TTS生成WebUI /口琴
下载安装程序||安装|| Docker设置||反馈 /错误报告
型号
| 文本到语音 | 音频/音乐发电 | 音频转换/工具 |
|---|
| 吠 | Musicgen | RVC |
| 龟 | 磁铁 | demucs |
| maha tts | 稳定的音频 | VOCOS |
| MMS | (扩展)即兴 | 耳语 |
| vall-e x | (扩展)Audiocraft Mac | |
| styletts2 | (扩展)Audiocraft Plus | |
| SeamlessM4T | | |
| (扩展)XTTSV2 | | |
| (扩展)MARS5 | | |
| (扩展)F5-TTS | | |
| (扩展)Parler TTS | | |
bark.narration.mp4 | bark.japanese.mp4 | Musicgen.mp4 |
|---|
ChangElog
11月23日:
- 添加Linux Fairseq Wheel以提高PIP兼容性。
11月22日:
11月15日:
- 升级到Gradio 5.5.5,添加类似于增强(#420)
11月14日:
- 添加实验性窗户深速车轮。
- 在树皮语音克隆中添加更多语言。
11月11日:
- 切换到固定的FairSeq版本,以减少安装冲突并加速更新。
2024年10月
10月28日:
- 添加了安装程序测试,模型下载器和pip cpu-for Torch选项。
10月24日:
- 由于错误,将Gradio降低到5.1.0。
- 添加了测试工作流和固定次要错误。
10月22日:
10月21日:
- 重新设计的读书文件:改进的耳语扩展,添加了8月,9月和10月的更改,更新了屏幕截图,并重新组织了内容。
10月19日:
10月18日:
- 系统改进:格式化项目,固定
xformers+cuda安装,添加的日志系统,卸载扩展按钮和F5 TTS扩展。
10月16日:
- 现在,首先安装使用
pip代替uv 。 - 碰撞主要版本并修复了Google Colab。
- 将PIP后备添加到稳定的音频中。
- 修复了DEMUC,更改了Postgres端口。
- 修复了
huggingface_hub安装和树皮型号加载器。 - 重大升级:切换到Gradio 5,用于选项卡,Docker Fixes,优化的UI速度,添加.ENV.USER功能,改进的日志和升级的React React UI扩展名。
10月3日:
- 修复了GPU信息选项卡并添加了
nvidia-ml-py 。 - 为Audiocraft Install Bug创建了解决方法。
- 修复了自动MSVC安装,并将服务器设置为
127.0.0.1 。 - 修复了
.git_version路径并删除了iconv ,以消除node-gyp要求。 - 改进的安装程序错误处理,添加升级哈希记录。
- 将node.js升级到22.9.0,添加了postgresql支持,在react ui中分组的选项卡。
2024年9月
单击以展开
9月23日:
9月22日:
- 添加了FFMPEG元数据扩展以反应UI。
- 为Maha TTS添加了单一通知。
- HotFix避免节点20.17.0安装失败。
9月21日:
9月19日:
- 升级的React React UI视觉外观具有新的滑块和更好的布局。
- 优化了RVC UI,修复了Colab,并添加了一个搜索命令框。
- 升级Node.js至20.17.0。
9月2日:
- 修复了Dockerfile和更新的Docker-Compose.yml。
- 修复了NPZ加载中的错误。
2024年8月
单击以展开
8月31日:
- 升级模型推理框架为装饰器。
- 将Python文件从
src移至tts_webui文件夹。 - 重写MusicGen选项卡并修复了相关的错误。
8月20日:
- 升级为Gradio 4并添加了主题。
- 添加了为乌龟加载消息的模型。
- 固定了ReactUI的RVC。
- 重构超参数。
