IncarnaMind
1.0.0
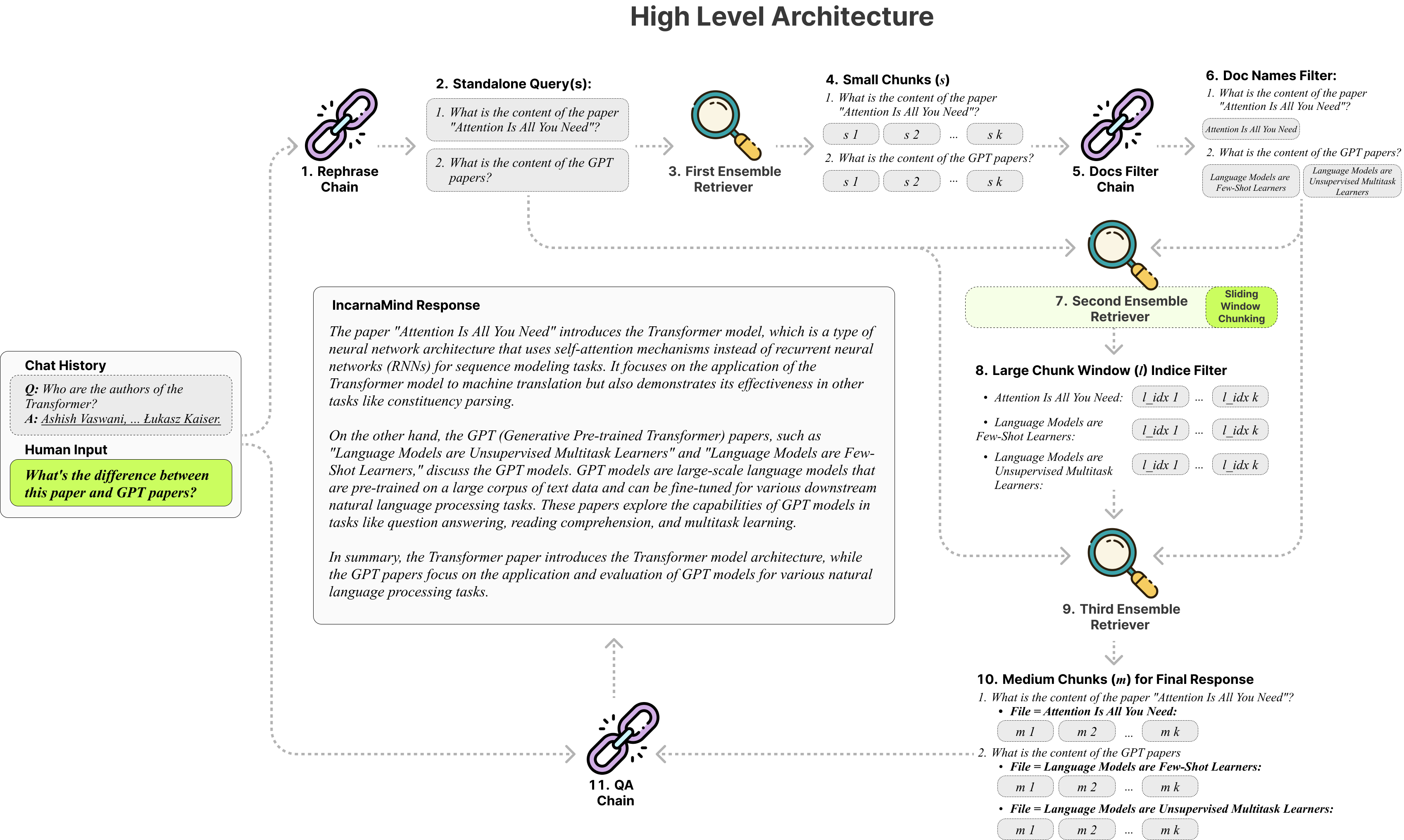
Uncarnamind使您可以与您的个人文件聊天? (PDF,TXT)使用大型语言模型(LLM)(例如GPT)(架构概述)。虽然OpenAI最近推出了用于GPT模型的微调API,但它并不能使基本概括的模型能够学习新数据,并且响应可能容易出现事实幻觉。利用我们的滑动窗口块机制和集合回收刀可以在地面真相文档中有效查询细粒度和粗粒的信息,以增强LLMS。
随时使用它,我们欢迎任何反馈和新功能建议吗?
