Downcodes小编报道:近年来,音频驱动的图像动画技术发展迅速,但现有模型在效率和时长方面仍存在瓶颈。为解决这一问题,研究人员开发出一种名为JoyVASA的新技术,它通过巧妙的双阶段设计,显着提升了音频驱动图像动画的质量和效率。 JoyVASA不仅能够生成更长的动画视频,还支持动物面部动画,并展现出良好的多语言兼容性,为动画制作领域带来了新的可能性。
近日,研究人员提出了一种名为JoyVASA 的新技术,旨在提升音频驱动的图像动画效果。随着深度学习和扩散模型的不断发展,音频驱动的人像动画在视频质量和嘴形同步精度方面取得了显着进展。然而,现有模型的复杂性增加了训练和推理的效率问题,同时也限制了视频的时长和帧间连续性。
JoyVASA 采用了两阶段的设计,第一阶段引入了一种解耦的面部表征框架,将动态面部表情与静态的三维面部表征分开。
这种分离使得系统能够将任何静态的三维面部模型与动态动作序列相结合,从而生成更长的动画视频。在第二阶段,研究团队训练了一种扩散变换器,能够直接从音频线索中生成动作序列,这一过程与角色身份无关。最后,基于第一阶段训练的生成器将三维面部表征和生成的动作序列作为输入,渲染出高质量的动画效果。
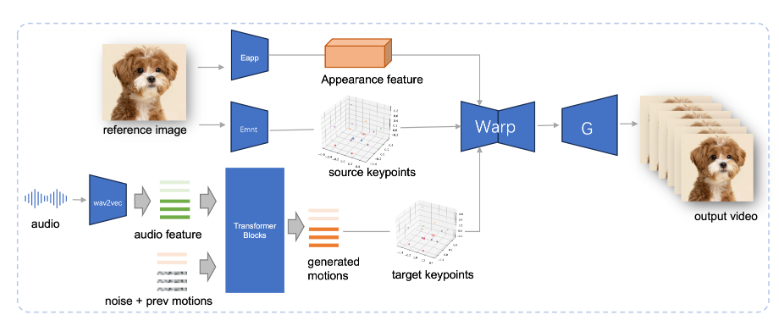
值得注意的是,JoyVASA 不仅限于人像动画,还能够无缝地动画化动物面部。这一模型在一个混合数据集上进行训练,结合了私有的中文数据和公共的英文数据,展现出良好的多语言支持能力。实验结果证明了这一方法的有效性,未来的研究将重点提升实时性能和细化表情控制,进一步扩展这一框架在图像动画中的应用。
JoyVASA 的出现标志着音频驱动动画技术的一次重要突破,推动了在动画领域的新可能性。
项目入口:https://jdh-algo.github.io/JoyVASA/
JoyVASA技术的创新之处在于其高效的双阶段设计和强大的多语言支持能力,为动画制作提供了更便捷、更高效的解决方案。未来,随着技术的进一步完善,JoyVASA有望在更多领域得到广泛应用,为我们带来更逼真、更精彩的动画作品。期待更多技术突破,引领动画行业发展新篇章!