Downcodes小编获悉,耶鲁大学一项突破性研究揭示了AI模型训练的奥秘:数据复杂度并非越高越好,而是存在一个最佳的“混沌边缘”状态。研究团队巧妙地利用元胞自动机模型进行实验,探索了不同复杂度数据对AI模型学习效果的影响,并得出令人瞩目的结论。
耶鲁大学研究团队近日发布了一项开创性研究成果,揭示了AI模型训练的关键发现:AI学习效果最好的数据并非越简单或越复杂越好,而是存在一个最佳的复杂度水平——被称为混沌边缘的状态。
研究团队通过使用基本元胞自动机(ECAs)进行实验,这是一种简单的系统,其中每个单元的未来状态仅取决于自身和相邻两个单元的状态。尽管规则简单,但这种系统可以产生从简单到高度复杂的多样化模式。研究人员随后评估了这些语言模型在推理任务和国际象棋走子预测等方面的表现。
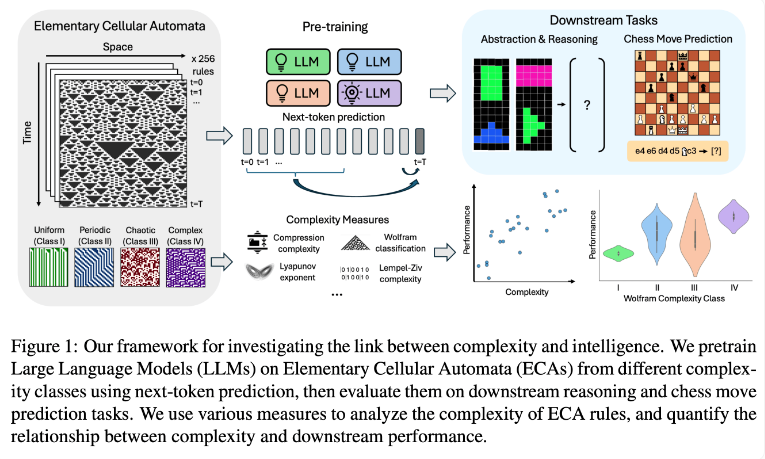
研究结果表明,在更复杂ECA规则上训练的AI模型在后续任务中表现更为出色。特别是在Wolfram分类中的Class IV类ECAs上训练的模型,展现出最佳性能。这类规则产生的模式既不完全有序也不完全混沌,而是呈现出一种结构化的复杂性。
研究人员发现,当模型接触过于简单的模式时,往往只能学到简单的解决方案。相比之下,在更复杂模式上训练的模型即使在有简单解决方案的情况下,也能发展出更复杂的处理能力。研究团队推测,这种学习表征的复杂性是模型能够将知识迁移到其他任务的关键因素。
这一发现可能解释了为什么GPT-3和GPT-4等大型语言模型如此高效。研究人员认为,这些模型在训练过程中使用的海量且多样化的数据,可能创造了类似于他们研究中复杂ECA模式的效果。
这项研究为AI模型的训练提供了新的思路,也为理解大型语言模型的强大能力提供了新的视角。未来,或许我们可以通过更精细地控制训练数据的复杂度,来进一步提升AI模型的性能和泛化能力。Downcodes小编相信,这项研究成果将对人工智能领域产生深远的影响。