这是我测试过的不同模型的比较表,仅参考:
| 指标 | GPT-4 | GPT-3.5 | 克劳德2.0 | Llama2-70B | LLAMA2-70B-GGUF | Llama2-70b-api |
|---|---|---|---|---|---|---|
| 推理 | 高的 | 中等的 | 高的 | 中等的 | 中等的 | 中等的 |
| 速度 | 中等的 | 高的 | 中等的 | 非常低 | 低的 | 中等的 |
| GPU RAM | N/A。 | N/A。 | N/A。 | 很高 | 高的 | N/A。 |
| 安全 | 低的 | 低的 | 低的 | 高的 | 高的 | 低的 |
固定块:传统的抹布工具依靠固定的块大小,从而将其适应性限制在处理不同的数据复杂性和上下文中。
精度与语义:当前的检索方法通常集中于语义理解或精确检索,但很少两者兼而有之。
单案限制:许多解决方案一次只能一次查询一个文档,从而限制多文件信息检索。
稳定性:Incarnamind与Openai GPT,人类Claude,Llama2和其他开源LLM兼容,可确保稳定的解析。
自适应块:我们的滑动窗口块技术可以动态调整窗口的大小和位置,以基于数据复杂性和上下文平衡细粒度和粗粒的数据访问。
多文件对话质量质量检查:同时支持多个文档跨多个文档的简单和多跳的查询,从而打破了单文件限制。
文件兼容性:支持PDF和TXT文件格式。
LLM模型兼容性:支持OpenAI GPT,人类Claude,Llama2和其他开源LLM。

安装很简单,您只需要运行几个命令即可。
git clone https://github.com/junruxiong/IncarnaMind
cd IncarnaMind创建conda虚拟环境:
conda create -n IncarnaMind python=3.10激活:
conda activate IncarnaMind安装所有要求:
pip install -r requirements.txt如果您想运行量化的本地LLM,请安装Llama-CPP。
NVIDIA GPU支持,请使用cuBLAS CMAKE_ARGS= " -DLLAMA_CUBLAS=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dirM1/M2 )支持,请使用CMAKE_ARGS= " -DLLAMA_METAL=on " FORCE_CMAKE=1 pip install llama-cpp-python==0.1.83 --no-cache-dir在configparser.ini文件中设置您的一个/所有API键:
[tokens]
OPENAI_API_KEY = (replace_me)
ANTHROPIC_API_KEY = (replace_me)
TOGETHER_API_KEY = (replace_me)
# if you use full Meta-Llama models, you may need Huggingface token to access.
HUGGINGFACE_TOKEN = (replace_me)(可选)在configparser.ini文件中设置自定义参数:
[parameters]
PARAMETERS 1 = (replace_me)
PARAMETERS 2 = (replace_me)
...
PARAMETERS n = (replace_me)将所有文件(请正确命名每个文件以最大化性能命名)中的/数据目录,然后运行以下命令摄入所有数据:(您可以在运行命令之前删除/数据目录中的示例文件)
python docs2db.py为了开始对话,请运行一个命令:
python main.py等待脚本需要下面的输入。
Human:当您开始聊天时,系统将自动生成一个incarnamind.log文件。如果要编辑日志记录,请在configparser.ini文件中进行编辑。
[logging]
enabled = True
level = INFO
filename = IncarnaMind.log
format = %(asctime)s [%(levelname)s] %(name)s: %(message)s特别感谢Langchain,Chroma DB,Lastgpt,Llama-CPP对开源社区的宝贵贡献。他们的作品在使哥伦布项目成为现实方面发挥了作用。
如果您想引用我们的工作,请使用以下Bibtex条目:
@misc { IncarnaMind2023 ,
author = { Junru Xiong } ,
title = { IncarnaMind } ,
year = { 2023 } ,
publisher = { GitHub } ,
journal = { GitHub Repository } ,
howpublished = { url{https://github.com/junruxiong/IncarnaMind} }
}Apache 2.0许可证


