 https://platform.openai.com/ 的 OpenAI API 密钥API 密钥] MISTRAL_API_KEY=[来自 https://console.mistral.ai/api-keys/ 的 Mistral API 密钥]
请注意,本地托管模型不需要 API 密钥,但您需要在 api_base 中提供与 OpenAI 兼容的端点。该代码已经过测试?文本生成推理。
默认情况下,WikiChat 通过 https://wikichat.genie.stanford.edu/search/ 端点从 10 个维基百科检索信息。如果您只想尝试 WikiChat,则无需修改任何内容。
从 ? 下载 2024 年 8 月 1 日 10 种维基百科语言的索引?集线器并提取它:
inv 下载维基百科索引 --workdir ./workdir
请注意,该索引包含约 180M 向量嵌入,因此需要至少 500 GB 的空磁盘空间。它使用 Qdrant 的二进制量化将 RAM 要求降低至 55 GB,而不会牺牲准确性或延迟。
启动类似于选项 1 的 FastAPI 服务器来响应 HTTP POST 请求:
inv start-retriever --embedding-model BAAI/bge-m3 --retriever-port <端口号>
通过传入此检索器的 URL 来启动 WikiChat。例如:
inv demo --retriever-endpoint "http://0.0.0.0:<端口号>/search"
请注意,该服务器及其嵌入模型在 CPU 上运行,不需要 GPU。为了获得更好的性能,在兼容系统上,您可以添加 --use-onnx 以使用 ONNX 版本的嵌入模型,以显着降低嵌入延迟。
以下命令将下载、预处理库尔德维基百科的最新 HTML 转储并为其建立索引,我们在本示例中使用它是因为它的大小相对较小。
inv index-wikipedia-dump --embedding-model BAAI/bge-m3 --workdir ./workdir --语言 ku
将数据预处理为 JSON Lines 文件(文件扩展名为 .jsonl 或 .jsonl.gz),其中每行都具有以下字段:
{“id”:“整数”,“content_string”:“字符串”,“article_title”:“字符串”,“full_section_title”:“字符串”,“block_type”:“字符串”,“语言”:“字符串”,“ last_edit_date": "字符串(可选)", "num_tokens": "整数(可选)"}content_string 应该是文档的分块文本。我们建议将嵌入模型的分词器分块到少于 500 个分词。有关分块方法的概述,请参阅此内容。block_type 和 language 仅用于提供对搜索结果的过滤。如果不需要它们,只需将它们设置为 block_type=text 和 language=en 即可。该脚本会将 full_section_title 和 content_string 提供给嵌入模型以创建嵌入向量。
有关如何针对 Wikipedia HTML 转储实现此功能的详细信息,请参阅 preprocessing/preprocess_wikipedia_html_dump.py。
运行索引命令:
inv index-collection --collection-path <预处理 JSONL 的路径> --collection-name <名称>
此命令启动 docker 容器?文本嵌入推理(每个可用 GPU 一个)。默认情况下,它使用与Ampere 80架构的NVIDIA GPU兼容的docker镜像,例如A100。还可以支持其他一些 GPU,但您需要从可用的 docker 映像中选择正确的 docker 映像。
(可选)添加负载索引
python 检索/add_payload_index.py
这将启用根据语言或块类型进行过滤的查询。请注意,对于大型索引,索引可能需要几分钟才能再次可用。
建立索引后,按照选项 2 中的方式加载并使用索引。例如:
inv start-retriever --embedding-model BAAI/bge-m3 --retriever-port <端口号>curl -X POST 0.0.0.0:5100/search -H "Content-Type: application/json" -d '{" query": ["GPT-4 是什么?", "LLaMA-3 是什么?"], "num_blocks": 3}'通过传入此检索器的 URL 来启动 WikiChat。例如:
inv demo --retriever-endpoint "http://0.0.0.0:<端口号>/search"
将索引分成更小的部分:
tar -cvf -|猪Z-P 14 | split --bytes=10GB --numeric-suffixes=0 --suffix-length=4 - <输出文件夹的路径>/qdrant_index.tar.gz.part-
上传生成的部分:
