Meta AI 震撼发布了名为 SPIRIT LM 的基础多模态语言模型,这是一个能够自由混合文本和语音的里程碑式成果!它基于 70 亿参数的预训练文本语言模型,通过持续训练扩展到语音模态,实现了文本和语音的双模态理解与生成,甚至可以将两者混合,带来意想不到的应用效果。Downcodes小编将带您深入了解SPIRIT LM的强大功能及其背后的技术突破。
Meta AI近日重磅开源了名为SPIRIT LM的基础多模态语言模型,该模型能够自由混合文本和语音,为音频和文本的多模态任务打开了新的可能性。
SPIRIT LM基于一个70亿参数的预训练文本语言模型,通过在文本和语音单元上进行持续训练,扩展到语音模态。它可以像文本大模型一样理解和生成文本,同时还能理解和生成语音,甚至可以把文本和语音混合在一起,创造出各种神奇的效果! 比如,你可以用它来做语音识别,把语音转换成文字;也可以用它来做语音合成,把文字转换成语音;还可以用它来做语音分类,判断一段语音表达的是什么情绪。
更厉害的是,SPIRIT LM 还特别擅长“情感表达”! 它可以识别和生成各种不同的语音语调和风格,让 AI 的声音听起来更自然、更有感情。 你可以想象一下,用 SPIRIT LM 生成的语音,不再是那种冷冰冰的机器音,而是像真人说话一样,充满了喜怒哀乐!
为了让 AI 更好地“声情并茂”,Meta 的研究人员还专门开发了两个版本的 SPIRIT LM:
“基础版” (BASE):这个版本主要关注语音的音素信息,也就是语音的“基本构成”。
“表达版” (EXPRESSIVE):这个版本除了音素信息,还加入了音调和风格信息,可以让 AI 的声音更生动、更有表现力。
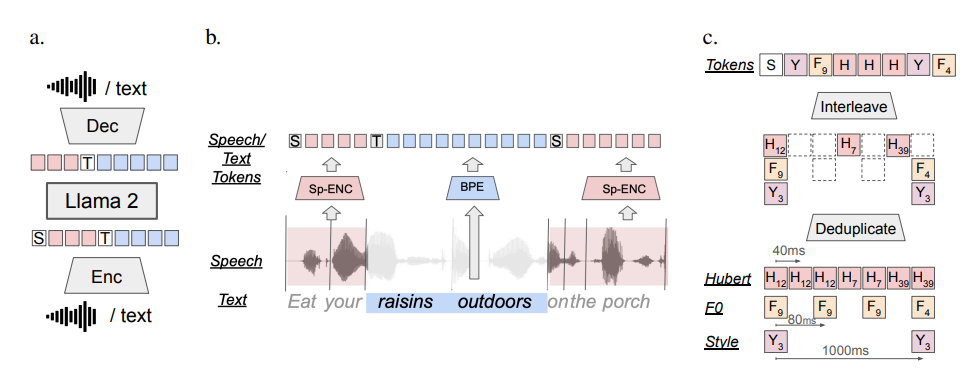
那么,SPIRIT LM 又是如何做到这一切的呢?
简单来说,SPIRIT LM 是基于 Meta 之前发布的超强文本大模型——LLAMA2训练出来的。 研究人员把大量的文本和语音数据“喂”给 LLAMA2,并采用了一种特殊的“交错训练”方法,让 LLAMA2能够同时学习文本和语音的规律。
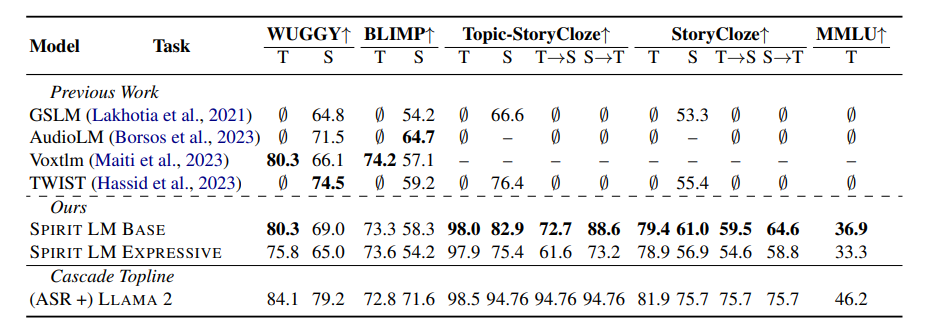
为了测试 SPIRIT LM 的“情感表达”能力,Meta 的研究人员还专门设计了一个新的测试基准——“语音-文本情感保留基准” (STSP)。 这个测试基准包含了各种表达不同情感的语音和文本提示,用来测试 AI 模型是否能够准确地识别和生成相应情感的语音和文本。 结果表明,SPIRIT LM 的“表达版”在情感保留方面表现出色,是目前第一个能够跨模态保留情感信息的 AI 模型!
当然,Meta 的研究人员也坦言,SPIRIT LM 还有很多需要改进的地方。 比如,SPIRIT LM 目前只支持英文,未来还需要扩展到其他语言;SPIRIT LM 的模型规模还不够大,未来还需要继续扩大模型规模,提升模型性能。
SPIRIT LM 是 Meta 在 AI 领域的一项重大突破,它为我们打开了通往“声情并茂”的 AI 世界的大门。 相信在不久的将来,我们会看到更多基于 SPIRIT LM 开发的有趣应用,让 AI 不止能说会道,还能像真人一样表达情感,与我们进行更自然、更亲切的交流!
项目地址:https://speechbot.github.io/spiritlm/
论文地址:https://arxiv.org/pdf/2402.05755
总而言之,SPIRIT LM 的开源为多模态AI领域带来了令人兴奋的进展,它的出现预示着未来AI在语音交互和情感表达方面将取得更大的突破,Downcodes小编将持续关注该领域的最新动态,敬请期待!