- 将管理添加到扩展名列表,XTTS-Simple扩展名。
8月5日:
- 修复React UI中的树皮,添加最大生成持续时间。
- 更改Audiocraft加上扩展模型目录为./data/models/audiocraft_plus/
- 改善MusicGen和Audiogen的模型卸载。将卸载型号按钮添加到MusicGen和Audiogen。
- 添加HuggingFace高速缓存管理器扩展。
8月4日:
- 添加XTTS-RVC-UI扩展名,XTTS微调演示扩展。
8月3日:
- 添加即兴扩展,Audiocraft MAC扩展,树皮遗产扩展。
8月2日:
- 将折旧警告添加到旧安装程序中。
- 统一错误处理和简化选项卡加载。
8月1日:
- 为外部扩展添加“尝试更新”按钮。
- 当不更改pip_packages版本时,跳过重新安装软件包。
- 将Gradio端口与React UI同步。
- 将默认的Gradio端口从7860更改为7770。
2024年7月
单击以展开
7月31日:
- Fix React React UI的MusicGEN发生变化后。
- 添加卸载按钮以窃窃私语。
7月29日:
- 将FFMPEG从Conda-Forge更改为4.4.2,以支持包括Mac M1在内的更多平台。
- 禁用乌龟CVVP。
7月26日:
- 耳语延伸
- 实验AMD ROCM安装支持。 (仅Linux)
7月25日:
- 添加用于MacOS和Linux的诊断脚本。
- 为选项卡添加更好的错误详细信息。
- 修复了Linux和MacOS上安装程序的.SH脚本执行权限。
7月21日:
- 添加画廊历史扩展(从旧画廊视图改编)
- 将简单的混音器转换为扩展程序
- FIX update.py使用较新的火炬版本(update.py仅用于遗产目的,可能会破裂)
- 添加诊断脚本并为Windows重新安装脚本。
7月20日:
- 修复Discord加入链接
- 进一步简化树皮,消除代码中过度复杂性。
- 添加UI/模块化扩展,这些扩展允许在UI上安装新的型号和功能。将来,模型将以扩展为启动,然后再添加。
- 输出中禁用画廊视图
- 已知问题:Firefox未能显示出Gradio的输出,从而从后端获取它们失败了。在React UI中,这可以正常工作。
7月15日:
- 评论 - 随着React UI已经很长时间了,Gradio UI将只能为用户提供功能,而没有极为复杂的UI无法处理的功能。开发时间确实缺乏增加新的模型和功能,但是旧的集成方式并不可行。由于定义了新的API和“模型的作用”,因此可以为整个模型具有扩展名,从而更加灵活性和更轻的安装。
- 开始缩放缩放Gradio UI复杂性 - 删除发送到RVC/DEMUC/语音按钮。 (删除内部组件Joutai)。
- 添加版本。将来以获得更好的更新。
- 将Gradio Bark的最大输出数减少到1。
- 将卸载模型按钮添加到乌龟中,还要在加载下一个/更改参数之前卸载模型,因此乌龟在设置时不再使用2X模型存储器。
7月14日:
- 重组级别选项卡成组 - 文本到语音,音频转换,音乐生成,输出和设置
- 清理标题,添加链接以进行反馈
- 将种子控制添加到稳定的音频
- 用新线修复稳定的音频文件名错误
- 禁用“简单混音” Gradio选项卡
- 再次修复树皮语音克隆和RVC
- 添加用于调试的“已安装软件包”选项卡
7月13日:
- 大量升级到火炬2.3.1和Xformers 0.0.27
- 现在,包括Mac和CPU在内的所有用户现在都具有相同的Pytorch版本。
- 将CUDA升级到11.8
- 强制Python为3.10.11
- 修改安装程序以允许升级Python和Torch而不重新安装(当前主要版本2)
- 修复磁铁默认参数以提高质量
- 改进安装程序脚本检查以避免错误
- 更新STYLETTS2
7月11日:
- 改善稳定的音频生成文件名
- 将力重新安装到火炬修复中
- 在运行之前将安装程序自动更新
7月9日:
- https://github.com/xeraster修复了新的安装程序和安装说明!
