Downcodes小编获悉,Meta近日发布了全新的多语言多轮对话指令遵循能力评估基准测试Multi-IF,该基准涵盖八种语言,包含4501个三轮对话任务,旨在更全面地评估大语言模型(LLM)在实际应用中的表现。与现有评估标准主要集中于单轮对话和单语言任务不同,Multi-IF着重考察模型在复杂多轮和多语言场景下的能力,为LLM的改进提供了更清晰的方向。
Meta 最近发布了一项全新的基准测试,名为 Multi-IF,旨在评估大语言模型(LLM)在多轮对话和多语言环境下的指令遵循能力。这一基准覆盖了八种语言,包含4501个三轮对话任务,重点探讨了当前模型在复杂多轮和多语言场景中的表现。
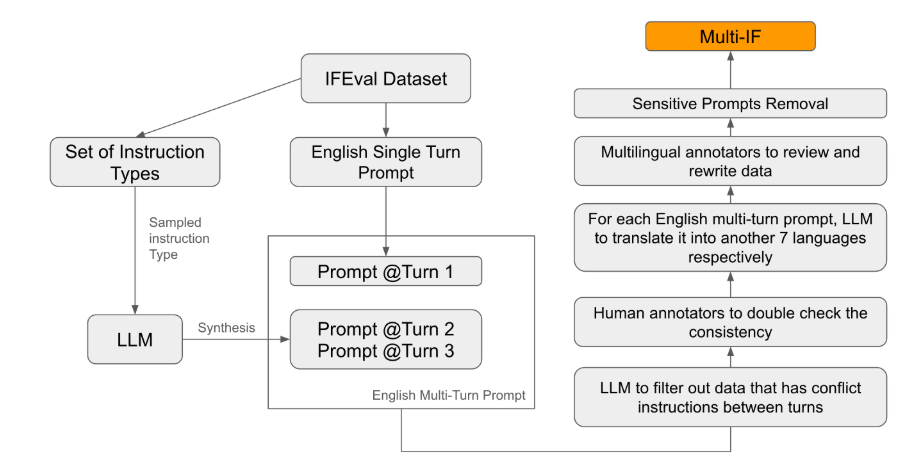
在现有的评估标准中,大多数集中于单轮对话和单语言任务,难以全面反映模型在实际应用中的表现。而 Multi-IF 的推出正是为了填补这一空白。研究团队通过将单轮指令扩展为多轮指令,生成了复杂的对话场景,并确保每一轮指令在逻辑上连贯、递进。此外,数据集还通过自动翻译和人工校对等步骤实现了多语言支持。
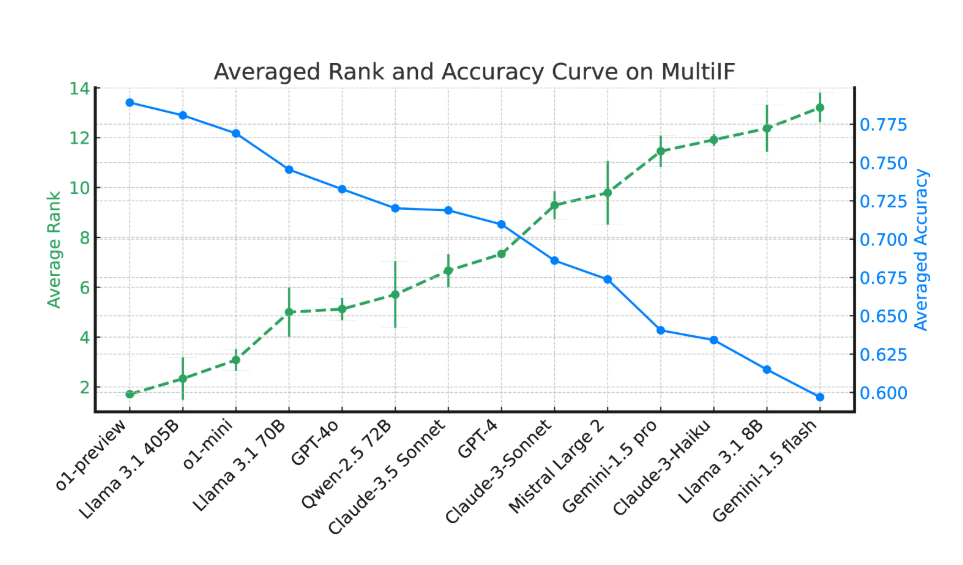
实验结果显示,大多数 LLM 在多轮对话中的表现显著下降。以 o1-preview 模型为例,其在第一轮的平均准确率为87.7%,但到了第三轮下降至70.7%。特别是在非拉丁文字的语言中,如印地语、俄语和中文,模型的表现普遍低于英语,显示出在多语言任务上的局限性。
在对14种前沿语言模型的评估中,o1-preview 和 Llama3.1405B 表现最佳,三轮指令的平均准确率分别为78.9% 和78.1%。然而,在多轮对话中,所有模型的指令遵循能力普遍下降,反映出模型在复杂任务中的挑战。研究团队还引入了 “指令遗忘率”(IFR)来量化模型在多轮对话中的指令遗忘现象,结果显示高性能模型在这方面的表现相对较好。
Multi-IF 的发布为研究人员提供了一个具有挑战性的基准,推动了 LLM 在全球化和多语言应用中的发展。这一基准的推出,不仅揭示了当前模型在多轮、多语言任务中的不足,也为未来改进提供了明确方向。
论文:https://arxiv.org/html/2410.15553v2
Multi-IF基准测试的发布,为大语言模型在多轮对话和多语言处理方面的研究提供了重要的参考依据,也为未来模型的改进方向指明了道路。期待未来会有更多更强大的LLM涌现,更好地应对复杂的多轮多语言任务挑战。