苹果AI研究团队发布了新一代多模态大语言模型家族MM1.5,它能够融合文本、图像等多种数据类型,在视觉问答、图像生成和多模态数据解读等任务上展现出强大的能力。 MM1.5克服了以往多模态模型在处理文本丰富图像和细粒度视觉任务上的困难,通过创新的数据中心化方法,利用高分辨率OCR数据和合成的图像描述,显着提升了模型的理解能力。 Downcodes小编将带您深入了解MM1.5的创新之处以及其在多个基准测试中的出色表现。
最近,苹果AI 研究团队推出了他们的新一代多模态大语言模型(MLLMs)家族——MM1.5。这一系列模型能够结合文本、图像等多种数据类型,向我们展示了AI 在理解复杂任务方面的新能力。像视觉问答、图像生成和多模态数据解读这样的任务,都能在这些模型的帮助下得到更好的解决。
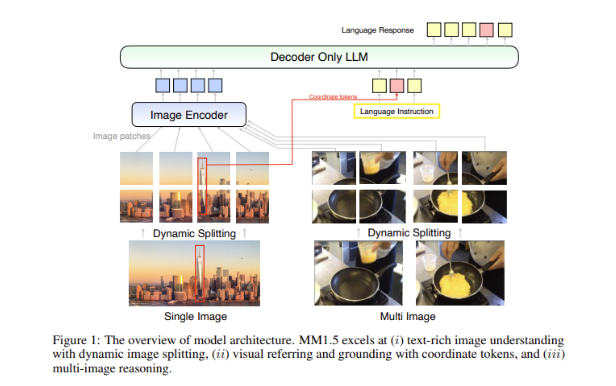
多模态模型的一个大挑战,就是如何在不同数据类型之间实现有效的交互。过去的模型常常在处理文本丰富的图像或者细粒度视觉任务时遇到困难。因此,苹果的研究团队在MM1.5模型中引入了创新的数据中心化方法,利用高分辨率的OCR 数据和合成的图像描述,来强化模型的理解能力。
这一方法不仅使MM1.5在视觉理解和定位任务上超越了以前的模型,同时也推出了两款专门版的模型:MM1.5-Video 和MM1.5-UI,分别用于视频理解和移动界面分析。
MM1.5模型的训练分为三个主要阶段。
第一阶段是大规模预训练,使用了20亿对图像和文本数据,600百万个交错的图像文本文档,以及2万亿个仅含文本的token。
第二阶段是通过45百万个高质量OCR 数据和700万条合成描述的持续预训练,进一步提升文本丰富图像任务的性能。
最后,在监督微调阶段,模型使用经过精心挑选的单图、多图和仅文本的数据进行优化,使其更擅长于细致的视觉引用和多图推理。
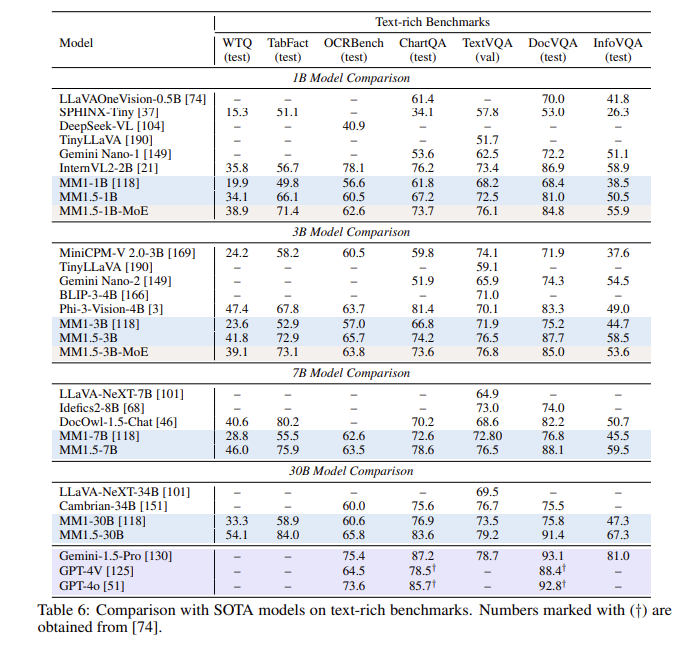
经过一系列评估,MM1.5模型在多个基准测试中表现出色,尤其在处理文本丰富的图像理解时,比之前的模型有了1.4分的提升。此外,即使是专门针对视频理解的MM1.5-Video,凭借强大的多模态能力,也在相关任务中达到了领先水平。
MM1.5模型家族不仅为多模态大语言模型设定了新的基准,还展示了其在各类应用中的潜力,从一般的图像文本理解到视频和用户界面分析,均有着出色的表现。
划重点:
** 模型变种**:包括参数从10亿到300亿的密集模型和MoE 模型,确保可扩展性与灵活部署。
? ** 训练数据**:利用20亿对图像文本对,600百万个交错图像文本文档,以及2万亿个仅文本的token。
** 性能提升**:在专注于文本丰富图像理解的基准测试中,相较于先前模型取得了1.4分的提升。
总而言之,苹果的MM1.5模型家族在多模态大语言模型领域取得了显着进展,其创新方法和出色性能为未来AI发展提供了新的方向。 期待MM1.5在更多应用场景中展现其潜力。