Downcodes小编带您了解阿里巴巴AI团队的最新突破!他们推出的mPLUG-DocOwl1.5模型在无需OCR技术的情况下,实现了卓越的文档理解能力。该模型打破了传统文档理解的瓶颈,直接从图像中学习理解文档内容,其高效性和准确性令人惊叹。它不仅能够处理普通文档,还支持表格、图表、网页和自然图像等多种文档类型,展现出强大的适应性和处理能力。让我们一起来深入了解这款尖端AI模型的优势和未来发展方向。
最近,阿里巴巴的 AI 研究团队在文档理解领域取得了令人瞩目的进展,他们推出了 mPLUG-DocOwl1.5,这是一款在无OCR(光学字符识别)文档理解任务上表现卓越的尖端模型。
过去,处理文档理解任务时,我们通常依赖 OCR 技术来从图像中提取文本,但这往往会受到复杂布局和视觉噪声的困扰。而 mPLUG-DocOwl1.5则通过一种全新的统一结构学习框架,直接从图像中学习理解文档,巧妙地避开了这一瓶颈。
该模型通过分析文档在不同领域的布局和组织能力,涵盖了普通文档、表格、图表、网页和自然图像等五个领域。它不仅能准确识别文字,还能在理解文档结构时,运用空格和换行符等元素。

对于表格,模型能生成结构化的 Markdown 格式,而在解析图表时,它通过理解图例、坐标轴和数值之间的关系,将其转化为数据表。此外,mPLUG-DocOwl1.5还具备从自然图像中提取文本的能力。
在文本本地化方面,mPLUG-DocOwl1.5能够识别和定位单词、短语、行和块,确保文本与图像区域之间的精确对齐。而其背后的 H-Reducer 架构则通过卷积操作横向合并视觉特征,保持空间布局的同时减少序列长度,从而提升了处理效率。
为了训练这个模型,研究团队使用了两个精心挑选的数据集。DocStruct4M 是一个大规模的数据集,专注于统一结构学习,DocReason25K 则通过分步问答测试模型的推理能力。
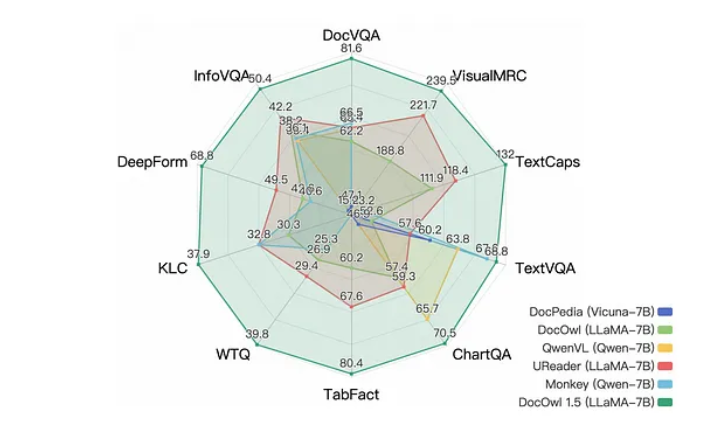
结果显示,mPLUG-DocOwl1.5在十个基准测试中创下了新纪录,相比同类模型在一半任务上获得了超过10分的提升。此外,它还展现出优秀的语言推理能力,能够为其答案生成详细的分步解释。
尽管 mPLUG-DocOwl1.5在多个方面都取得了显著进展,但研究者们也意识到,模型仍有改进空间,尤其是在处理不一致或错误的陈述方面。未来,团队希望能够进一步扩展统一结构学习框架,涵盖更多的文档类型和任务,推动文档 AI 的进一步发展。
论文:https://arxiv.org/abs/2403.12895
代码:https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5
划重点:
mPLUG-DocOwl1.5是一在无需 OCR 文档理解任务上表现卓越的 AI 模型。
该模型能分析文档布局,涵盖多种文档类型,能够从图像中直接学习理解。
mPLUG-DocOwl1.5在十个基准测试中创下新纪录,展示出优越的语言推理能力。
mPLUG-DocOwl1.5的出现,标志着文档理解技术迈向了一个新的里程碑。其高效、准确以及强大的适应性,为未来文档处理和信息提取提供了无限可能。Downcodes小编相信,随着技术的不断进步,mPLUG-DocOwl1.5将会在更多领域发挥重要作用,为我们带来更加智能化的信息处理体验。