7月8日:
- 更改安装过程,以减少包装冲突并启用火炬版本灵活性。
7月6日:
- 新的基于MAMBA的安装程序的初始版本。
- 将稳定的音频结果保存到Outputs-RVC/StableAudio文件夹中。
- 将免责声明添加到稳定的音频模型选择中,并在丢失文件时显示更好的错误消息。
7月1日:
- 一代后优化稳定的音频内存使用。
- 仅当Gradio也自动打开时,Open React UI会自动。
- 删除不必要的conda git重新安装。
- 更新到具有国会议员支持的LAST稳定音频(需要更新的火炬版本)。
2024年6月
单击以展开
6月22日: *将稳定音频添加到Gradio中。 6月21日:
- 添加vall-ex演示以反应UI。
- 在浏览器中自动打开React UI,再次修复链接。
- 添加长度分开以反应/乌龟。
- 修复UVR5演示文件夹。
- 将FairSeq版本设置为Linux和Mac的0.12.2。 (#323)
- 改善所有React UI选项卡的发电历史记录。
5月17日:
5月9日:
- 添加MMS以反应UI。
- 改进React UI和代码库。
5月4日:
2024年4月
单击以展开
4月28日: *添加maha tts以反应UI。 *添加GPU信息以进行反应UI。 4月6日:
- 添加vall-ex生成演示选项卡。
- 添加MMS演示选项卡。
- 添加Maha TTS演示选项卡。
- 添加STYLETTS2演示选项卡。
4月5日:
- 修复RVC安装错误。
- 添加基本UVR5演示选项卡。
4月4日:
- 升级RVC包括RVMPE和FCPE。由于文件重复,删除模型和索引的直接文件输入。改进RVC的React UI接口。
2024年3月
单击以展开
3月28日:
3月27日:
3月26日:
3月22日:
- VALL-E X演示通过笔记本(#292)
- 将React UI添加到Docker图像
- 添加安装免责声明
3月16日:
3月14日:
3月13日:
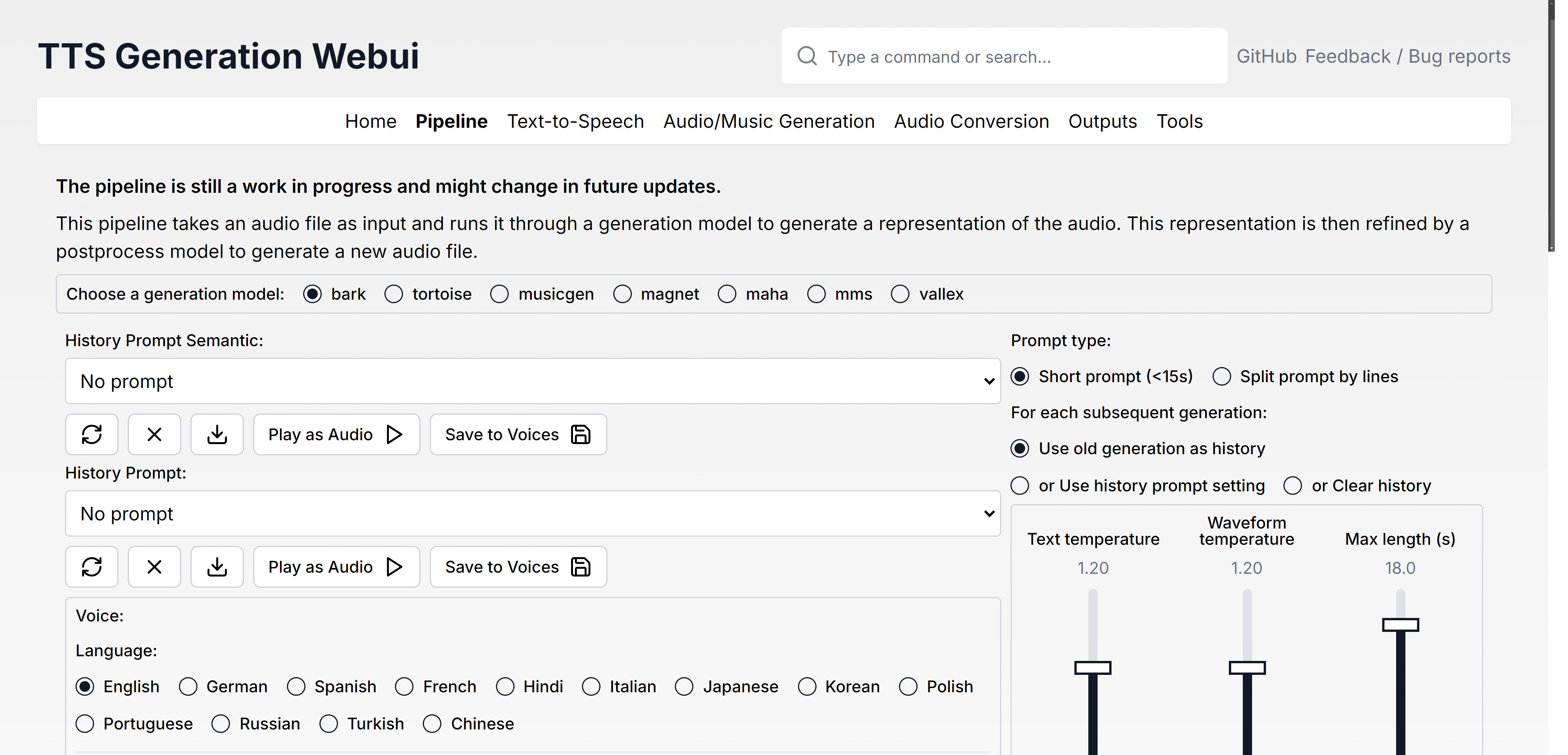
- 添加实验管道(bark / tortoise / musicgen / audiogen /磁铁 - > rvc / demucs / vocos)(#287)
- 用模型重新加载在每一代中修复RVC错误。对于简短的输入,会导致可见的加速。
3月11日:
- 添加为音频播放,然后将声音保存到树皮(#286)
- 更改UX以显示文件已从收藏夹中删除
- 修复未显示的树皮声音的图像
- 将音频播放修复到收藏夹中
3月10日:
- 将批处理添加到React UI磁铁(#283)
- 将音频翻译添加到SeamlessM4T(#284)
3月5日:
- 添加批处理为UI Musicgen(#281),多亏了https://github.com/aamir3d请求此信息并提供反馈
3月3日:
- 添加MMS演示作为笔记本
- 添加MultibandDiffusion高VRAM免责声明
2024年2月
单击以展开
2月21日:
- 使用Docker-audiocraft修复Docker容器构建和错误
2月8日:
- 修复Musicgen的立体模型的多键式插图,谢谢https://github.com/mykeehu
- 修复Google Colab上的Node.js安装步骤,https://github.com/miaohf代码
2月6日:
- 通过https://github.com/joachip添加FLAC文件生成扩展
2024年1月
单击以展开
1月21日:
- 在每个更新中添加CPU/M1 TORCH自动修复脚本。要禁用,编辑check_cuda.py并更改force_no_repair = true
1月16日:
- 升级音乐,增加了对立体声和大型旋律模型的支持
- 添加磁铁
1月15日:
- 将Gradio升至3.48.0
