网站是指在因特网上根据一定的规则,使用HTML等制作的用于展示特定的内容相关的网页集合。
网页是网站中的一“页”。通常是HTML 格式的文件,它要通过浏览器来阅读。
网页其实就是放在服务器上的一个文件,当我们浏览网页时,这个文件会被下载到我们本地的电脑,然后再由浏览器解析,渲染出各种漂亮的界面,比如表格、图片、标题、列表等。
网页文件的后缀有很多种,比如.html、.php、.jsp、.asp等,相信读者在浏览器的地址栏里也都见到过,如下图所示:


可以在浏览器地址栏中查看 URL
但不管网页的后缀是什么,它的本质都是一样的,就是由 HTML 代码构成的纯文本文件。
我们可以使用记事本、Notepad++、Sublime Text、Vim 等文本编辑器打开网页文件,看到它的所有内容,就像下面这样:
<!DOCTYPEhtml><html><head><metacharset=UTF-8><title>这个位置是网页的标题</title></head><body><p>这个位置是网页的内容文本</p><ahref=http://dotcpp.com/>这个位置是一个超链接</a><ul><li>项目1</li><li>项目2</li><li>项目3</li></ul></body></html>
这就是 HTML 代码!我们可以看到很多由<>包围的特殊标记,这叫做 HTML 标签(Tag),浏览器通过识别这些 HTML 标签来渲染出各种界面和效果。
将上面的代码保存到index.html,拖到浏览器中运行(或者双击文件),可以看到如下的效果:
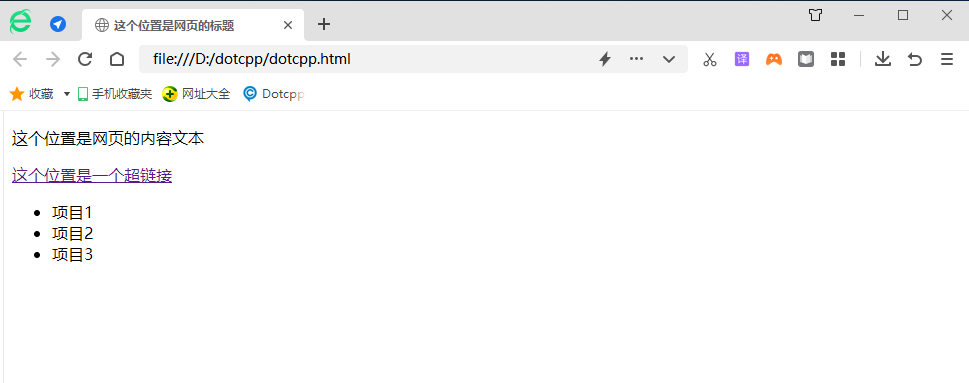
这是一个很简单很基础的网页,仅作为例子来演示,真实网页的 HTML 代码远比这复杂,你可以在网页上单击鼠标右键,然后在弹出菜单中选择“查看网页源代码”,就可以查看当前网页的 HTML 代码。
网页经由网址(URL)来识别与访问,当我们在网页浏览器输入网址后,经过一段复杂而又快速的程序, 网页文件会被传送到用户家的计算机,然后再通过 浏览器解释 网页的内容,再展示给用户。
1、网页:简单的从一个用户来说就是你看到的thing,淘宝网,C语言网之类的。
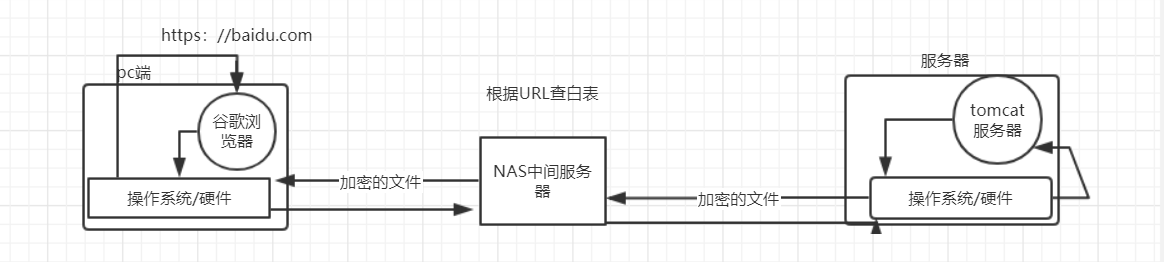
2、文件:我们都知道文件都是存在于计算机中的,下面的图片可以带大家看一下这些文件都在哪里,当然也仅仅只是一个范例。

● 在服务器端
这是一个Windows下的tomcat服务器,你所浏览的网页被保存在webapps文件夹内。
●在浏览器端
浏览器实际就是一个解析器,主要解析从服务器发来的HTTP文件,CSS文件与JS文件。
其实很简单,网页就是一些文件。
3、计算机: 计算机顾名思义在服务端就是服务器,服务器长什么样子?下面的图片就是服务器,大家可以看看。

4、网址(URL):

5、复杂而又快速的程序: 当网页文件发送过来后,会由这些程序来处理。
6、浏览器: 浏览器将接收到的三种文件经过浏览器中的内核解释,渲染成我们所见到的网页,然后展示给用户。
7、总结成一张图就是:
如果要了解网页的结构,就必须先了解一下W3C组织。
万维网联盟(World Wide Web Consortium,缩写W3C),又称W3C理事会。1994年10月在麻省理工学院计算机科学实验室成立。建立者是互联网的发明者蒂姆·伯纳斯-李。
由关于网页的几乎所有标准都是由这个联盟做的。根据其标准网页的标准是HTML为基本,CSS文件负责美化,JS负责交互与动作。
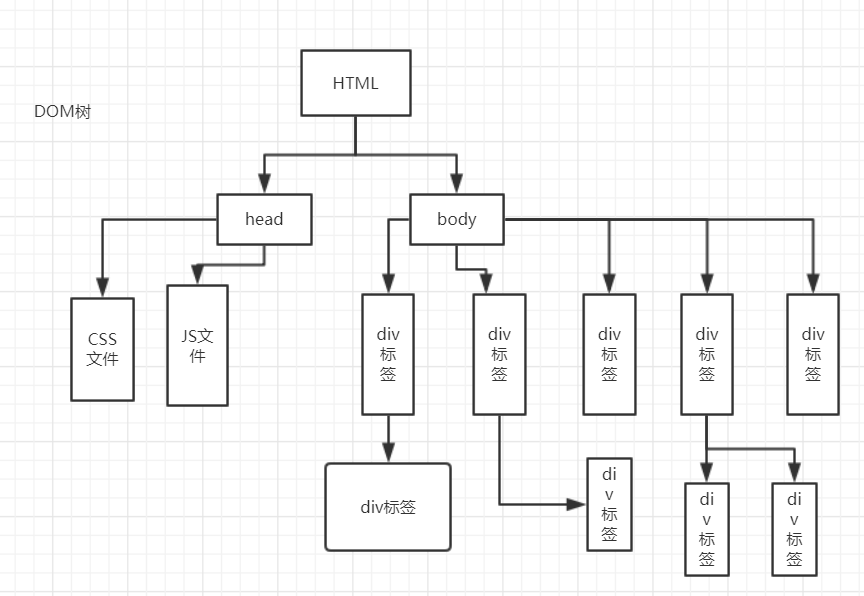
这就是一个简单的DOM树,我们的网络资源可以看成树上的每一个苹果,这样组织资源会大大的提高浏览器的解析速度。日常生活中我们的家族关系,就可以通过这样一张图清晰的展现出来。