python检索/upload_folder_to_hf_hub.py --folder_path <输出文件夹的路径> --repo_id
您可以使用以下命令运行 WikiChat 的不同配置:
inv demo --engine gpt-4o # 引擎可以是 llm_config 中配置的任何值,例如,mistral-large、claude-sonnet-35、local inv demo --pipelinegenerate_and_ Correct # 可用的管道有early_combine、generate_and_ Correct和retrieve_and_generate inv demo --Temperature 0.9 # 改变面向用户的阶段的温度,如细化
有关所有可用选项的完整列表,您可以运行 inv demo --help
该存储库提供了通过 Chainlit 部署基于 Web 的聊天界面的代码,并将用户对话存储到 Cosmos DB 数据库中。这些分别在 backend_server.py 和 database.py 中实现。如果要使用其他数据库或前端,则需要修改这些文件。对于开发来说,应该很简单地消除对 Cosmos DB 的依赖,并将对话简单地存储在内存中。您还可以配置 backend_server.py 中定义的聊天机器人参数,例如使用不同的 LLM 或添加/删除 WikiChat 的阶段。
通过Azure创建实例后,获取连接字符串并将该值添加到API_KEYS中。
COSMOS_CONNECTION_STRING=[您的 Cosmos DB 连接字符串]
运行此命令将启动后端和前端服务器。然后就可以在指定端口(默认为5001)访问前端。inv chainlit --backend-port 5001
您可以使用此 API 端点来构建高质量 RAG 系统的原型。请参阅 https://wikichat.genie.stanford.edu/search/redoc 了解完整规范。
请注意,我们不提供有关此端点的任何保证,并且它不适合生产。
(即将推出...)
我们公开发布 10 种语言的预处理维基百科。
WikiChat 2.0 与已发布的微调 LLaMA-2 检查点不兼容。目前请参考v1.0。
要评估聊天机器人,您可以使用用户模拟器模拟对话。子集参数可以是head、tail或recent之一,对应于WikiChat论文中介绍的三个子集。您还可以指定用户的语言(WikiChat 始终以用户的语言回复)。该脚本从相应的 benchmark/topics/{subset}_articles_{language}.json 文件中读取主题(即维基百科标题和文章)。使用 --num-dialogues 设置要生成的模拟对话的数量,使用 --num-turns 指定每个对话的回合数。
inv模拟用户--num-dialogues 1--num-turns 2--模拟模式通道--语言en--子集头
根据您使用的引擎,这可能需要一些时间。模拟对话和日志文件将保存在 benchmark/simulated_dialogues/ 中。您还可以提供上面的任何管道参数。您可以通过修改 benchmark/user_simulator.py 中的 user_characteristics 来试验不同的用户特征。
WikiChat 代码、模型和数据在 Apache-2.0 许可证下发布。
如果您使用过此存储库中的代码或数据,请引用以下论文:
@inproceedings{semnani-etal-2023-wikichat,title =“{W}iki{C}hat:通过基于{W}ikipedia的Few-Shot基础来停止大型语言模型聊天机器人的幻觉”,author =“Semnani,新浪和Yao、Violet 和张、Heidi 和 Lam、Monica”,编辑 =“Bouamor、Houda 和 Pino、Juan 和 Bali、Kalika”,书名 =“计算语言学协会的调查结果:EMNLP 2023”,月 = 12 月,年 = “2023”,地址=“新加坡”,出版商=“计算语言学协会”,url =“https://aclanthology.org/2023.findings-emnlp.157”,页面=“2387--2413”,
}@inproceedings{zhang-etal-2024-spaghetti,title =“{SPAGHETTI}:通过检索和语义解析从异构数据源进行开放域问答”,author =“Zhang、Heidi 和 Semnani、Sina 和 Ghassemi、Farhad 和Xu, Jialiang 和 Liu, Shi Cheng 和 Lam, Monica”,编辑 =“Ku,Lun-Wei 和 Martins,Andre 和 Srikumar,Vivek”,书名 =“计算语言学协会 ACL 2024 年的调查结果”,月 = 八月,年=“2024”,地址=“泰国曼谷和虚拟会议”,发布者=“计算语言学协会”,url =“https://aclanthology.org/2024.findings-acl.96”,pages =“1663- -1678",
}