- 出现了几个视觉错误,如果它们很关键,请报告它们或降级Gradio。
- Gradio:压制无用的警告
- Supress Triton警告
- Gradio-Bark:修复“将最后一代用作历史记录”行为,空选择不再错误
- 改善扩展程序装载机显示器
- 从4.31.0升级到4.36.1
- 添加SeamlessM4T演示
1月14日:
1月13日:
- React UI:修复了自动安装中缺少NPM构建步骤
1月12日:
- React UI:修复音频动作的名称
- Gradio:修复多个API警告
- 集成 - React UI现在与Gradio一起启动,并具有打开它的链接
1月11日:
1月9日:
- 反应UI
- 修复404处理程序的WaveSurfer
- 小组树皮选项卡在一起
1月8日:
2023
单击以展开
2023年10月
10月26日:
10月24日:
- 为MusicGen和Demucs添加初始React UI(#202)
- 修复树皮长的种子漂移(感谢https://github.com/520pig520)
2023年9月
9月21日:
- 树皮:添加继续作为语义历史记录按钮
- 切换到GitHub Docker Image Storage,新Docker图像:
-
docker pull ghcr.io/rsxdalv/tts-generation-webui:main
- fix server_port选项在配置#168中,感谢https://github.com/dartvauder
9月9日:
- 修复XDG-OPEN命令行,感谢https://github.com/jfronny
- 修复多行树皮世代,感谢https://github.com/slack-t和https://github.com/bkutasi
- 按照https://github.com/aamir3d的要求将卸载模型按钮添加到树皮
- 根据https://github.com/maki9009添加红色的细节到readme_bark.md
- 添加“可选”及时燃烧,多亏https://github.com/maki9009
9月5日:
- 将声音混合添加到树皮
- 添加V1烧伤提示为吠叫(燃烧在提示中是用于指导语义模型而无需花费时间生成音频。V1通过生成语义令牌,然后将其用作语义模型的提示来起作用。)
- 将生成长度限制器添加到树皮
2023年8月
8月27日:
8月26日:
- 将发送到RVC,DEMUCS,VOCOS按钮和VOCOS添加到RVC,VOCOS按钮
8月24日:
- 将日期添加到RVC输出中以修复#147
- 修复Safetensors缺少车轮
- 将发送到demucs按钮添加到Musicgen
8月21日:
- 添加Torchvision安装到Colab中以进行Musicgen问题修复
- 删除RVC_TAB文件记录
8月20日:
8月18日:
- CI:添加GitHub操作以自动发布Docker映像。
8月16日:
8月15日:
- 在所有需求中,pin torch to 2.0.0.txt文件
- 颠簸的听力和树皮版本
- 从Colab中删除乌龟变压器修复
- 将乌龟更新为2.8.0
8月13日:
8月11日:
- 感谢Manmay-Nakhashi的乌龟热五十条
- 添加乌龟选项以更改令牌
8月8日:
- 更新听力,改善多型延伸性能
- 修复乌龟参数“ cond_free”与“ ultra_fast”预设的不匹配
8月7日:
8月6日:
- 修复Audiogen + MBD错误,为Colab添加乌龟修复
8月4日:
- 添加多键式选项到Musicgen#109
- MusicGen/Audiogen将代币作为.NPZ文件保存。
8月3日:
8月2日:
2023年7月
7月26日:
- 语音库
- 语音裁剪
- 修复语音重命名错误,重命名图片,添加哈希文本框
- 更容易下载声音(#98)
