Downcodes小编为您带来重磅消息!人工智能领域再添新成员——Zyphra公司正式发布了其小型语言模型Zamba2-7B!这款70亿参数的模型,在性能上实现了突破,尤其是在效率和适应性方面,展现出令人瞩目的优势。它不仅适用于高性能计算环境,更重要的是,Zamba2-7B 也能运行在消费级GPU上,让更多用户能够轻松体验先进AI技术的魅力。本文将深入探讨Zamba2-7B的创新之处,以及它对自然语言处理领域带来的影响。
最近,Zyphra 正式推出了 Zamba2-7B,这是一款具有前所未有性能的小型语言模型,参数数量达到7B。
这款模型号称在质量和速度上超越了目前的竞争对手,包括 Mistral-7B、谷歌的 Gemma-7B 以及 Meta 的 Llama3-8B。
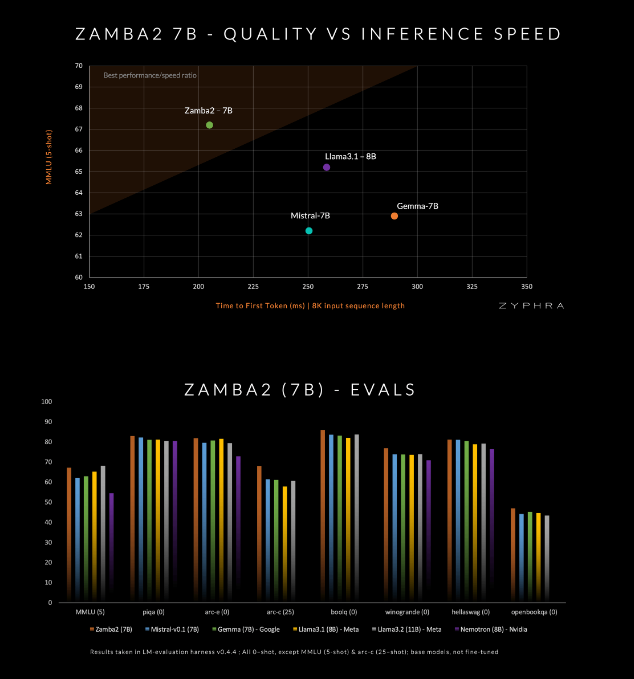
Zamba2-7B 的设计目标是满足那些需要强大语言处理能力但又受限于硬件条件的环境,比如在设备上处理或使用消费级 GPU。通过提高效率而不牺牲质量,Zyphra 希望能让更广泛的用户,无论是企业还是个人开发者,都能享受到先进 AI 的便利。
Zamba2-7B 在架构上做了很多创新,提升了模型的效率和表达能力。与前一代模型 Zamba1不同,Zamba2-7B 采用了两个共享注意力块,这种设计能更好地处理信息流和序列之间的依赖关系。
Mamba2块构成了整个架构的核心,这使得模型的参数利用率相比传统的变换器模型更高。此外,Zyphra 还在共享的 MLP 块上使用了低秩适应(LoRA)投影,这进一步提高了每一层的适应性,同时保持了模型的紧凑性。得益于这些创新,Zamba2-7B 的首次响应时间减少了25%,每秒处理的 token 数量提升了20%。
Zamba2-7B 的高效和适应性得到了严格测试的验证。该模型在一个包含三万亿 token 的海量数据集上进行预训练,这些数据集都是高质量和经过严格筛选的开放数据。
此外,Zyphra 还引入了一种 “退火” 预训练阶段,快速降低学习率,以便更有效地处理高质量 token。这种策略让 Zamba2-7B 在基准测试中表现出色,在推理速度和质量上都超越了竞争对手,适合处理自然语言理解和生成等任务,而不需要传统高质量模型所需的巨量计算资源。
amba2-7B 代表了小型语言模型的一个重大进步,它在保持高质量和高性能的同时,还特别注重了可访问性。Zyphra 通过创新的架构设计和高效的训练技术,成功打造出一款不仅便于使用,同时又能满足各种自然语言处理需求的模型。Zamba2-7B 的开源发布,邀请研究人员、开发者和企业探索其潜力,有望在更广泛的社区中推进高级自然语言处理的发展。
项目入口:https://www.zyphra.com/post/zamba2-7b
https://github.com/Zyphra/transformers_zamba2
Zamba2-7B的开源发布,为自然语言处理领域带来了新的活力,也为开发者们提供了更多可能性。期待Zamba2-7B在未来能有更广泛的应用,推动人工智能技术持续进步!