近年来,人工智能技术的飞速发展严重依赖于海量数据的训练。然而,Downcodes小编发现,MIT等机构的最新研究指出,获取数据的难度正在急剧增加。曾经轻易可得的网络数据,如今正受到越来越严格的限制,这给AI的训练和发展带来了巨大的挑战。该研究对多个开源数据集进行了分析,揭示了这一严峻的现实。
在人工智能的高速发展背后,一个严峻的问题正浮出水面——数据获取的难度正日益增加。MIT等机构的最新研究发现,曾经轻易获取的网页数据,现在正变得越发难以访问,这对AI的训练和研究构成了重大挑战。
研究人员发现,多个开源数据集如C4、RefineWeb、Dolma等,它们所爬取的网站正在迅速收紧其许可协议。这不仅影响商业AI模型的训练,也对学术和非营利组织的研究造成了阻碍。

这项研究由来自MIT Media Lab、Wellesley学院、AI初创公司Raive等机构的4位团队主管共同进行。他们指出,数据的限制正在激增,且许可的不对称性与不一致性问题日益凸显。
研究团队使用了机器人排除协议(Robots Exclusion Protocol, REP)和网站的服务条款(Terms of Service, ToS)作为研究方法。他们发现,即使是OpenAI这样的大型AI公司的爬虫,也面临着越来越严格的限制。
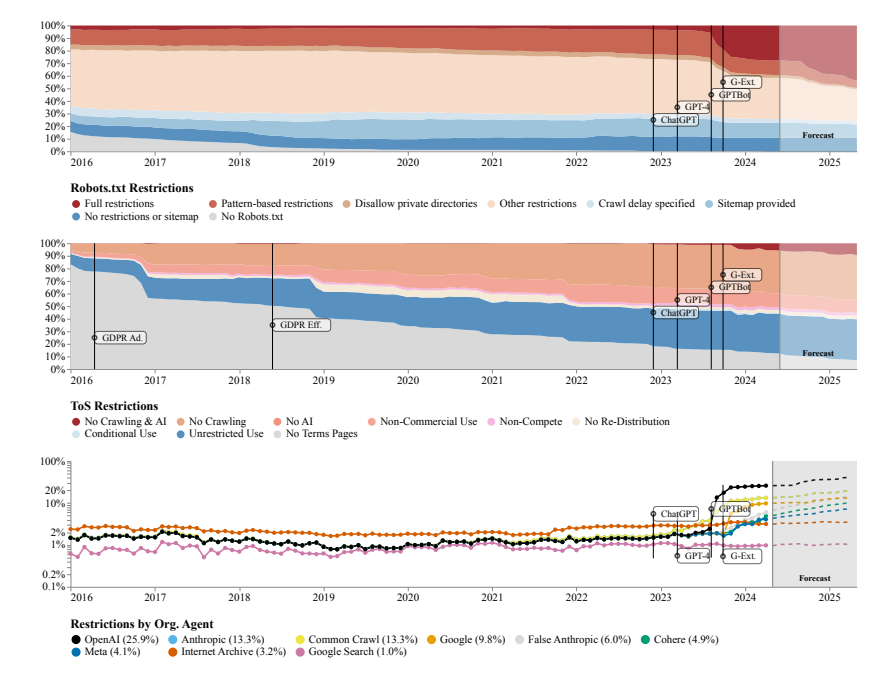
通过SARIMA模型预测,未来无论是通过robots.txt还是ToS,网站对数据的限制都将持续增加。这表明,开放网络数据的获取将变得更加困难。
研究还发现,网络上爬取的数据与AI模型的训练用途并不一致,这对模型对齐、数据收集实践以及版权都可能造成影响。
研究团队呼吁需要更灵活的协议来反映网站所有者的意愿,将有许可和不被允许的用例分开,并与服务条款同步。同时,他们希望AI开发人员能够使用开放网络上的数据进行训练,并希望未来的法律能够支持这一点。
论文地址:https://www.dataprovenance.org/Consent_in_Crisis.pdf
这项研究对人工智能领域的数据获取问题敲响了警钟,也为未来AI模型的训练和发展提出了新的挑战。如何平衡数据获取与网站所有者权益,将成为人工智能领域需要认真思考和解决的关键问题。Downcodes小编建议关注该论文,了解更多细节。