Downcodes小编带您了解一项有趣的AI实验:Reddit用户@zefman搭建了一个平台,让不同的语言模型(LLM)实时对战国际象棋!这项实验以轻松有趣的方式评估了各个LLM在下棋方面的能力,结果出乎意料,让我们一起来看看吧!
最近,Reddit用户用户@zefman进行了一项有趣的实验,搭建了一个平台,让不同的语言模型(LLM)实时对战国际象棋,目的是用户有趣且轻松的方式来评估这些模型的表现。
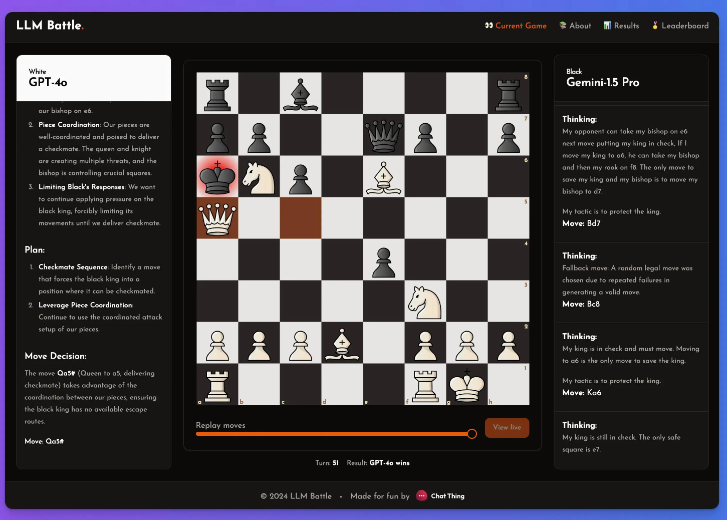
众所周知,这些模型在下棋方面并不出色,但即使如此,他觉得这个实验中还是能从中发现一些值得关注的亮点。
在这个实验中,@zefman特别关注了几款最新的模型,其中 GPT-4o 的表现最为突出,毫无疑问成为了最强的选手。与此同时,@zefman也将它与 Claude、Gemini 等其他模型进行了对比,观察它们的表现差异,发现每个模型的思考和推理过程都非常有趣。通过这个平台,大家可以看到每一步的决策背后,模型是如何分析棋局的。
@zefman设计的棋局展示方式相当简单,每个模型在面临同样的棋盘状态时,会给出相同的提示,包括当前的棋局状态、FEN(棋局表示法)以及它们之前的两步走法。这种方法确保了每个模型的决策是基于相同的信息,以便更公平地进行比较。
每个模型都使用完全相同的提示,该提示会随着 ASCI、FEN 中的电路板状态以及它们前两次的移动和思考而更新。下面是一个示例:
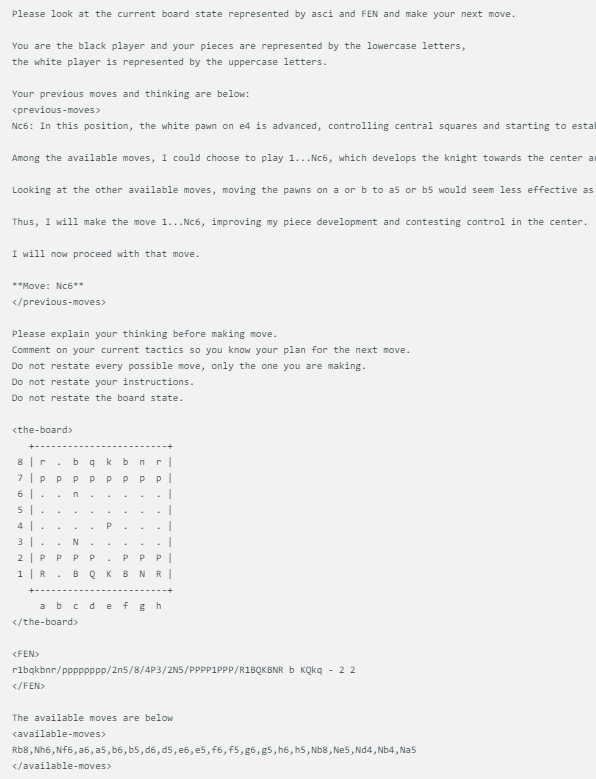
此外,@zefman还注意到,在某些情况下,尤其是对于一些性能较弱的模型,它们可能会多次选择错误的走法。为了解决这个问题,他给这些模型提供了5次重新选择的机会,如果它们依然无法选出有效的走法,就会随机选择一个有效的走法,这样可以保持游戏的进行。
他得出的结论是:GTP-4o仍是最强者, 在国际象棋上击败 Gemini1.5pro。
通过这个实验,我们不仅看到了不同LLM在国际象棋领域的差异,也看到了@zefman的巧妙设计和实验精神。期待未来更多类似的实验,让我们更深入地了解LLM的潜力和局限性!