Downcodes小编为您带来重磅消息!Cerebras Systems 推出了全球速度最快的 AI 推理服务——Cerebras Inference,该服务以其惊人的速度和极具竞争力的价格,彻底改变了 AI 推理领域的游戏规则。它在处理各种 AI 模型,特别是大型语言模型(LLMs)方面表现出色,速度是传统 GPU 系统的 20 倍,价格却低至十分之一甚至百分之一。这将如何影响 AI 应用的未来发展呢?让我们一起深入了解。
性能 AI 计算领域的先驱 Cerebras Systems 推出了一种开创性的解决方案,该解决方案将彻底改变 AI 推理。2024年8月27日,该公司宣布推出 Cerebras Inference,这是世界上最快的 AI 推理服务。Cerebras Inference 的性能指标使基于 GPU 的传统系统相形见绌,以极低的成本提供20倍的速度,为 AI 计算树立了新的标杆。
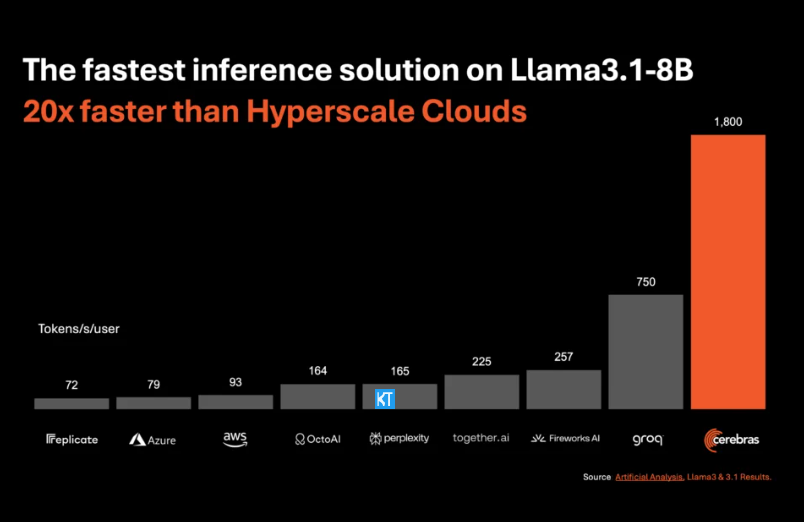
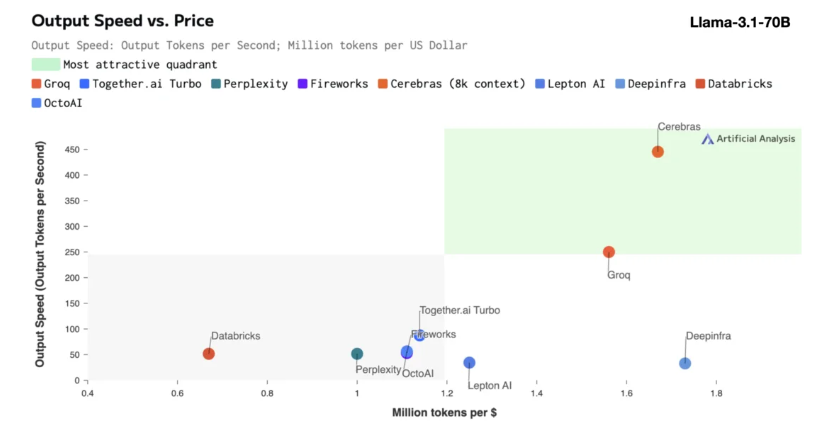
Cerebras推理特别适合处理各类 AI 模型,尤其是快速发展的 “大语言模型”(LLMs)。以最新的 Llama3.1模型为例,其8B 版本每秒可以处理1800个 token,而70B 版本则为450个 token。这一速度不仅是 NVIDIA GPU 解决方案的20倍,而且价格也更具竞争力。CerebrasInference的定价起步仅为每百万个 token10美分,70B 版本则为60美分,相较于现有 GPU 产品,性价比提升了100倍。
令人印象深刻的是,Cerebras Inference在保持行业领先准确度的同时,实现了这样的速度。与其他以速度为先的方案不同,Cerebras始终保持在16位数域内进行推理,确保性能提升不会以牺牲 AI 模型输出质量为代价。人工分析公司的首席执行官米哈・希尔 - 史密斯表示,Cerebras 在 Meta 的 Llama3.1模型上达到了超越1,800个输出 token 每秒的速度,创造了新记录。
AI 推理是 AI 计算中增长最快的部分,约占整个 AI 硬件市场的40%。高速度的 AI 推理,如Cerebras 所提供的,犹如宽带互联网的出现,打开了新的机会,为 AI 应用迎来了新纪元。开发者们可以借助CerebrasInference来构建需要复杂实时性能的下一代 AI 应用,如智能代理和智能系统。
Cerebras Inference提供了三个定价合理的服务层次:免费层、开发者层和企业层。免费层提供 API 访问,使用限制慷慨,非常适合广泛用户。开发者层则提供灵活的无服务器部署选项,企业层则针对持续负载的组织提供定制服务和支持。
核心技术上,Cerebras Inference采用的是CerebrasCS-3系统,由业界领先的 Wafer Scale Engine3(WSE-3)驱动。这个 AI 处理器在规模和速度上都无与伦比,提供了比 NVIDIA H100多7000倍的内存带宽。
Cerebras Systems不仅在 AI 计算领域中引领潮流,还在医疗、能源、政府、科学计算和金融服务等多个行业中扮演着重要角色。通过不断推进技术创新,Cerebras正在帮助各个领域的组织应对复杂的 AI 挑战。
划重点:
Cerebras Systems服务速度提升20倍,价格更具竞争力,开启 AI 推理新纪元。
支持各类 AI 模型,特别是在大语言模型(LLMs)上表现卓越。
提供三种服务层次,方便开发者和企业用户灵活选择。
总而言之,Cerebras Inference 的出现标志着 AI 推理领域的一个重要里程碑,其卓越的性能和经济性将推动 AI 应用的广泛普及和创新发展,值得业界关注和期待!Downcodes小编将持续为您带来更多科技前沿资讯。