近年来,大型语言模型的训练成本居高不下,成为制约AI发展的重要因素。如何降低训练成本,提高效率,成为业界关注的焦点。Downcodes小编为您带来一篇来自哈佛大学和斯坦福大学研究人员的最新论文解读,该论文提出了一种“精度感知”缩放法则,通过调整模型训练精度来有效降低训练成本,甚至在某些情况下还能提升模型性能。让我们一起深入了解这项令人振奋的研究成果。
在人工智能领域,规模越大似乎就意味着能力越强。为了追求更强大的语言模型,各大科技公司都在疯狂堆叠模型参数和训练数据,结果却发现成本也随之水涨船高。难道就没有一种既经济又高效的方法来训练语言模型吗?
来自哈佛大学和斯坦福大学的研究人员最近发表了一篇论文,他们发现,模型训练的精度(precision) 就像一把隐藏的钥匙,可以解锁语言模型训练的“成本密码”。
什么是模型精度?简单来说,它指的是模型参数和计算过程中使用的数字位数。传统的深度学习模型通常使用32位浮点数(FP32)进行训练,但近年来,随着硬件的发展,使用更低精度的数字类型,例如16位浮点数(FP16)或8位整数(INT8)进行训练已经成为可能。
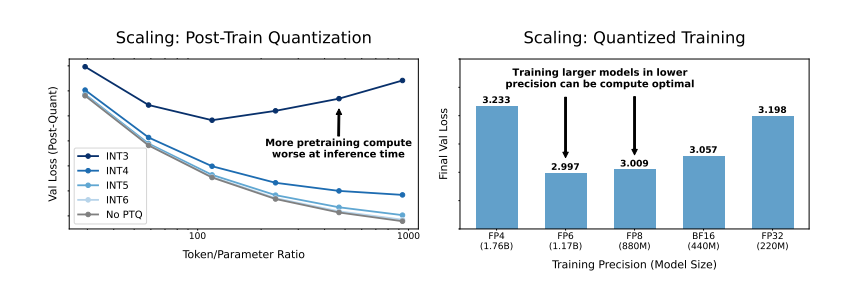
那么,降低模型精度会对模型性能产生什么影响呢? 这正是这篇论文想要探究的问题。研究人员通过大量的实验,分析了不同精度下模型训练和推理的成本和性能变化,并提出了一套全新的“精度感知”缩放法则。
他们发现,使用更低精度进行训练可以有效降低模型的“有效参数数量”,从而减少训练所需的计算量。这意味着,在相同的计算预算下,我们可以训练更大规模的模型,或者在相同规模下,使用更低的精度可以节省大量的计算资源。
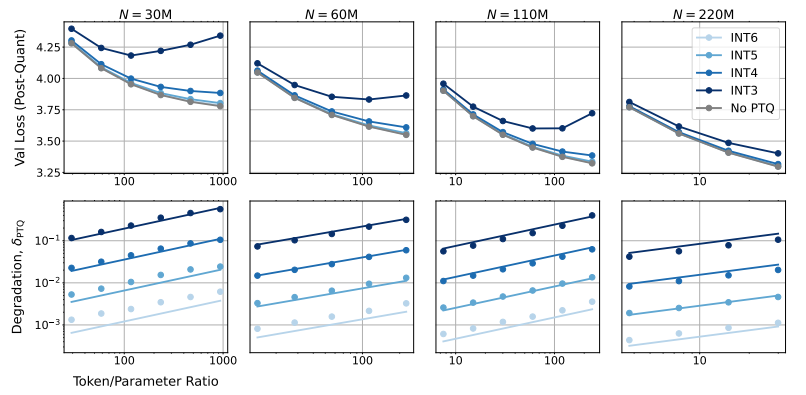
更令人惊讶的是,研究人员还发现,在某些情况下,使用更低的精度进行训练反而可以提高模型的性能! 例如,对于那些需要进行“量化后训练”(post-training quantization)的模型,如果在训练阶段就使用较低的精度,模型对量化后的精度降低会更加鲁棒,从而在推理阶段表现出更好的性能。
那么,我们应该选择哪种精度来训练模型呢? 研究人员通过分析他们的缩放法则,得出了一些有趣的结论:
传统的16位精度训练可能并非最优选择。 他们的研究表明,7-8位精度可能是更经济高效的选择。
一味追求超低精度(例如4位)训练也并非明智之举。 因为在极低的精度下,模型的有效参数数量会急剧下降,为了维持性能,我们需要大幅增加模型规模,这反而会导致更高的计算成本。
对于不同规模的模型,最佳训练精度可能会有所不同。 对于那些需要进行大量“过训练”(overtraining)的模型,例如 Llama-3和 Gemma-2系列,使用更高的精度进行训练反而可能更加经济高效。
这项研究为我们理解和优化语言模型训练提供了一个全新的视角。它告诉我们,精度的选择并非一成不变,而是需要根据具体的模型规模、训练数据量和应用场景进行权衡。
当然,这项研究也存在一些局限性。例如,他们使用的模型规模相对较小,实验结果可能无法直接推广到更大规模的模型。此外,他们只关注了模型的损失函数,并没有对模型在下游任务上的性能进行评估。
尽管如此,这项研究仍然具有重要的意义。它揭示了模型精度与模型性能和训练成本之间的复杂关系,并为我们未来设计和训练更强大、更经济的语言模型提供了宝贵的 insights。
论文:https://arxiv.org/pdf/2411.04330
总而言之,这项研究为降低大型语言模型训练成本提供了新的思路和方法,为未来AI发展提供了重要的参考价值。 Downcodes小编期待更多关于模型精度研究的进展,为构建更经济高效的AI模型贡献力量。