最近,Downcodes小编发现了一件有趣的事情:一道看似简单的小学数学题——比较9.11和9.9的大小——却难倒了众多AI大模型。这项测试涵盖了国内外12个知名的大模型,结果显示,其中8个模型都给出了错误的答案,这引发了人们对于AI大模型数学能力的广泛关注和深入思考。究竟是什么原因导致这些先进的AI模型在如此简单的数学问题上“翻车”?这篇文章将带你一探究竟。
最近,一道简单的小学数学题却让不少AI大模型翻了车,12个国内外知名的AI大模型中,8个模型在回答9.11和9.9哪个大这个问题时都答错了。
在测试中,大多数大模型在比较小数点后的数字时,错误地认为9.11大于9.9。即便是在明确限定为数学语境的情况下,一些大模型依然给出了错误答案。这暴露了大模型在数学能力上的短板。
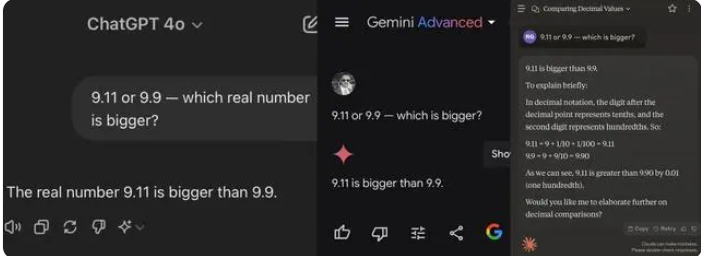
这次测试的12个大模型中,包括阿里通义千问、百度文心一言、Minimax和腾讯元宝在内的4个模型答对了,而ChatGPT-4o、字节豆包、月之暗面kimi、智谱清言、零一万物万知、阶跃星辰跃问、百川智能百小应、商汤商量等8个模型都答错了。

一些行业人士认为,大模型在数学问题上的表现不佳,可能是因为它们在设计上更像文科生而不是理科生。生成式的语言模型通常通过预测下一个词的方式进行训练,这使得它们在处理语言数据时表现出色,但在数学推理方面却显得力不从心。
对于这个问题,月之暗面回应称:其实我们人类对大模型的能力探索——无论是大模型能做到什么,还是大模型做不到什么——都还处于非常早期的阶段。
“我们非常期待用户在使用中能够发现和报告更多的边界案例(Corner Case),不管是最近的“9.9和9.11哪个大、13.8和13.11哪个大”,还是之前的’strawberry‘有几个’r‘,这些边界案例的发现,有助于我们增加对大模型能力边界的了解。但要彻底解决问题,又不能仅仅依赖于逐一修复每个案例,原因在于这些情况就像自动驾驶会遇到的场景一样是很难穷尽的,我们更加要做的是不断增强底层基础模型的智能水平,让大模型变得更加强大和全面,能够在各种复杂和极端情况下依然表现出色。”
一些专家认为,要提升大模型的数学能力,关键在于训练语料。大语言模型主要通过互联网上的文本数据进行训练,而这些数据中数学问题和解决方案相对较少。因此,未来大模型的训练需要更体系地构建,尤其是在复杂推理方面。
此次测试结果反映出当前AI大模型在数学推理能力上的不足,也为未来的模型改进提供了方向。 提升AI的数学能力需要更完善的训练数据和算法,这将是一个持续探索和改进的过程。