Downcodes小编带你揭秘视觉语言模型(VLMs)的真相!你是否以为VLMs能像人类一样“看懂”图像?事实并非如此简单。本文将深入探讨VLMs在图像理解方面的局限性,并通过一系列实验结果,展现它们与人类视觉能力的巨大差距。准备好颠覆你对VLMs的认知了吗?
视觉语言模型(VLMs)大家应该都听说过,这些AI界的小能手不仅能读懂文字,还能“看”懂图片。但事实并非如此,今天,我们来扒一扒它们的“底裤”,看看它们是不是真的像我们人类一样能“看”懂图像。
首先,得给大家科普一下,VLMs是啥玩意儿。简单来说,它们就是一些大型的语言模型,比如GPT-4o和Gemini-1.5Pro,它们在图像和文本处理上表现得风生水起,甚至在很多视觉理解测试上都拿到了高分。但别被这些高分唬住,我们今天要看看它们是不是真的那么牛。
研究人员们设计了一套叫做BlindTest的测试,里面有7个任务,对人类来说简直简单到不行。比如,判断两个圆是否重叠,两条线是否相交,或者数数奥运标志里有几个圆圈。这些任务听起来是不是觉得幼儿园小朋友都能轻松搞定?但告诉你,这些VLMs的表现可没那么神。
结果让人大跌眼镜,这些所谓的先进模型在BlindTest上的平均准确率只有56.20%,最好的Sonnet-3.5也就73.77%的准确率。这就好比一个号称能考清华北大的学霸,结果连小学数学题都做不对。

为啥会这样呢?研究人员分析,可能是因为VLMs在处理图像时,就像是个近视眼,看不清楚细节。它们虽然能大致看出图像的总体趋势,但一旦涉及到精确的空间信息,比如两个图形是否相交,或者重叠,它们就懵了。
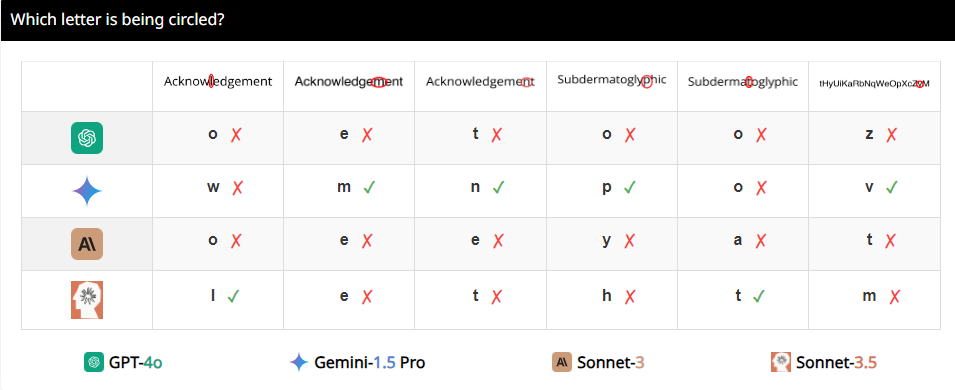
举个例子,研究人员让VLMs判断两个圆是否重叠,结果发现,即使两个圆大得跟西瓜似的,这些模型还是不能100%准确地回答出来。还有,当让它们数数奥运标志里的圆圈数,它们的表现也是一言难尽。
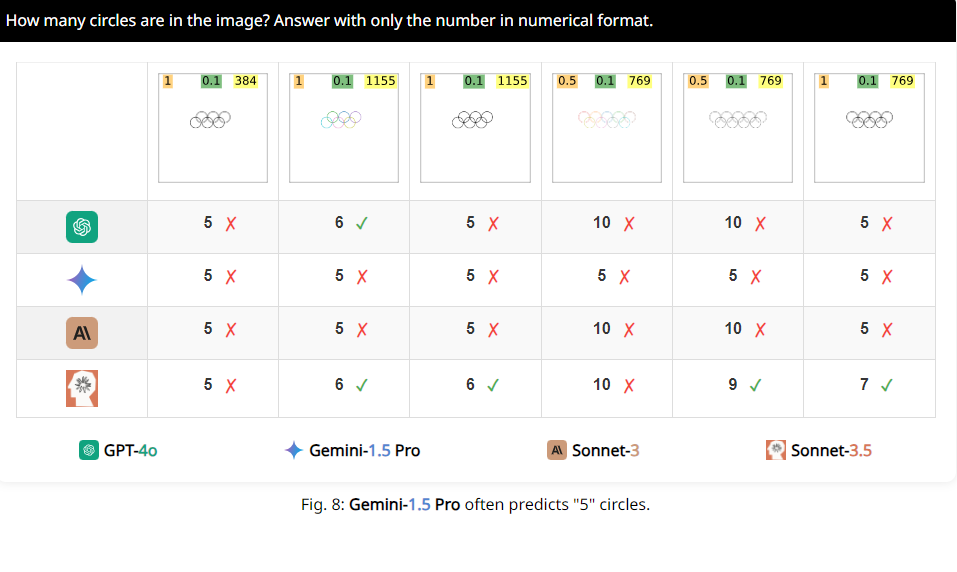
更有意思的是,研究人员还发现,这些VLMs在数数时,似乎对数字5有一种特别的偏好。比如,当奥运标志里的圆圈数超过5个时,它们就倾向于回答“5”,这可能是因为奥运标志里有5个圆圈,它们对这个数字特别熟悉。
好了,说了这么多,小伙伴们是不是对这些看似高大上的VLMs有了新的认识?其实,它们在视觉理解上还有很多局限,远没有达到我们人类的水平。所以,下次再听到有人说AI能完全替代人类,你就可以呵呵一笑了。
论文地址:https://arxiv.org/pdf/2407.06581
项目页:https://vlmsareblind.github.io/
总而言之,尽管VLMs在图像识别领域取得了显著进展,但其在精确空间推理方面的能力仍存在较大不足。这项研究提醒我们,对AI技术的评估不能仅仅依赖于高分成绩,更需要深入了解其局限性,避免盲目乐观。期待未来VLMs能够在视觉理解方面取得突破性进展!