Downcodes小编带你了解Google DeepMind一项突破性研究:百万专家混合模型(Mixture of Experts,MoE)。这项研究在Transformer架构上取得了革命性进展,其核心在于一种参数高效的专家检索机制,利用乘积密钥技术平衡计算成本与参数数量,从而在保持效率的同时大幅提升模型潜力。这项研究不仅探索了极端MoE设置,更首次证明了学习索引结构可以有效地路由到超过百万个专家,为AI领域带来新的可能性。
Google DeepMind提出的百万专家Mixture模型,一个在Transformer架构上迈出了革命性步伐的研究。
想象一下,一个能够从一百万个微型专家中进行稀疏检索的模型,这听起来是不是有点像科幻小说里的情节?但这正是DeepMind的最新研究成果。这项研究的核心是一种参数高效的专家检索机制,它利用乘积密钥技术,将计算成本与参数计数分离,从而在保持计算效率的同时,释放了Transformer架构的更大潜力。
这项工作的亮点在于,它不仅探索了极端MoE设置,还首次证明了学习索引结构可以有效地路由到超过一百万个专家。这就好比在茫茫人海中,迅速找到那几个能够解决问题的专家,而且这一切还都是在计算成本可控的前提下完成的。
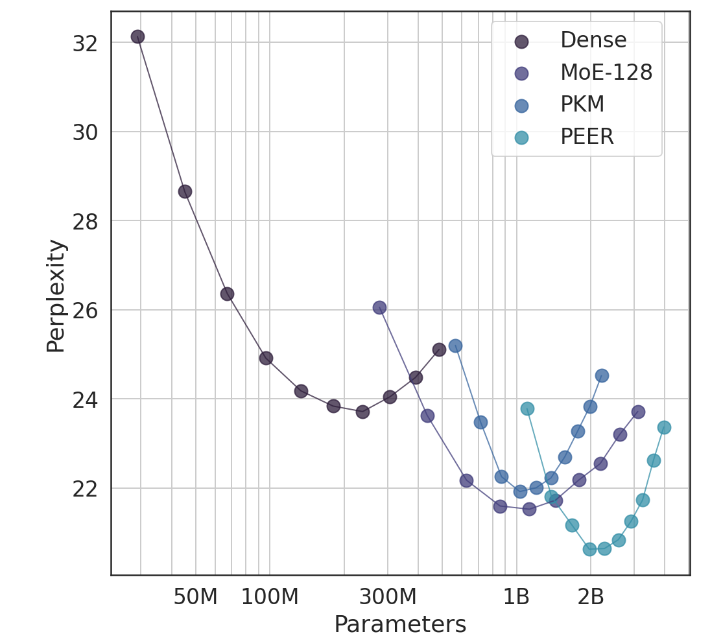
在实验中,PEER架构展现出了卓越的计算性能,与密集的FFW、粗粒度MoE和产品密钥存储器(PKM)层相比,其效率更高。这不仅仅是理论上的胜利,更是在实际应用中的一次巨大飞跃。通过实证结果,我们可以看到PEER在语言建模任务中的优越表现,它不仅困惑度更低,而且在消融实验中,通过调整专家数量和活跃专家的数量,PEER模型的性能得到了显著提升。
这项研究的作者,Xu He(Owen),是Google DeepMind的研究科学家,他的这次单枪匹马的探索,无疑为AI领域带来了新的启示。正如他所展示的,通过个性化和智能化的方法,我们能够显著提升转化率,留住用户,这在AIGC领域尤为重要。
论文地址:https://arxiv.org/abs/2407.04153
总而言之,Google DeepMind的百万专家混合模型研究为大型语言模型的构建提供了新的思路,其高效的专家检索机制和优异的实验结果都预示着未来AI模型发展的巨大潜力。 Downcodes小编期待更多类似的突破性研究成果出现!