Meta的SAM模型在图像分割领域表现出色,但在视频物体追踪方面却面临挑战。尤其在复杂场景下,其“固定窗口”记忆机制导致误差传播,追踪效果不佳。为此,华盛顿大学研究人员开发了SAMURAI模型,对SAM2进行了改进,显着提升了视频物体追踪的准确性和稳定性。
Meta 推出的“分割一切”模型SAM 在图像分割领域可谓是所向披靡,但一碰到视频物体追踪,它就有点力不从心了,尤其是在人山人海、目标快速移动或玩“躲猫猫”的场景下, SAM 就会犯迷糊。这是因为SAM 模型的记忆机制就像个“固定窗口”,只顾着着记录最近的画面,而忽略了记忆内容的质量,导致在视频中出现误差传播,追踪效果大打折扣。
为了解决这个问题,华盛顿大学的研究人员“苦思冥想”,终于开发出了一款名为SAMURAI 的模型,对SAM2进行了“魔鬼改造”,专门用来搞定视频物体追踪。 SAMURAI 的名字取得很霸气,它也确实有两把刷子:它结合了时间运动线索和新提出的运动感知记忆选择机制,就像一位武艺高强的武士,能够精准预测物体的运动轨迹,并改进掩码选择,最终在无需重新训练或微调的情况下,实现稳健、准确的追踪。
SAMURAI 的秘诀在于两大创新:
第一招:运动建模系统。这个系统就像武士的“鹰眼”,能够更准确地预测复杂场景中的物体位置,从而优化掩码的选择,让SAMURAI 不会被相似的物体迷惑。
第二招:运动感知记忆选择机制。 SAMURAI 抛弃了SAM2简单的“固定窗口”记忆机制,转而采用混合评分系统,结合了原始掩码相似度、物体和运动分数,就像武士精心挑选武器一样,只保留最相关的历史信息,从而提高模型的整体追踪可靠性,避免误差传播。

SAMURAI 不仅武艺高强,还身手敏捷,能够实时运行。更重要的是,它在各种基准数据集上都展现了强大的零样本性能,这意味着它无需经过专门的训练,就能适应各种不同的场景,展现了极强的泛化能力。
在实战测试中,SAMURAI 在成功率和精度方面都比现有的追踪器取得了显着提高。例如,在LaSOText 数据集上,它获得了7.1% 的AUC 增益;在GOT-10k 数据集上,它获得了3.5% 的AO 增益。 更令人惊喜的是,它在LaSOT 数据集上什至取得了与完全监督方法相媲美的结果,这充分证明了它在复杂追踪场景中的强大实力以及在动态环境中实际应用的巨大潜力。
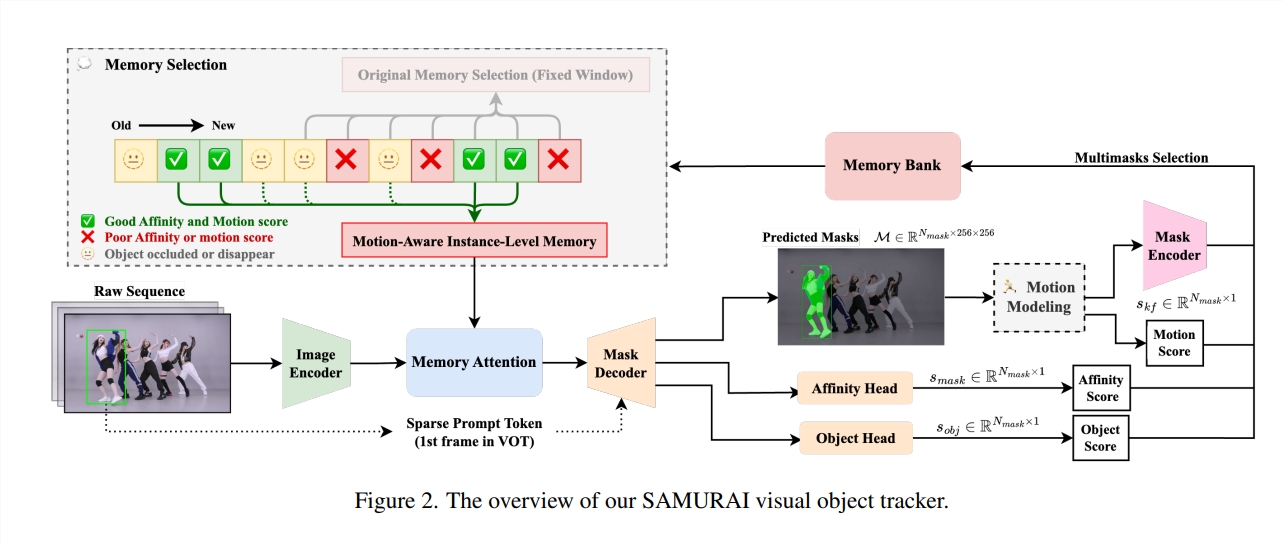
SAMURAI 的成功,得益于它对运动信息的巧妙利用。 研究人员将传统的卡尔曼滤波器与SAM2结合,通过预测物体的位置和尺寸,帮助模型从多个候选掩码中选择最可靠的掩码。 此外,他们还设计了一种基于三种评分(掩码相似度分数、物体出现分数和运动分数)的记忆选择机制,只有当这三种分数都达到阈值时,才会将该帧画面选入记忆库。这种选择性的记忆机制,有效地避免了无关信息的干扰,提高了追踪的准确性。
SAMURAI 的出现,为视频物体追踪领域带来了新的希望。它不仅在性能上超越了现有的追踪器,而且无需重新训练或微调,可以方便地应用于各种场景。相信在未来,SAMURAI 将会在自动驾驶、机器人、视频监控等领域发挥重要作用,为我们带来更加智能的生活体验。
项目地址:https://yangchris11.github.io/samurai/
论文地址:https://arxiv.org/pdf/2411.11922
Downcodes小编总结:SAMURAI模型的出现,为视频目标追踪技术带来了显着的进步,其创新性的记忆机制和运动建模系统有效解决了传统方法的不足,未来应用前景广阔。