7月24日:
- 更改树皮文件格式以包含历史记录哈希:... contun_generation ... - > ... from_3ea0d063 ...
7月23日:
- docker图像感谢https://github.com/jonfairbanks
- RVC UI命名改进
7月21日:
- 修复Hubert不仅与CPU合作(#87)
- 添加Google COLAB演示(#88)
- 新设置选项卡和模型位置(适用于高级用户)(#90)
7月19日:
- 添加乌龟优化,谢谢https://github.com/manmay-nakhashi#79(实施#18)
7月16日:
- 语音照片演示
- 将目录添加到存储RVC模型/索引和下拉列表中
- 解决RVC不尊重CPU#74的IS_HALF
- 乌龟模型和语音选择改进#73
7月10日:
7月9日:
- RVC Demo + Tortoise,带更新脚本的V6安装程序和自动尝试安装额外模块#66
7月5日:
7月2日:
7月1日:
2023年6月
6月29日:
6月27日:
6月20日
6月19日
6月18日:
6月14日:
6月5日:
- 修复Bark生成页面上的“保存到收藏夹”按钮,清理控制台(v4.1.1)
- 添加“收集”选项卡,用于管理几个不同的数据集和更容易的趋势。
6月4日:
6月3日:
- 更新到V4-新的输出结构,改进的历史记录视图,代码库重组,改进的元数据,输出扩展支持支持
2023年5月
5月21日:
5月17日:
- 更新到V2 - 生成结果时产生结果,逐行预览较长的提示世代,启用多达9个输出,UI调整
5月16日:
- 添加Gradio设置选项卡,修复控制台中的Gradio错误,改进日志记录。
- 使用“用作语音”和“保存语音”按钮更新历史记录和收藏夹
- 添加声音选项卡
- 树皮选项卡:删除“或将最后一代用作历史记录”
- 改善代码组织
5月13日:
- 启用确定性生成并增强生成的日志。信用Suno-ai/树皮#175。
5月10日:
- 启用可能从老一辈重复历史提示的可能性。将几代保存为NPZ文件。添加一种方便的方法,用于为下一个提示重用最近3代中的任何一个。添加一个按钮,用于保存和收集历史记录提示 /声音。 #10
5月4日:
- 长期生成(信用https://github.com/suno-ai/bark/blob/main/notebooks/long_form_generation.ipynb and suno-ai/bark#161)
- 适应固定的env var错误
5月3日:
- 改进的乌龟UI:语音,预设和CVVP设置以及产生3个结果的能力(#6)
5月2日:
- 增加了对历史记录回收的支持,以继续手动提示更长的提示
- 增加了对V2提示的支持
前:
升级(用于旧安装)
如果出现问题,请随时与开发人员联系。
单击以展开
从V6升级到新安装程序
推荐:新安装
- 下载新版本并运行start_tts_webui.bat(Windows)或start_tts_webui.sh(MacOS,Linux)
- 完成后,关闭服务器。
- 推荐:将旧几代复制到新目录,例如收藏夹/输出/ outputs-rvc/ models/ collections/ config.json
- 谨慎:您可以将全新的TTS生成Webui目录复制到旧的TTS-Generation-Webui目录,但可能会丢失一些旧文件。
就地升级,可以删除一些文件,调整
- 使用update_平台脚本更新现有安装
- 更新后运行新的start_tts_webui.bat(Windows)或start_tts_webui.sh(macos,linux)在tts-generation-webui目录内
- 服务器启动后,检查是否有效。
- 谨慎:如果新服务器有效,则在单键式插件目录中删除旧的installer_files。
还有其他最佳方法可以做到吗?
