卡内基梅隆大学的研究团队最近发布了一项突破性技术——DressRecon,这项技术能够通过单目视频重建时间一致且细节丰富的人体3D模型。不同于以往需要紧身衣物或多视角数据的人体重建方法,DressRecon能够处理穿着宽松衣物甚至手持物体的场景,极大地扩展了应用范围,为虚拟形象创建、动画制作等领域带来革新。Downcodes小编带你深入了解这项令人瞩目的技术。
近日,卡内基梅隆大学的研究团队发布了一项名为 “DressRecon” 的新技术,旨在通过单目视频重建时间一致的人体模型。DressRecon的厉害之处在于,不仅输入视频就能实现构建出3D模型,并它还能还原复杂的服装和手持物品等细微细节。
这项技术特别适用于穿着宽松衣物或者与手持物体互动的场景,突破了以往技术的局限。以往的人体重建通常要求穿着紧身衣物,或需要多视角校准捕捉数据,甚至个性化扫描,难以大规模收集。
而 “DressRecon” 的创新在于它结合了通用的人体形态先验知识和特定视频的形体变形,能够在一段视频中进行优化。
这项技术的核心是学习一个神经隐式模型,该模型能够将身体和衣物的变形分开处理,分别建立运动模型层。
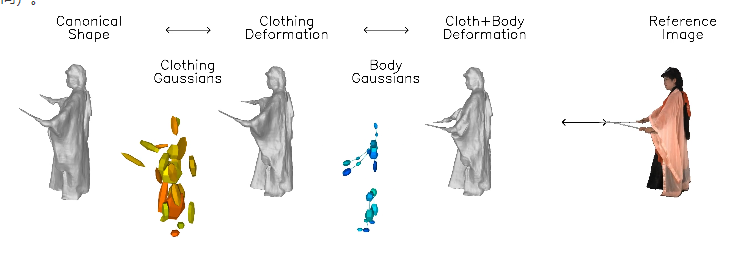
为了捕捉衣物的细微几何特征,研究团队利用了图像基础的先验知识,包括人体姿态、表面法线和光流等。这些信息在优化过程中提供了额外的支持,使得重建的效果更加真实。

DressRecon 能够从单一的视频输入中提取出高保真的三维模型,甚至能通过进一步优化为明确的三维高斯体,以提高渲染质量,支持交互式可视化。
研究者展示了在一些极具挑战性的衣物变形和物体交互的数据集上,DressRecon 所能实现的高保真三维重建效果。
此外,重建的虚拟人形象能够从任意角度进行渲染,展示出极具视觉冲击力的效果。团队还对比了 DressRecon 与多个基线技术在形状重建上的表现,结果表明,DressRecon 在处理复杂变形结构时,展现出了更高的保真度。
项目入口:https://jefftan969.github.io/dressrecon/
划重点:
? 研究团队推出 DressRecon 技术,通过单目视频实现高质量的人体重建,尤其适用于宽松衣物和手持物体的场景。
? 利用神经隐式模型,该技术将身体与衣物变形分开处理,借助图像基础的先验知识来捕捉细微几何特征。
? 重建结果不仅能生成高保真的三维模型,还支持从任意角度渲染,提升了可视化体验。
DressRecon技术的出现,无疑将推动三维人体建模技术向前发展一大步。其高效、便捷的特性,以及对复杂场景的出色处理能力,为未来虚拟现实、动画制作、游戏开发等领域带来了无限可能。期待这项技术在更多应用场景中发挥其巨大潜力!