不确定的是,依赖关系发生冲突,尤其是在康达(Conda)和python之间(依赖项已经处于临界状态,将其转移到康达(Conda)是途中的)。因此,虽然有可能只用新的安装程序替换旧安装程序并运行更新,但问题是无法预测和不可修复的。对安装程序进行更新需要大量的测试,因此不会轻易完成。
安装
- 下载最新版本并提取。
- 运行start_tts_webui.bat或start_tts_webui.sh启动服务器。它会要求您选择所使用的GPU/芯片。一旦安装了所有内容,它将在http:// localhost:7770和http:// localhost:3000的React UI上启动Gradio服务器。
- 输出日志将在installer_scripts/output.log文件中可用。
手动安装(不建议)
这些说明可能无法反映所有最新的修复和调整,但可作为调试或理解安装程序的参考。希望它们可以成为支持新平台(例如AMD/Intel)的基础。
安装Conda(https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html)
- (Windows)安装Visual Studio编译器/Visual Studio构建工具
建立环境: conda create -n venv
安装git,node.js conda install -y -c conda-forge git python=3.10.11 conda-forge::nodejs=22.9.0 conda pip==23.3.2 conda-forge::uv=0.4.17 conda-forge::vswhere
a)要么继续使用安装程序脚本
- 激活环境:
conda activate venv和 (venv) node installer_scriptsinit_app.js- 然后使用
(venv) python server.py运行服务器
b)或手动安装要求
- 使用CUDA或CPU设置Pytorch(https://pytorch.org/audio/stable/build.windows.html#install-pytorch):
-
(venv) conda install -y -k conda-forge::uv=0.4.17 conda-forge::vswhere conda-forge::postgresql=16.4 conda-forge::nodejs=22.9.0 conda-forge::ffmpeg=4.4.2[build=lgpl*] pytorch=2.3.1 torchvision torchaudio cpuonly -c pytorch for CPU/MAC -
(venv) conda install -y -k conda-forge::uv=0.4.17 conda-forge::vswhere conda-forge::postgresql=16.4 conda-forge::nodejs=22.9.0 conda-forge::ffmpeg=4.4.2[build=lgpl*] pytorch[version=2.3.1,build=py3.10_cuda11.8*] pytorch-cuda=11.8 torchvision torchaudio cuda-toolkit ninja -c pytorch -c nvidia/label/cuda-11.8.0 -c nvidia for cuda
- 克隆回购:
git clone https://github.com/rsxdalv/tts-generation-webui.git - 安装要求:
- 安装所有要求*.txt(此列表可能不是最新的,请检查https://github.com/rsxdalv/tts-generation-webui/blob/main/main/main/dockerfile#l39-l40):
-
(venv) pip install -r requirements.txt -
(venv) pip install -r requirements_audiocraft.txt -
(venv) pip install -r requirements_bark_hubert_quantizer.txt -
(venv) pip install -r requirements_rvc.txt -
(venv) pip install hydra-core==1.3.2 -
(venv) pip install -r requirements_styletts2.txt -
(venv) pip install -r requirements_vall_e.txt -
(venv) pip install -r requirements_maha_tts.txt -
(venv) pip install -r requirements_stable_audio.txt -
(venv) pip install soundfile==0.12.1 -
(venv) pip install nvidia-ml-py
- 构建React App :(
(venv) cd react-ui && npm install && npm run build
- (可选)设置数据库:(
(venv) node installer_scripts/js/applyDatabaseConfig.js - 运行服务器:(
(venv) python server.py
反应UI
- 安装nodejs(如果尚未使用conda安装)
- 安装反应依赖性:
npm install - 构建React:
npm run build - Run React:
npm start - 还运行Python服务器:
python server.py或使用start_tts_webui脚本
Docker设置
TTS生成 - Webui也可以在Docker容器内部运行。要开始,请从github容器注册表中取出图像:
docker pull ghcr.io/rsxdalv/tts-generation-webui:main
一旦拉动图像,可以从Docker组成的开始:
在后台下载模型时,容器将花费一些时间来生成第一个输出。可以通过检查容器日志来验证此下载的状态:
docker logs tts-generation-webui
自己构建图像
如果您想构建自己的Docker容器,则可以使用随附的Dockerfile:
docker build -t tts-generation-webui .
请注意,需要编辑Docker-Compose才能使用您刚刚构建的图像。
树皮的额外声音,提示样品
树皮雷德姆
readme_bark.md
有关AI项目的管理模型,缓存和系统空间的信息
#186(在线程中回复)
开源库
该项目利用以下开源库:
道德和负责任的使用
该技术旨在实现促进和创造力,而不是危害。
通过与这种AI模型互动,您承认并同意遵守这些准则,以负责任的,道德和法律的方式采用AI模型。
- 非恶意的意图:请勿将此AI模型用于恶意,有害或非法活动。它只能用于合法和道德目的,以促进积极参与,知识共享和建设性对话。
- 没有模仿:不要使用这种AI模型来冒充或虚假陈述自己作为其他人,包括个人,组织或实体。它不应用来欺骗,欺诈或操纵他人。
- 没有欺诈活动:这种AI模型不得用于欺诈目的,例如财务骗局,网络钓鱼尝试或任何形式的欺骗性实践,旨在获取敏感信息,货币收益或未经授权的系统访问。
- 法律合规:确保您使用此AI模型符合有关AI使用,数据保护,隐私,知识产权以及您管辖范围内的任何其他相关法律义务的适用法律,法规和政策。
- 致谢:通过使用这种AI模型,您承认并同意以负责任,道德和法律方式使用AI模型,并同意遵守这些准则。
执照
代码库和依赖项
该代码库是根据MIT许可的。但是,重要的是要注意,在安装依赖项时,您也将受到各自的许可。尽管这些许可证中的大多数都是允许的,但可能没有一些许可证。因此,必须了解,允许许可仅适用于代码库本身,而不是整个项目。
话虽如此,目的是在整个项目中保持MIT兼容性。如果您遇到与MIT许可证不兼容的依赖性,请随时打开问题并引起我们的注意。
已知的非允许依赖性:
| 图书馆 | 执照 | 笔记 |
|---|
| Eccodec | CC BY-NC 4.0 | 较新的版本是麻省理工学院,但需要手动安装 |
| diffq | CC BY-NC 4.0 | 将来可以卸载的可选,不需要运行,应使用demucs更新 |
| la脚 | GPL许可证 | 未来版本将使它成为LGPL,但需要手动安装 |
| UNIDECODE | GPL许可证 | 不关键的任务可以用另一个图书馆代替:Neonbjb/Tortoise-TTS#494 |
模型重量
模型权重有不同的许可证,请注意您使用的模型的许可。
最值得注意的是:
- 树皮:麻省理工学院
- 乌龟:未知(根据repo的apache-2.0,但在拥抱面中没有许可证文件)
- Musicgen:CC BY-NC 4.0
- Audiogen:CC BY-NC 4.0
兼容性 /错误
Audiocraft目前仅与Linux和Windows兼容。 MacOS支持仍然没有到达,尽管可以手动安装。
火炬被重新安装
由于Python软件包管理器(PIP)限制,火炬可以重新安装多次。这是PIP和火炬的广泛问题。
控制台中的红色消息
这些消息:
---- requires ----, but you have ---- which is incompatible.
完全正常。这既是PIP的限制,又是因为此Web UI将许多不同的AI项目结合在一起。由于这些项目并不总是彼此兼容,因此他们会抱怨安装的其他项目。这是正常且预期的。最后,尽管有警告/错误,项目仍将共同起作用。目前尚不清楚这种情况是否可以解决,但这是希望。